







k-means收敛的理解!
K-means
首先,我们都介绍一下k-means的具体步骤:
1、首先,定义聚类个数参数K,然后初始原始的K个聚类中心点(可以采用随机,或者k-means++);
2、遍历所有样本点,并计算其到各个聚类中心点的距离,然后选择距离最短的类别,并将样本点划分到该类别下;
3、当更新完毕所有点的类别后,重新计算每个类别的聚类中心点;
4、重复step2-step3,直到聚类中心点不再发生变化,或者达到一定的迭代次数。
======================================================
K-means目标函数
通过上述过程,可以知道,k-means的目标就是最小化各个类别中点到中心点的距离,即:
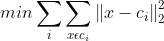
c表示中心点坐标。
======================================================
K-means收敛考虑
那么,为什么这样的步骤能使得结果最终收敛呢?这里主要从3个部分去考虑
首先
- 通过step3我们知道,每个类别的聚类中心点会在点的类别再分配后重新计算,那么为什么?因为这样的做法,可以使得类别内的目标距离降低。从上面的k-means目标函数看,我们对c进行求导,可以发现,当c等于其类别内点的中心点坐标,导数等于0,即目标结果取得极小值。所以,每次step3操作,重新计算各个类别的中心点,可以使得目标距离降低。(可以想象一下前后不同的中心点的二维散点图的结果,重新计算中心点,确实会减少每个类别内的方差)
- 第二个方面就是,我们知道重新计算完聚类中心后,我们需要计算step2,在对每个样本点的类别进行重分配。如果结果还未收敛,那么在该步骤中,每个样本点会从之前的类别p划分到新的类别p’,那么这里,明显可以知道相较于之前的类别,该点到新类别点的中心点p’,距离肯定是小于到p,因此,目标距离结果肯定会减少,因为一个较多的距离被替换成较少的距离了。
- 综上,由于每次迭代目标距离的结果都会降低,并且该目标距离函数明显是有下界的,所以我们可以想象成单调递减数列,有下界(粗略估计得下界为0,猜想应该有一个更精准的下界,并且最终能够收敛到该下界。),那么当迭代次数n趋于无穷,那么必定会收敛。
面对较小数据量时,很容易会达到中心点不变的情况,即收敛。但是当数据量较大时,需要设定一定的迭代次数,防止程序一直运行无法终止。
基于EM的K-means收敛
======================================================
此外,是否收敛也可以通过EM框架进行证明:可以想象有K个高斯分布函数,以及一个隐变量z。那么我们需要最大化sigma(P(x, z|theta))。实际上也是类似于GMM模型,是GMM的一个特殊考虑情况。这块内容,过几天再补上。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









