







1--前言
原论文:All are Worth Words: A ViT Backbone for Diffusion Models
完整可debug的代码:Simple_U-ViT
2--结构
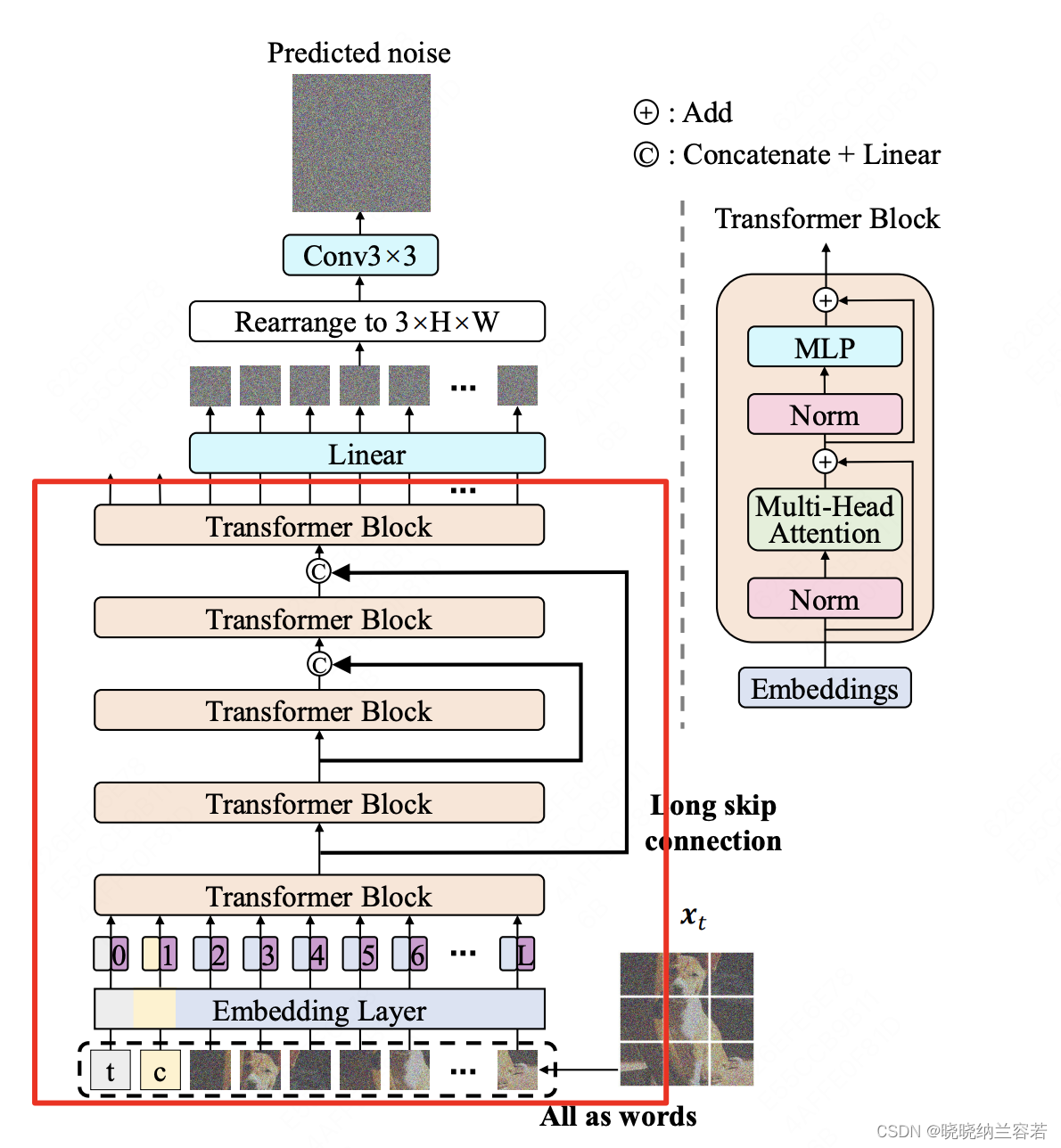
3--简单代码
以视频作为输入,实现上图红色框的计算:
import torch
import torch.nn as nn
from einops import rearrange
class PatchEmbedding(nn.Module):
def __init__(self, in_channels = 3, patch_size = 16, emb_dim = 768):
super().__init__()
self.patch_size = patch_size
# 由于是视频作为输入,因此使用Conv3d
self.proj = nn.Conv3d(in_channels = in_channels, out_channels = emb_dim, kernel_size = (1, patch_size, patch_size), stride = (1, patch_size, patch_size))
def forward(self, x):
# x.shape: [batch_size, channels, frames, height, width]
x = self.proj(x) # (batch_size, emd_dim, frames, height // patch_size, width // patch_size)
x = rearrange(x, 'b e t h w -> b (t h w) e') # flatten into patches
return x
class TransformerEncoder(nn.Module):
def __init__(self, emb_dim = 768, num_heads = 8, ff_dim = 1024, dropout = 0.1, skip = False):
super().__init__()
self.layernorm1 = nn.LayerNorm(emb_dim)
self.self_attn = nn.MultiheadAttention(embed_dim = emb_dim, num_heads = num_heads, dropout = dropout)
self.dropout1 = nn.Dropout(dropout)
self.layernorm2 = nn.LayerNorm(emb_dim)
self.ffn = nn.Sequential(
nn.Linear(emb_dim, ff_dim),
nn.ReLU(),
nn.Linear(ff_dim, emb_dim)
)
self.dropout2 = nn.Dropout(dropout)
if skip:
self.skip_linear = nn.Linear(2 * emb_dim, emb_dim)
def forward(self, x, skip = None):
# x.shape: [b, thw, c]
if(skip != None): # long skip connection
x = self.skip_linear(torch.cat([x, skip], dim=-1)) # [b, thw, 2c] -> [b, thw, c]
x2 = self.layernorm1(x) # norm
x2, _ = self.self_attn(x2, x2, x2) # attention
x = x + self.dropout1(x2) # skip
x2 = self.layernorm2(x) # norm
x2 = self.ffn(x2) # mlp
x = x + self.dropout2(x2) # skip
return x
class UViT(nn.Module):
def __init__(self, in_channels = 3, patch_size = 16, emb_dim = 768, depth = 5, num_heads = 8, ff_dim = 1024, dropout = 0.1):
super().__init__()
self.patch_embed = PatchEmbedding(in_channels, patch_size, emb_dim)
self.in_blocks = nn.ModuleList([
TransformerEncoder(emb_dim = emb_dim, num_heads = num_heads, ff_dim = ff_dim, dropout = dropout) for _ in range(depth // 2)
])
self.mid_block = TransformerEncoder(emb_dim = emb_dim, num_heads = num_heads, ff_dim = ff_dim, dropout = dropout)
self.out_blocks = nn.ModuleList([
TransformerEncoder(emb_dim = emb_dim, num_heads = num_heads, ff_dim = ff_dim, dropout = dropout, skip = True) for _ in range(depth // 2)
])
self.layernorm = nn.LayerNorm(emb_dim)
def forward(self, x): # [b, c, t, h, w]
x = self.patch_embed(x) # [b, t * (h//patch) * (w//patch), c']
skips = [] # 存储in_blocks的输出, 作为long skip, 本质上是一个栈(后进先出)
for blk in self.in_blocks:
x = blk(x)
skips.append(x)
x = self.mid_block(x)
for blk in self.out_blocks:
x = blk(x, skips.pop()) # 栈的pop,作为long skip
x = self.layernorm(x)
return x
if __name__ == "__main__":
batch_size = 2
in_channels = 3
frames = 8
height = 128
width = 128
video_tensor = torch.randn(batch_size, in_channels, frames, height, width).cuda() # 这里以视频作为输入,原论文是以图片作为输入
# depth 必须是奇数,因为Long skip connection的存在
model = UViT(in_channels = in_channels, patch_size = 16, emb_dim = 768, depth = 5, num_heads = 8, ff_dim = 1024, dropout = 0.1).cuda()
output = model(video_tensor)
print("output.shape: ", output.shape)















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









