






参考:https://gitee.com/darkranger/tiny-url.git
文章目录
1. 前提知识
1.1 什么是短连接
- 一般的连接非常的长,当将连接作为短信发送给用户的时候,短信的长度是有限制的,因此为了降低成本,需要缩短连接的长度
- 此外短连接能更容易让别人记住
核心原理:
将长连接通过“唯一性算法”转换为短字符串,并将映射关系存储到数据库当中,用户访问短连接的时候服务端通过短字符串查表,返回原始长连接并触发重定向。
1.2 如何为一个长连接创建出独一无二的短连接
为一个长连接创建出独一无二的短链接主要有两种
- 基于哈希算法(MD5、SHA-1)
- 步骤:
- 对长连接计算哈希值
- 将哈希值截取部分字符串(例如取前6位)
- 处理哈希冲突:如果生成的短连接已经存在,追加随机盐重新哈希
- 优点:实现简单,无序维护自增ID
- 缺点:可能会产生哈希冲突,需要额外处理
- 步骤:
- 自增ID+base62和base64两种编码方式
- 步骤:
- 为每条长链接分配一个唯一自增ID
- 将十进制ID转为Base62编码
- 短链格式:域名+转换结果
- 优点:无冲突,短链长度可控
- 缺点:需要维护自增id(分布式场景使用雪花算法等)
- 步骤:
1.2.1 Base62编码
1. Base62编码是什么
Base62编码是一种将数字转换为仅使用62个字符的字符串的编码方式。其核心目的是生成简短、无特殊符号的标识符,适用于URL短连接、资源ID等场景
2. Base62编码底层原理
Base62 使用一下62个字符(顺序需要统一,常见的有两种顺序)
- 顺序1: 0-9 、a-z、A-Z
- 顺序2: 0-9、A-Z、a-z
- 示例:
0123456789abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ
编码过程:将十进制转为62进制
解码过程:将62进制转为十进制
以字符串MAN为例解释编码过程
3. 应用场景
- 短连接生成:将自增ID转换为短字符串
- 资源标识符:生成无特殊符号的ID,便于在URL、文件名中使用
- 数据压缩:将大整数表示为更短的字符串
4. 优缺点分析
- 优点:
- 无特殊符号,适合URL和文件名
- 字符集友好,无需URL编码
- 实现简单,效率高 - 缺点:
- 相同数值下编码长度略长于Base64
- 如果编码结果需要定长的话,需要处理前导零
- 字符集顺序需要严格统一
1.2.2 Base64 编码
1. Base64 编码是什么
Base64 编码是一种将二进制数字编码为ASCII字符串的编码方式,主要用于在不支持二进制传输的环境中安全传递二进制内容。
2. Base64编码底层原理
核心原理:
- 目标:将任意二进制数据转换为可打印的文本字符
- 字符集:一共64 个字符(A-Z、a-z、0-9、+、-),外加填充符 =
- 编码规则:每3字节(24位)的二进制数据分割为4组6位的值,每组映射到Base64字符集的对应字符。若数据不足3字节,用= 填充。
以字符串Man为例解释编码过程
- Man的原始数据(ASCII码值)
'M' (77) → 01001101 'a' (97) → 01100001 'n' (110) → 01101110 - 分割为4组6位的值
010011 010110 000101 101110 19 22 5 46 编码结果:TWFu
3. Base64 编码应用场景
- 数据传输
- 在JSON、XML中嵌入二进制数据
- 通过HTTP GET请求传递二进制参数
- 存储协议
- 电子邮件附件
- 网页中内联图片
- 加密与编码
- 加密后的二进制结果需文本化传输(JWT令牌)
4. Base64编码优缺点分析
- 优点:
- 通用性强,支持所有二进制数据
- 可逆且标准化
- 实现简单,主流语言均内置支持
- 缺点:
- 编码后体积增加约33%
- 包含特殊符号(需URL编码处理)
- 肉眼不可读
1.2.3 Base62和 Base64 的区别,项目中使用的是哪一种编码方式,为什么
1. 首先是Base62和Base64的核心区别:
- 字符集:
- Base62的字符集是仅包含数字和大小写字母,没有特殊符号的
- Base64 的字符集除了数字和大小写字母之外还有特殊符号
+ / =
- 填充符:
- Base62 没有填充符
- Base64 当数据不足3字节的时候需要使用 = 进行填充
- URL安全性:
- Base62 的所有字符均无需URL编码,可以直接嵌入URL
- Base64 中的特殊字符
+ / =需要特殊处理
- 编码膨胀率:
- Base62的编码膨胀率更小一些
- 可读性
- Base62 编码没有特殊字符可读性更强
2. 为什么选择 Base62
短链接生成选择 Base62 的核心原因:
- URL安全:没有特殊字符,无需转义,直接嵌入。
- 简洁无冗余:无填充符,长度更短。
- 用户友好:纯字母数字,避免混淆。
- 实现简单:基于自增ID的进制转换即可保证唯一性。
1.2.4 插播解决哈希冲突的方法
1. 开放定址法(Open Addressing)
当发生哈希冲突时,在哈希表中寻找下一个可用的空槽位。
- 线性探测(Linear Probing)
冲突后依次检查下一个位置:(hash(key) + i) % table_size(i=1,2,3,…)。
优点:实现简单。
缺点:容易产生聚集(Clustering),导致查找效率下降。 - 二次探测(Quadratic Probing)
冲突后按二次方程探测:(hash(key) + i²) % table_size(i=1,2,3,…)。
优点:减少聚集现象。
缺点:可能无法找到空槽位(即使表未满)。 - 双重哈希(Double Hashing)
使用第二个哈希函数计算步长:(hash1(key) + i * hash2(key)) % table_size。
优点:探测步长分散,减少聚集。
缺点:需要设计第二个哈希函数。
2. 链地址法(Separate Chaining)
将哈希表的每个槽位(Bucket)设计为链表或其他数据结构,所有哈希到同一位置的元素存储在链表中。
- 优点:
- 简单易实现。
- 负载因子较高时仍能保持较好性能。 - 缺点:
- 需要额外内存存储链表指针。
- 极端情况下链表过长会退化为线性查找(时间复杂度 O(n))。
3. 再哈希法(Rehashing)
当发生冲突时,使用另一个哈希函数重新计算地址,直到找到空槽位。
- 优点:减少聚集现象。
- 缺点:需要设计多个哈希函数,计算成本较高。
4. 动态哈希表扩容
当哈希表的负载因子(已存元素数 / 总槽位数)超过阈值时,自动扩容并重新哈希所有元素。
- 负载因子阈值通常设为 0.7~0.75(如 Java HashMap)。
- 扩容后容量翻倍,减少后续冲突概率。
1.3 页面跳转
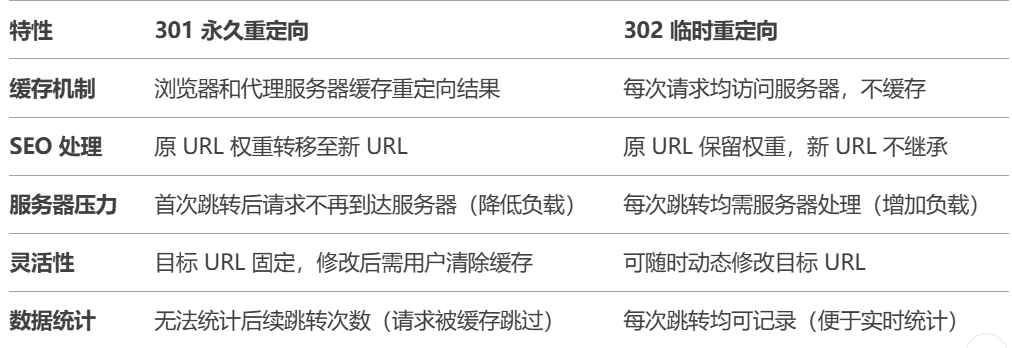
页面重定向主要有两种方式301重定向和302重定向本质上都会跳转到页面
1.3.1 301 重定向
301 是永久重定向,表示请求的资源已经永久迁移到新的URL;浏览器会缓存重定向结果,后续请求直接跳转到新UR,不在访问原来的短连接。搜索引擎会将元URL的权重转移到新URL,原链接可能被移出索引
应用场景有
- 网站域名更换(如 http://old.com → https://new.com)
- 永久性页面路径调整(如 /old-page → /new-page)
1.3.2 302 重定向
302是临时重定向,表示资源临时迁移到新的URL;浏览器每次访问原短连接都会想服务器发起请求,不缓存重定向结果;搜索引擎会保留原URL索引,不转移权重到新URL。
1.3.3 301 和 302 二者区别
1.3.4 项目中使用的是哪一种,为什么
项目中使用的是 302 重定向,
- 实时统计点击数据
- 短连接服务需要精准统计每次跳转的点击量、来源、设备等信息,若使用301,浏览器缓存会导致后续请求直接跳转,服务器无法记录数据;302强制每次跳转同经过服务器,确保每次点击均被记录。
- 灵活更新URL
- 短连接可能需要动态修改目标地址(如营销活动更换落地页);301的缓存特性会使用户长期访问旧地址,即使服务端已经更新;302允许服务端实时响应最新目标URL,确保跳转即时生效。
- 避免SEO权重转移
- 短连接本身无需被搜索引擎索引(它知识一个跳转工具,目标页才是核心),301会导致搜索引擎将短连接权重转移给目标页,可能干扰目标页SEO;302 保留短链接的独立性,不影响目标页的 SEO 策略。
- 防范恶意滥用
- 若短链接被用于传播恶意 URL,需能快速封禁;301 缓存后,用户可能继续访问恶意地址,即使服务端已拦截;302 每次跳转均校验服务端,可立即 禁用恶意短链。
1.4 雪花算法
在短链接生成器项目中,雪花算法(Snowflake Algorithm) 是一种用于生成 全局唯一且有序的分布式ID 的算法。
1.4.1 雪花算法核心原理
雪花算法生成的ID是一个 64位整数,通常由以下四部分组成:
- 符号位(1位):固定为0(保证ID为正数)。
- 时间戳(41位):记录生成ID的时间(精确到毫秒),可用约69年(从算法起始时间算起)。
- 机器ID(10位):支持最多 2^10 = 1024 台机器(或服务实例)同时生成ID。
- 序列号(12位):同一机器同一毫秒内的自增序号,支持每毫秒生成 2^12 = 4096 个唯一ID。
1.4.2 雪花算法在短链接项目中的作用(为什么使用雪花算法)
- 生成唯一短码的种子
- 需求:为每个长连接链接成唯一的短码
- 实现: 使用雪花算法生成全局唯一的数字ID,在通过Base62编码将其转换为短字符串
- 解决分布式系统的ID冲突
- 问题:在分布式部署的短连接服务中,若多个实例同时生成ID,可能因时钟不同步或逻辑错误导致ID重复。
- 雪花算法的优势
- 通过 机器ID 隔离不同实例生成的ID
- 结合 时间戳 和 序列号,确保同一实例同一毫秒内生成的ID唯一
- 提升性能与扩展性
- 问题:使用数据库自增ID时,生成ID依赖数据库写入操作,成为性能瓶颈。
- 雪花算法优势:
- 去中心化生成ID:无需访问数据库,直接在应用层生成。
- 高吞吐量:单机每毫秒可生成4096个ID,理论峰值约 409.6万/秒。
- 保证短码有序性
- 时间戳排序:雪花ID按时间戳递增,生成的短码隐含时间顺序,便于:
- 按时间范围查询短链。
- 优化数据库索引性能(有序ID的索引效率更高)。
- 时间戳排序:雪花ID按时间戳递增,生成的短码隐含时间顺序,便于:
2. 项目
项目地址:https://gitee.com/qing2356/short.git
2.1 简介
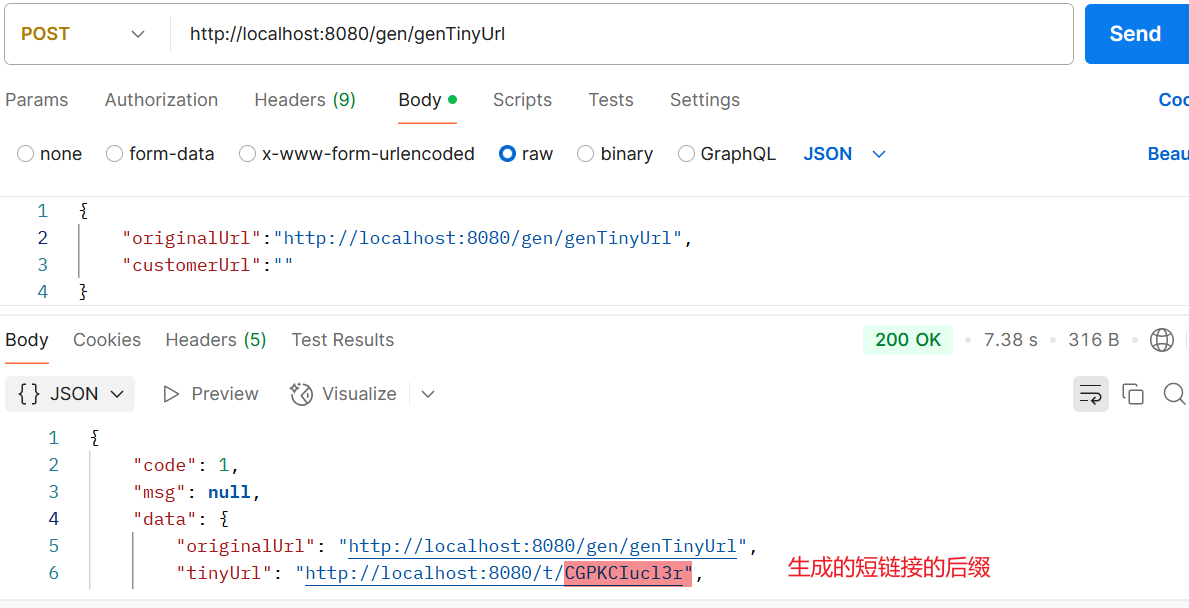
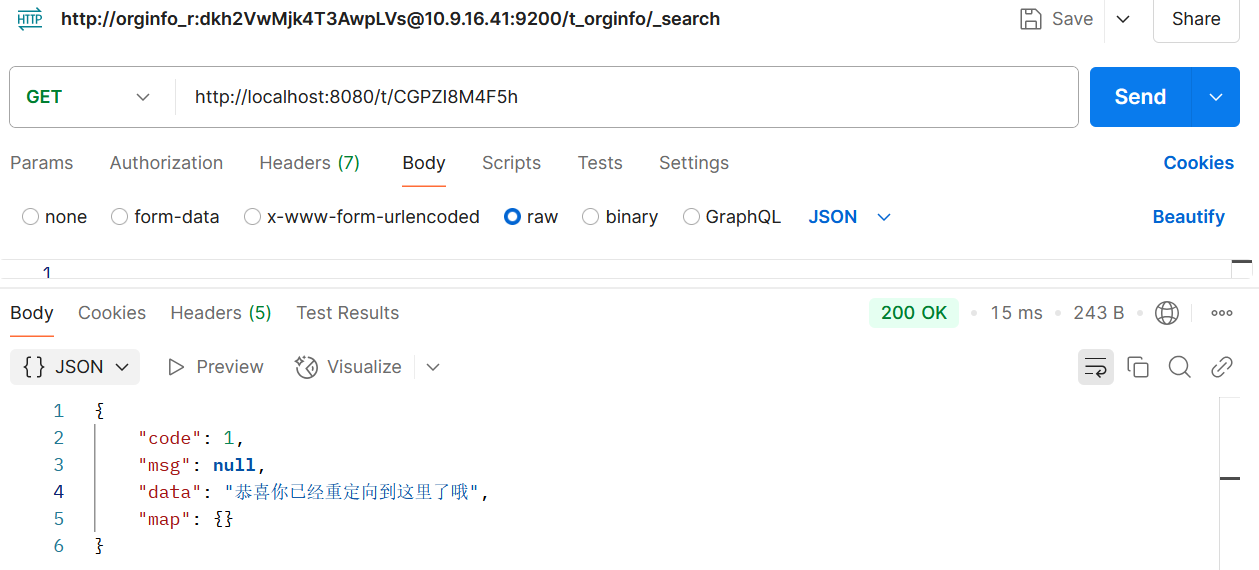
一个纯后端简单的短连接生成项目,并且可以做到短连接重定向,以下是使用postman的测试结果图
-
短链接生成
-
短链接重定向
2.2 技术栈
使用到的技术栈包括SpringBoot+MyBatis+Redis+MySQL+雪花算法+base62编码
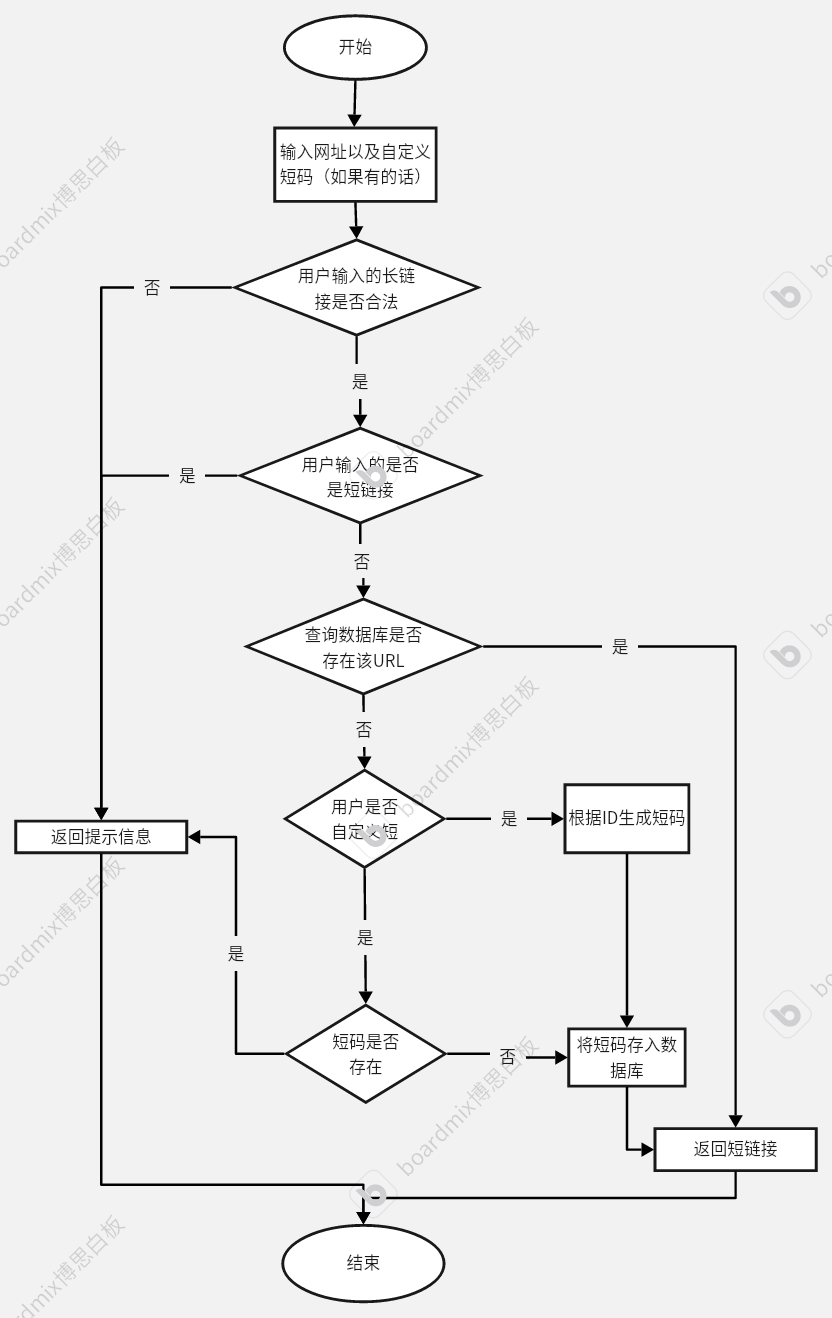
2.3 流程图
2.4 配置项目
如果想要使用这个项目的话,请注意以下几个问题
- 先创建数据库中的数据表
- 配置文件中的数据库配置,以及缓存配置修改为自己的


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









