







二叉查找树结构
二叉查找树又称二叉搜索树,顾名思义是为了快速查找而生。实际上还支持快速插入和快速删除。
二叉查找树要求:
在任意的一个节点中,其左子树的每个值,都要小于该节点的值,而其右子树的每个节点的 值都要大于该节点值。

二叉查找树的查询、插入、删除操作
二叉查找树-查找
思想:如果要在一个大的树中查找一个值x,先取根节点的值与x对比,如果x=根节点的值,则返回根节点值。如果x<根节点的值,则在左子树中递归查找;如果x>根节点的值,则在右子树中递归查找。
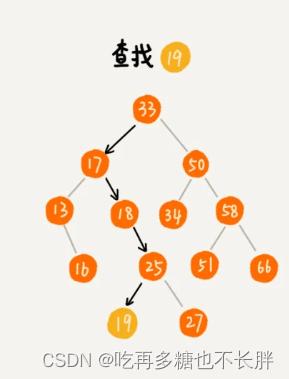
实现代码:
public static Node find(int data){
Node p = node33 ;
while (p !=null){
if (data == p.getData() ){
System.out.println(p.getData());
return p;
}else if (data < p.getData()){
System.out.println(p.getData());
p = p.getLeftNode();
}else {
System.out.println(p.getData());
p = p.getRightNode();
}
}
return null;
}
完整代码:
package Learn;
import java.util.Queue;
import java.util.concurrent.LinkedBlockingDeque;
public class tree {
static Node node19 = new Node(19,null,null);
static Node node27 = new Node(27,null,null);
static Node node16 = new Node(16,null,null);
static Node node25 = new Node(25,node19,node27);
static Node node51 = new Node(51,null,null);
static Node node66 = new Node(66,null,null);
static Node node13 = new Node(13,null,node16);
static Node node18 = new Node(18,null,node25);
static Node node34 = new Node(34,null,null);
static Node node58 = new Node(58,node51,node66);
static Node node17 = new Node(17,node13,node18);
static Node node50 = new Node(50,node34,node58);
static Node node33 = new Node(33,node17,node50);
public static void main(String[] args) {
Node node = find(27);
System.out.println(node.getData());
}
public static Node find(int data){
Node p = node33 ;
while (p !=null){
if (data == p.getData() ){
System.out.println(p.getData());
return p;
}else if (data < p.getData()){
System.out.println(p.getData());
p = p.getLeftNode();
}else {
System.out.println(p.getData());
p = p.getRightNode();
}
}
return null;
}
class Node{
private int data;
private Node leftNode;
private Node rightNode;
public Node(int data, Node leftNode, Node rightNode) {
this.data = data;
this.leftNode = leftNode;
this.rightNode = rightNode;
}
public int getData() {
return data;
}
public void setData(int data) {
this.data = data;
}
public Node getLeftNode() {
return leftNode;
}
public void setLeftNode(Node leftNode) {
this.leftNode = leftNode;
}
public Node getRightNode() {
return rightNode;
}
public void setRightNode(Node rightNode) {
this.rightNode = rightNode;
}
}
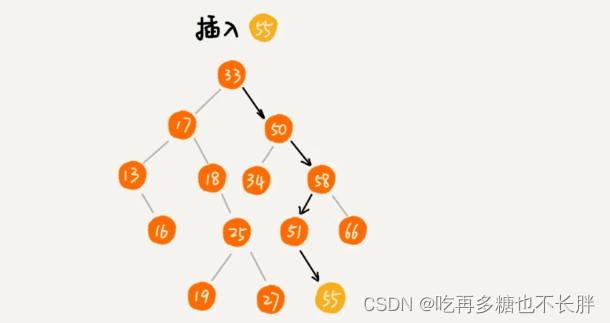
二叉查找树-插入
二叉查找树插入数据跟查找类似。
思想:
首先确认二叉查找树不插入在树已存在的数据。假如要插入的数据x在树中不存在,且插入的数据比根节点大,如果根节点右子节点为空,则插入右子节点中,如果不为空,则递归遍历右子树,查找插入位置。同理如果要插入的数据x比根节点小,且根节点左子节点为空,则插入到左子节点中,否则递归遍历左子树,查找插入位置。
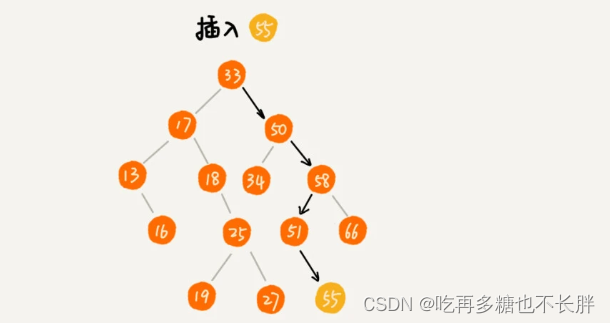
主要实现代码:
public static void insertNode(int data){
Node p = node33;
if (p == null){
node33 = new Node(data,null,null);
}
while (p != null){
if (data > p.getData()){
if (p.rightNode==null){
p.rightNode = new Node(data,null,null);
return;
}
p = p.rightNode;
}else {
if (p.leftNode==null){
p.leftNode = new Node(data,null,null);
return;
}
p = p.leftNode;
}
}
}
完整代码:
package Learn;
import java.util.Queue;
import java.util.concurrent.LinkedBlockingDeque;
public class tree {
static Node node19 = new Node(19,null,null);
static Node node27 = new Node(27,null,null);
static Node node16 = new Node(16,null,null);
static Node node25 = new Node(25,node19,node27);
static Node node51 = new Node(51,null,null);
static Node node66 = new Node(66,null,null);
static Node node13 = new Node(13,null,node16);
static Node node18 = new Node(18,null,node25);
static Node node34 = new Node(34,null,null);
static Node node58 = new Node(58,node51,node66);
static Node node17 = new Node(17,node13,node18);
static Node node50 = new Node(50,node34,node58);
static Node node33 = new Node(33,node17,node50);
public static void main(String[] args) {
insertNode(55);
System.out.println(node51.getRightNode().getData());
}
public static void insertNode(int data){
Node p = node33;
if (p == null){
node33 = new Node(data,null,null);
}
while (p != null){
if (data > p.getData()){
if (p.rightNode==null){
p.rightNode = new Node(data,null,null);
return;
}
p = p.rightNode;
}else {
if (p.leftNode==null){
p.leftNode = new Node(data,null,null);
return;
}
p = p.leftNode;
}
}
}
}
class Node{
public int data;
public Node leftNode;
public Node rightNode;
public Node(int data, Node leftNode, Node rightNode) {
this.data = data;
this.leftNode = leftNode;
this.rightNode = rightNode;
}
public int getData() {
return data;
}
public void setData(int data) {
this.data = data;
}
public Node getLeftNode() {
return leftNode;
}
public void setLeftNode(Node leftNode) {
this.leftNode = leftNode;
}
public Node getRightNode() {
return rightNode;
}
public void setRightNode(Node rightNode) {
this.rightNode = rightNode;
}
}
二叉查找树-删除
删除操作比较麻烦,分三种情况
1、要删除的节点没有子节点,直接将该节点的父节点要指向该节点的指针置为null即可。
2、要删除的节点只有一个子节点(左或右),只需要更新父节点原本指向该节点的指针置为该节点的子节点即可。
3、要删除的节点有两个节点,需要找到该节点右子树上最小的节点,然后把最小节点替换到要删除的节点,再删除这个最小节点。
实现代码
public class tree {
static Node node19 = new Node(19,null,null);
static Node node27 = new Node(27,null,null);
static Node node55 = new Node(55,null,null);
static Node node15 = new Node(15,null,null);
static Node node17 = new Node(17,null,null);
static Node node25 = new Node(25,node19,node27);
static Node node51 = new Node(51,null,node55);
static Node node66 = new Node(66,null,null);
static Node node13 = new Node(13,null,node15);
static Node node18 = new Node(18,node17,node25);
static Node node34 = new Node(34,null,null);
static Node node58 = new Node(58,node51,node66);
static Node node16 = new Node(16,node13,node18);
static Node node50 = new Node(50,node34,node58);
static Node node33 = new Node(33,node16, node50);
public static void main(String[] args) {
deletNode(55);
System.out.println(node51.getRightNode().getData());
}
public static void deletNode(int data){
Node p =null; //要删除的节点
Node pp = null;//要删除的节点的父节点
p = node33; //指向根节点,遍历根节点找到要删除的节点
while (p != null && p.data != data){
pp = p;
if (data > p.data) {
p = p.rightNode;
}else p=p.leftNode;
}// while循环后找到了要删除的p电
if (p==null) return;; //如果找不到就返回
//此时p是要删除的节点,pp是此节点的父节点,
// 如果被删除的节点有两个子节点,就把要删除的节点数据替换该节点右子树最小的值,
// 替换后要删除最小节点的原来节点,
// 因为最小的值肯定是没有左子节点的(即可能存在一个右子节点,或者没有子节点)。
// 所以要把这个问题降维成了(被删除节点最多只有一个子节点的问题)
if (p.leftNode !=null && p.rightNode !=null){
Node minp = p.rightNode;
Node minpp= p;
//当min的左子节点为null的时候,此时minp是最小的
while (minp.leftNode !=null){
minpp = minp;
minp = minpp.leftNode;
}
p.data = minp.data;
//即把p节点的值替换成其最小右节点值后,把p定义成最小节点,最小节点是最多只存在一个子节点的,
// 然后可以按代码顺序被后面删除单子节电的代码删除
p = minp;
pp = minpp;
}
//p是要删除的节点,
//child主要是来缓存数据,例如p节点没有子节点,则child为null,如有左子节点,child=左子节点之类
Node child ;
if (p.leftNode !=null) child=p.leftNode;
else if (p.rightNode != null) child = p.rightNode;
else child=null;
//真正的要删除节点操作
//如果pp父节点是空,则代表p是根节点,根节点被删除后为null,对应上面的child=null
//如果p在pp的左节点或右节点,此时pp只有一个子节点,不管是左还是右,用child替换p即可
if (pp ==null) node33 = child;
else if(pp.rightNode == p) pp.rightNode=child;
else pp.leftNode=child;
}
}
class Node{
public int data;
public Node leftNode;
public Node rightNode;
public Node(int data, Node leftNode, Node rightNode) {
this.data = data;
this.leftNode = leftNode;
this.rightNode = rightNode;
}
public int getData() {
return data;
}
public void setData(int data) {
this.data = data;
}
public Node getLeftNode() {
return leftNode;
}
public void setLeftNode(Node leftNode) {
this.leftNode = leftNode;
}
public Node getRightNode() {
return rightNode;
}
public void setRightNode(Node rightNode) {
this.rightNode = rightNode;
}
}
实际上还有一种更简单的方法:只是将要删除的节点标记为“删除”,但是不进行真正意义上的删除操作。这样原本要删除的节点还存储在内存中,但是删除操作就变的简单。
二叉查找树-快速查找最大节点和最小节点
先找到根节点,因为二叉查找树左边是比根节点小的左子树,根节点左边是比根节点大的右子树,所以可以在查找最大节点时,判定根节点有没有右子树,没有的话根节点就是最大的,然后遍历右子树,找到最后一个节点的右节点为null的节点。找最小节点也一样。
public class tree {
static Node node19 = new Node(19,null,null);
static Node node27 = new Node(27,null,null);
static Node node55 = new Node(55,null,null);
static Node node15 = new Node(15,null,null);
static Node node17 = new Node(17,null,null);
static Node node25 = new Node(25,node19,node27);
static Node node51 = new Node(51,null,node55);
static Node node66 = new Node(66,null,null);
static Node node13 = new Node(13,null,node15);
static Node node18 = new Node(18,node17,node25);
static Node node34 = new Node(34,null,null);
static Node node58 = new Node(58,node51,node66);
static Node node16 = new Node(16,node13,node18);
static Node node50 = new Node(50,node34,node58);
static Node node33 = new Node(33,node16, node50);
public static void main(String[] args) {
Node max = findMax();
System.out.println(max.getData());
Node min = findMin();
System.out.println(min.getData());
}
public static Node findMax(){
Node p = node33;
while (p !=null){
if (p.rightNode == null){
return p;
}else {
p = p.rightNode;
}
}
return null;
}
public static Node findMin(){
Node p = node33;
while (p != null){
if (p.leftNode == null){
return p;
}else {
p = p.leftNode;
}
}
return null;
}
}
class Node{
public int data;
public Node leftNode;
public Node rightNode;
public Node(int data, Node leftNode, Node rightNode) {
this.data = data;
this.leftNode = leftNode;
this.rightNode = rightNode;
}
public int getData() {
return data;
}
public void setData(int data) {
this.data = data;
}
public Node getLeftNode() {
return leftNode;
}
public void setLeftNode(Node leftNode) {
this.leftNode = leftNode;
}
public Node getRightNode() {
return rightNode;
}
public void setRightNode(Node rightNode) {
this.rightNode = rightNode;
}
}
支持重复数据的二叉查找树
在实际中,二叉查找树存储的是一个包含很多自动的对象,利用对象的某个字段作为key值构建二叉查找树,剩余其他字段称为卫星字段。
那么二叉查找树如何存储两个key相同的对象呢,有两种方法:
1、通过链表或者数组等容易扩容的结构,把相同key值的数据存储在同一个节点。
2、每个节点存储一个数据,但是在插入数据的时候,如果插入的数据与一个节点的数据相同,那就把这个数据插入到这个节点的右子树,把这个数据当作大于这个节点数据来处理。
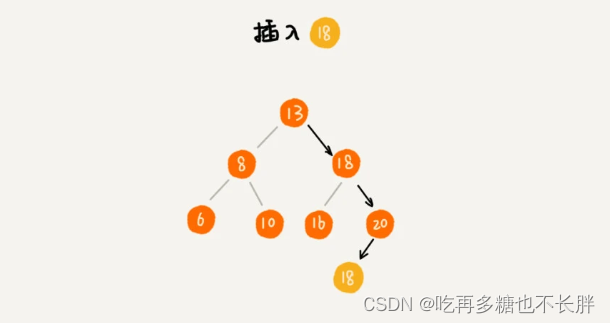
但是这样处理后,遇到查找某个数据操作时,当查找到与值相同的节点时,此时并不能停止查询,仍需要继续查找右子树,直至遇到叶子节点为止。这样才能把所有相同值的所有结点查找出来。
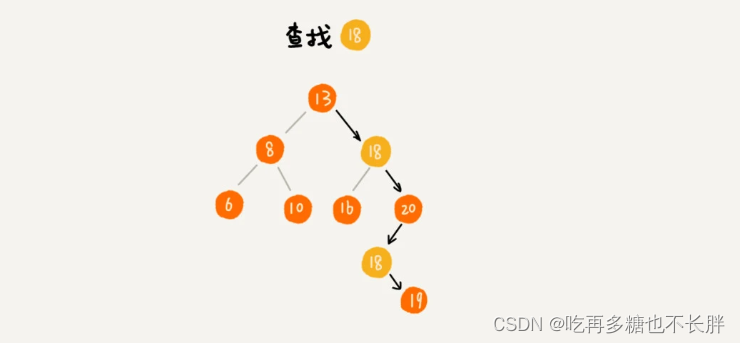
对于删除操作,按正常操作删除即可,依次删除。
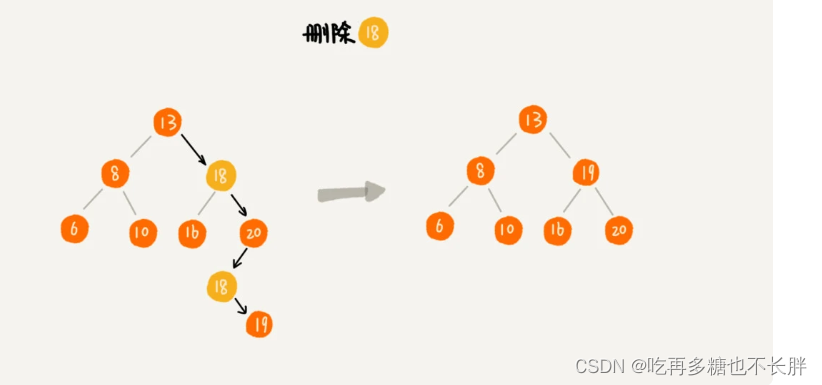
二叉查找树的时间复杂度分析
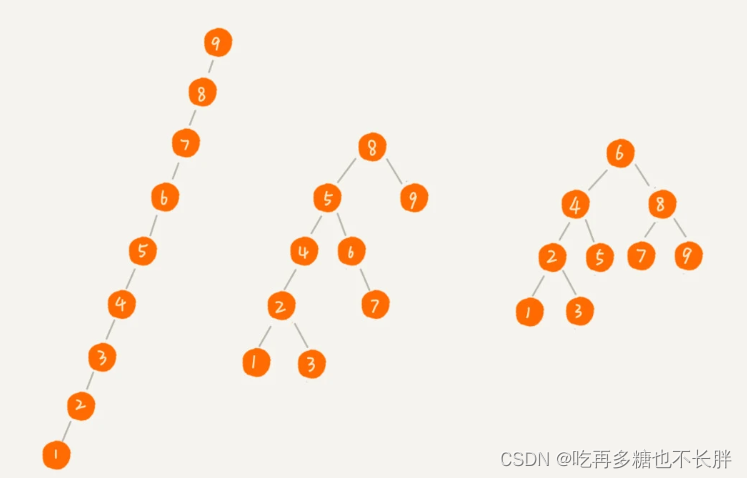
在极端条件下,例如上面的第一种情况,二叉树已经退化成链表结构,这是最糟糕的情况,此时时间复杂度是O(n)。
从图中来看,操作不管是查询还是插入、删除,时间复杂度都跟树的高度有关,成正比关系,即O(height)。
那么完全二叉树的高度怎么求?
假设完全二叉树的结点总数为n,最大层数是L。
L=1 的时候共有节点2 1 - 1 个, L =2的时候共有节点 22 -1 个,L=3的时候共有节点23 -1 个,所以是满二叉树的时候L层满二叉树共有2L-1 个节点,前面L-1层共有2L-1 -1个 ,而L层的完全二叉树最后一层子节点是不满的,最少是1个,最多是2 L-1个,所以L层的完全二叉树共有节点(2L-1 -1) +1 <= n <= (2L -1),得出L的范围是[log2(n+1),log2n +1],所以L层数小于等于log2n +1,因为高度H=L-1,所以高度H小于等于log2n 。
散列表和二叉查询树
散列表的删除、查询、插入时间复杂度都可以做到O(1),而二叉查找树只能做到O(logN),两者对比散列表更有优势,但是为什么在别的场景还用二叉查找树呢
1、散列表的数据是无需的,在需要输出有序数据的时候,需要重新排序,而二叉查找树只需中序遍历即可在O(n)的时间复杂度内输出有序数据。
2、散列表扩容耗时多,遇到散列冲突时,性能不稳定。二叉查找树性能也不稳定,但是常用的平衡二叉查找树的性能是非常稳定的,时间复杂度是O(logN)
3、散列表正常情况查找的时间复杂度是常量级别O(1)的,但是因为散列冲突,导致这个常量不一定比logN小。所以查找速度不一定比O(logN)快。同时哈希函数的耗时,也不一定比平衡二叉查找树效率高。
4、散列表的构造比二叉查找树复杂,需要考虑很多,例如散列函数设计、散列冲突 的解决,扩容、缩容等。而平衡二叉树只考虑平衡性一个问题即可。
5、因为散列表的装载因子过大时,散列冲突发生的概率越高。所以希望装载因子平衡在一个相对比较小的状况,要维持这种情况,占用的内存就会很高,这部分内存是被浪费掉的。
二者对比有好有坏,需要在不同场景下根据不同需求使用。















 1118
1118











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









