







研究背景与意义
研究背景与意义
随着城市化进程的加快和人口的增加,垃圾处理问题日益严重,成为全球范围内亟待解决的环境问题之一。根据联合国环境规划署的报告,全球每年产生的垃圾量已超过20亿吨,其中可回收物品的比例相对较高。有效的垃圾分类不仅可以减少填埋场的负担,还能促进资源的循环利用,降低环境污染。因此,建立高效的垃圾分类检测系统显得尤为重要。
近年来,深度学习技术在计算机视觉领域取得了显著进展,尤其是目标检测算法的快速发展为垃圾分类提供了新的解决方案。YOLO(You Only Look Once)系列算法因其高效性和实时性,成为目标检测任务中的热门选择。YOLOv11作为该系列的最新版本,结合了更为先进的特征提取和分类技术,能够在复杂环境中实现高精度的目标检测。然而,针对垃圾分类的特定需求,YOLOv11仍需进行改进,以适应不同种类垃圾的检测。
本研究基于改进的YOLOv11模型,旨在构建一个高效的垃圾分类检测系统。所使用的数据集Trash500包含2800张图像,涵盖玻璃、金属、纸张和塑料四类垃圾。这一数据集不仅提供了丰富的样本,还经过精细的标注,适合用于训练和评估深度学习模型。通过对YOLOv11的改进,期望提升其在垃圾分类任务中的检测精度和速度,从而为实际应用提供技术支持。
综上所述,研究基于改进YOLOv11的垃圾分类检测系统具有重要的现实意义,不仅可以推动智能垃圾分类技术的发展,还能为环境保护和资源回收利用贡献力量。
图片演示
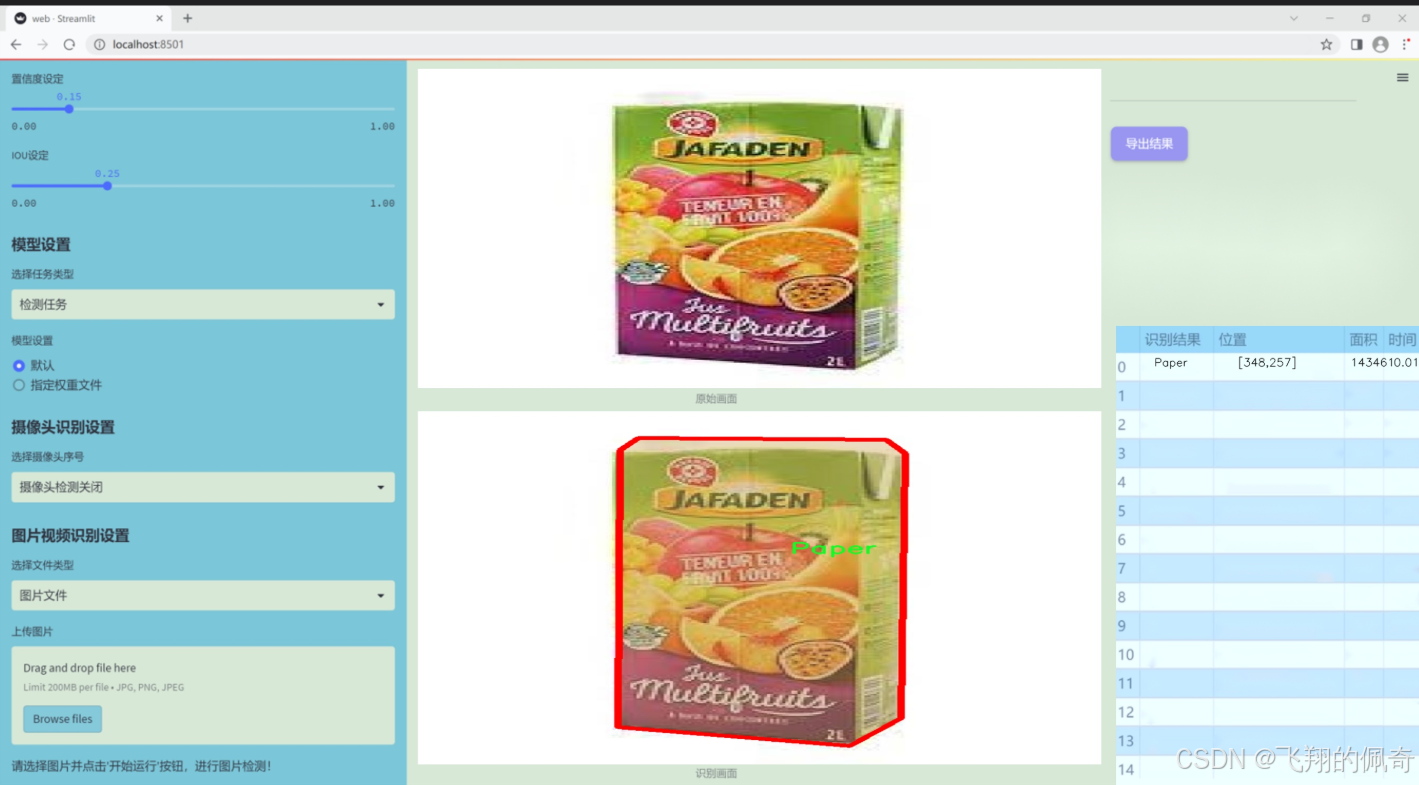
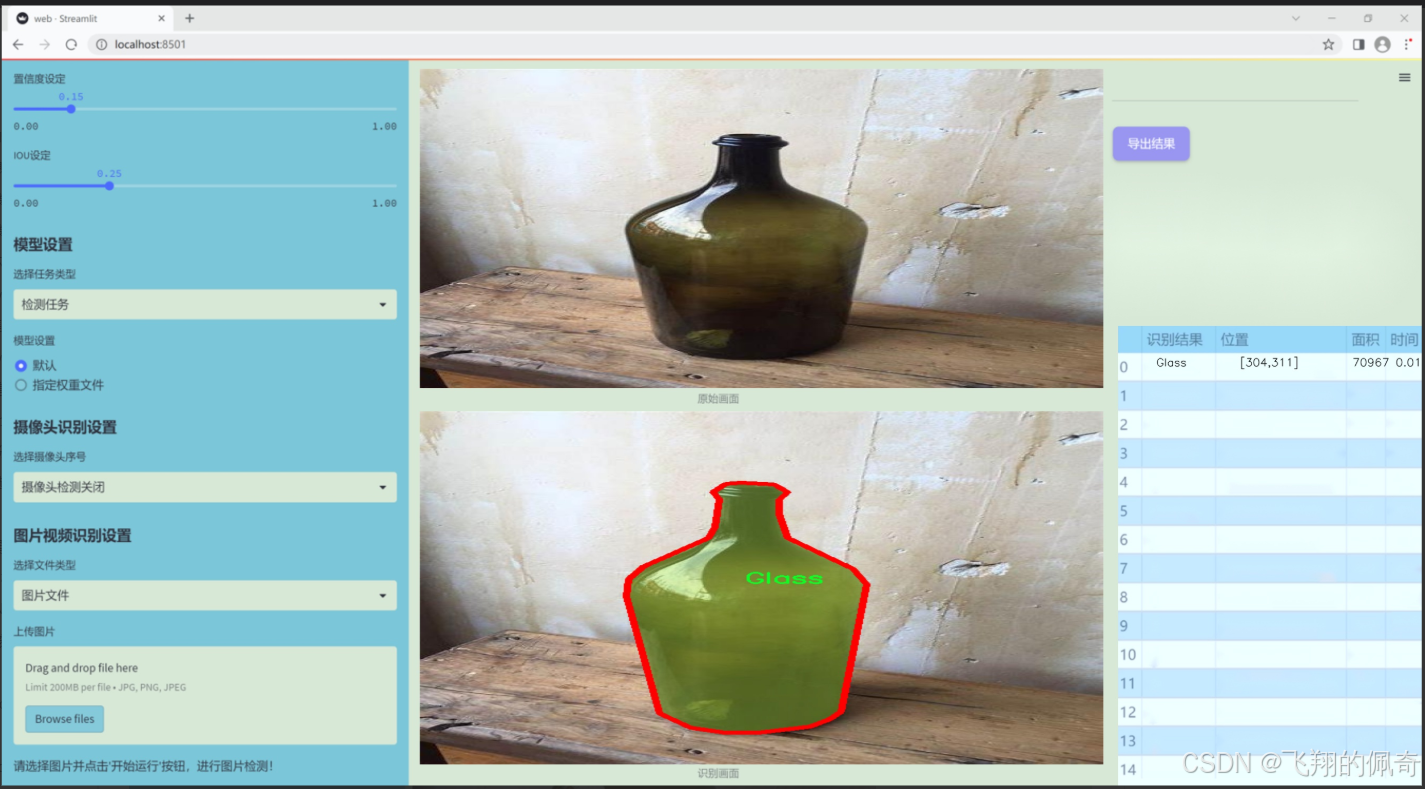
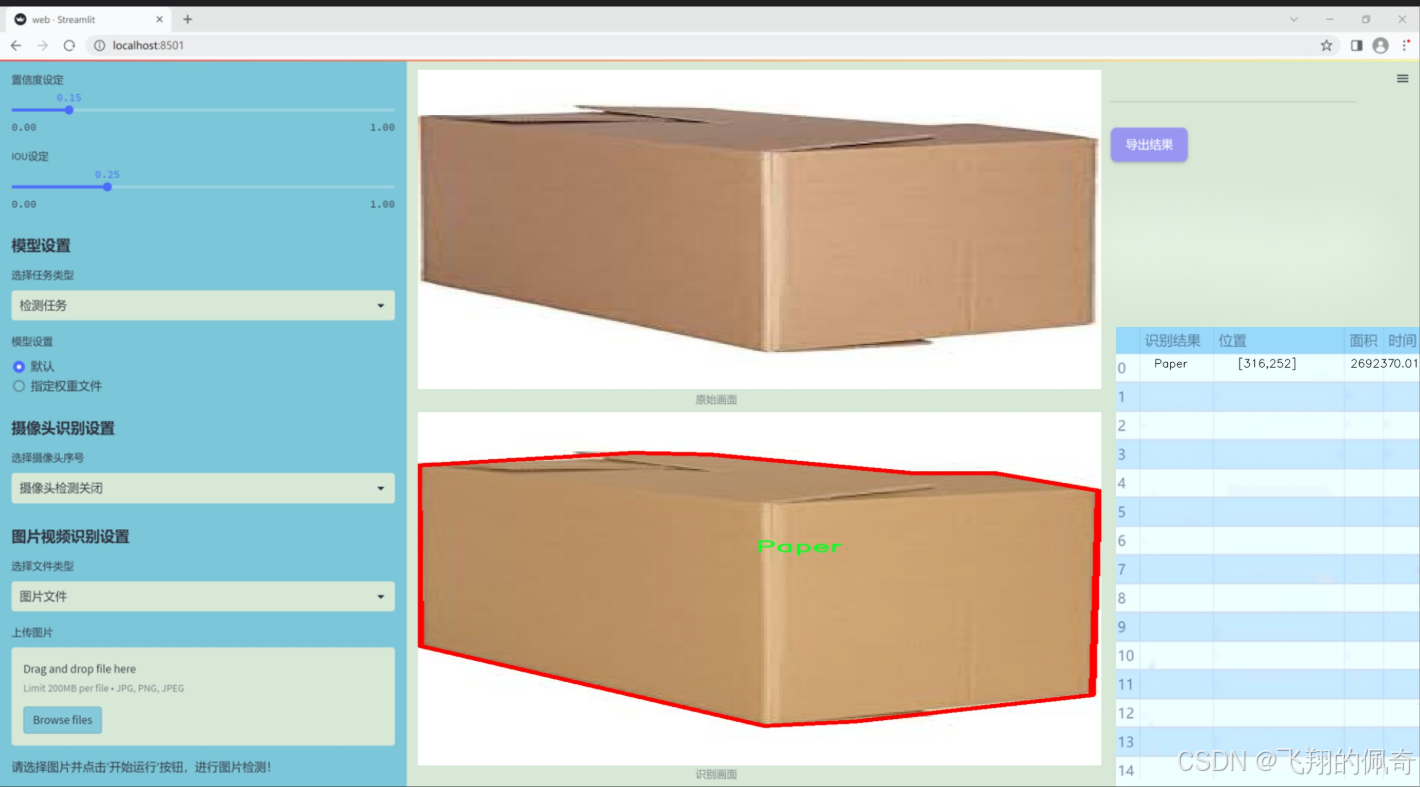
数据集信息展示
本项目数据集信息介绍
本项目所使用的数据集名为“Trash500”,旨在为改进YOLOv11的垃圾分类检测系统提供高质量的训练数据。该数据集专注于四种主要的垃圾分类类别,分别是玻璃、金属、纸张和塑料。这四类垃圾在日常生活中极为常见,且各自的回收处理方式和环境影响显著不同,因此,准确识别和分类这些垃圾对于推动可持续发展和环境保护具有重要意义。
“Trash500”数据集包含丰富的图像样本,涵盖了各种不同形态、颜色和尺寸的垃圾物品,以确保模型在训练过程中能够学习到多样化的特征。这些图像不仅包括单一物品的特写,还涵盖了多个物品的组合场景,以模拟真实环境中的垃圾分类情境。通过这种方式,数据集能够有效提高模型的泛化能力,使其在实际应用中能够更好地应对各种复杂情况。
在数据集的构建过程中,特别注重数据的标注质量和准确性。每一张图像都经过严格的标注,确保每个类别的物品都能被清晰地识别和分类。此外,为了增强模型的鲁棒性,数据集还引入了数据增强技术,包括旋转、缩放、翻转等操作,以生成更多的训练样本,从而提升模型的学习效果。
通过使用“Trash500”数据集,改进后的YOLOv11模型将能够更精准地识别和分类不同类型的垃圾,从而为智能垃圾分类系统的实现奠定坚实的基础。这不仅有助于提高垃圾分类的效率,也为推动社会的环保意识和可持续发展目标贡献一份力量。





项目核心源码讲解(再也不用担心看不懂代码逻辑)
以下是经过简化和注释的核心代码部分,主要保留了 ChannelTransformer 类及其相关组件的实现。
import torch
import torch.nn as nn
import numpy as np
from torch.nn import Dropout, LayerNorm
class Channel_Embeddings(nn.Module):
“”“从输入图像中构建通道嵌入,使用位置嵌入来增强特征表示。”“”
def init(self, patchsize, img_size, in_channels):
super().init()
# 计算图像的尺寸和补丁的尺寸
img_size = (img_size, img_size)
patch_size = (patchsize, patchsize)
n_patches = (img_size[0] // patch_size[0]) * (img_size[1] // patch_size[1])
# 使用卷积和池化构建补丁嵌入
self.patch_embeddings = nn.Sequential(
nn.MaxPool2d(kernel_size=5, stride=5),
nn.Conv2d(in_channels=in_channels, out_channels=in_channels, kernel_size=patchsize // 5, stride=patchsize // 5)
)
# 位置嵌入
self.position_embeddings = nn.Parameter(torch.zeros(1, n_patches, in_channels))
self.dropout = Dropout(0.1)
def forward(self, x):
"""前向传播,计算嵌入。"""
if x is None:
return None
x = self.patch_embeddings(x) # 计算补丁嵌入
x = x.flatten(2).transpose(-1, -2) # 调整维度
embeddings = x + self.position_embeddings # 加上位置嵌入
embeddings = self.dropout(embeddings) # 应用dropout
return embeddings
class Encoder(nn.Module):
“”“编码器,包含多个块,每个块执行自注意力和前馈网络。”“”
def init(self, vis, channel_num):
super(Encoder, self).init()
self.vis = vis
self.layer = nn.ModuleList()
for _ in range(1): # 这里可以调整层数
layer = Block_ViT(vis, channel_num)
self.layer.append(layer)
def forward(self, emb1, emb2, emb3, emb4):
"""前向传播,依次通过每个块进行处理。"""
for layer_block in self.layer:
emb1, emb2, emb3, emb4, _ = layer_block(emb1, emb2, emb3, emb4)
return emb1, emb2, emb3, emb4
class ChannelTransformer(nn.Module):
“”“通道变换器,整合多个通道的特征并进行编码。”“”
def init(self, channel_num=[64, 128, 256, 512], img_size=640, vis=False, patchSize=[40, 20, 10, 5]):
super().init()
# 初始化嵌入层
self.embeddings_1 = Channel_Embeddings(patchSize[0], img_size // 8, channel_num[0])
self.embeddings_2 = Channel_Embeddings(patchSize[1], img_size // 16, channel_num[1])
self.embeddings_3 = Channel_Embeddings(patchSize[2], img_size // 32, channel_num[2])
self.embeddings_4 = Channel_Embeddings(patchSize[3], img_size // 64, channel_num[3]) if len(channel_num) == 4 else nn.Identity()
# 初始化编码器
self.encoder = Encoder(vis, channel_num)
def forward(self, en):
"""前向传播,计算嵌入并通过编码器处理。"""
if len(en) == 3:
en1, en2, en3 = en
en4 = None
elif len(en) == 4:
en1, en2, en3, en4 = en
# 计算嵌入
emb1 = self.embeddings_1(en1) if en1 is not None else None
emb2 = self.embeddings_2(en2) if en2 is not None else None
emb3 = self.embeddings_3(en3) if en3 is not None else None
emb4 = self.embeddings_4(en4) if en4 is not None else None
# 通过编码器处理嵌入
encoded1, encoded2, encoded3, encoded4, _ = self.encoder(emb1, emb2, emb3, emb4)
# 重新构建输出
x1 = encoded1 + en1 if en1 is not None else None
x2 = encoded2 + en2 if en2 is not None else None
x3 = encoded3 + en3 if en3 is not None else None
x4 = encoded4 + en4 if en4 is not None else None
return [x1, x2, x3, x4]
class GetIndexOutput(nn.Module):
“”“根据索引获取输出。”“”
def init(self, index):
super().init()
self.index = index
def forward(self, x):
"""根据指定索引返回输出。"""
return x[self.index]
代码说明
Channel_Embeddings: 该类负责将输入图像分割成补丁并计算嵌入,同时添加位置嵌入以保留空间信息。
Encoder: 该类包含多个编码块,每个块执行自注意力机制和前馈网络的操作。
ChannelTransformer: 该类整合了多个通道的特征,使用嵌入层和编码器进行处理,最终返回增强后的特征。
GetIndexOutput: 该类用于根据给定的索引提取特定的输出。
通过这些类的组合,构建了一个通道变换器模型,可以用于处理图像数据并提取特征。
这个程序文件 CTrans.py 实现了一个名为 ChannelTransformer 的深度学习模型,主要用于图像处理任务。该模型结合了通道注意力机制和变换器(Transformer)架构,能够对输入图像进行有效的特征提取和重建。
首先,文件导入了一些必要的库,包括 PyTorch 及其模块、NumPy 和其他工具。程序中定义了多个类,每个类实现了模型的不同部分。
Channel_Embeddings 类负责从输入图像中提取补丁和位置嵌入。它通过最大池化和卷积操作将输入图像分割成多个补丁,并为每个补丁生成位置嵌入。最终,这些嵌入通过 dropout 层进行正则化。
Reconstruct 类用于重建图像。它将输入的嵌入进行升采样,并通过卷积层进行处理,以恢复到原始图像的尺寸。该类使用了批归一化和 ReLU 激活函数。
Attention_org 类实现了多头注意力机制。它为不同的输入通道生成查询、键和值,通过计算注意力分数来聚合信息。该类还支持可视化注意力权重,并使用 dropout 进行正则化。
Mlp 类实现了一个简单的多层感知机(MLP),包含两个全连接层和 GELU 激活函数。它用于在模型中进行特征转换。
Block_ViT 类是变换器的一个基本模块,包含了注意力层和前馈网络。它通过层归一化和残差连接来增强信息流动。
Encoder 类由多个 Block_ViT 组成,负责对输入的嵌入进行编码。它在每个块之后应用层归一化,并可选地记录注意力权重。
ChannelTransformer 类是整个模型的核心,初始化了多个嵌入层、编码器和重建层。它接收输入图像的不同通道,并将其转换为嵌入,经过编码器处理后再重建为输出图像。
最后,GetIndexOutput 类用于从模型的输出中提取特定索引的结果。
整体而言,这个程序文件实现了一个复杂的图像处理模型,结合了多种深度学习技术,旨在提高图像特征提取和重建的效果。
源码文件

源码获取
可以直接加我下方的微信哦!



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











