




 本文详细介绍了如何安装和部署Hadoop以及Azkaban。首先,讲述了Hadoop的下载、解压、配置环境变量、启动和验证过程,包括单节点和多节点模式。接着,介绍了Azkaban的下载、解压、配置数据库和启动步骤。最后,讨论了如何在Azkaban中集成和调度Hadoop作业。
本文详细介绍了如何安装和部署Hadoop以及Azkaban。首先,讲述了Hadoop的下载、解压、配置环境变量、启动和验证过程,包括单节点和多节点模式。接着,介绍了Azkaban的下载、解压、配置数据库和启动步骤。最后,讨论了如何在Azkaban中集成和调度Hadoop作业。
Hadoop、Azkaban是常用的大数据平台工具,本文将介绍如何安装和部署Hadoop和Azkaban,并提供相应的代码案例和参数介绍。
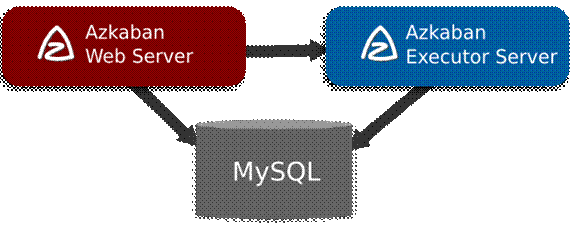
一、Hadoop安装部署
Hadoop是一个分布式计算框架,用于处理大规模数据集。以下是Hadoop的安装和部署步骤:
1.下载Hadoop包:在Hadoop官方网站上下载最新的稳定版本的Hadoop。下载地址:https://hadoop.apache.org/releases.html
2.解压Hadoop包:将下载的Hadoop包解压到目标目录,例如:/opt/hadoop。
3.配置Hadoop环境变量:编辑~/.bashrc文件,添加以下内容:
export HADOOP_HOME=/opt/hadoop export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
然后执行以下命令使环境变量生效:
$ source ~/.bashrc
4.配置Hadoop集群:Hadoop支持单节点模式和多节点模式。在单节点模式下,所有组件运行在同一台机器上;在多节点模式下,不同组件运行在不同的机器上。
4.1 单节点模式配置: 在单节点模式下,只需要配置单个节点即可。打开hadoop-env.sh文件,编辑以下配置:
export JAVA_HOME=/path/to/java export HADOOP_CONF_DIR=${HADOOP_CONF_DIR:-"/opt/hadoop/conf"}
其中,/path/to/java是Java的安装路径,/opt/hadoop/conf是Hadoop的配置文件目录。
4.2 多节点模式配置: 在多节点模式下,需要配置一个主节点(NameNode)和多个从节点(DataNode)。打开core-site.xml文件,添加以下内容:
<property> <name>fs.defaultFS</name> <value>hdfs://namenode:9000</value> </property>
其中,hdfs://namenode:9000是NameNode节点的地址。
打开hdfs-site.xml文件,添加以下内容:
<property> <name>dfs.replication</name> <value>3</value> </property>
其中,3表示副本的数量。
5.启动Hadoop集群:
5.1 单节点模式启动: 执行以下命令启动Hadoop集群:
$ start-dfs.sh
该命令将启动单节点的HDFS。
5.2 多节点模式启动: 执行以下命令启动Hadoop集群:
$ start-dfs.sh
该命令将启动多节点模式的HDFS。
6.验证Hadoop集群:执行以下命令验证Hadoop集群是否正常运行:
$ hdfs dfs -ls /
如果能够正常显示文件列表,则表示Hadoop集群已成功运行。
二、Azkaban安装部署
Azkaban是一个开源的工作流调度系统,用于调度和执行Hadoop作业。以下是Azkaban的安装和部署步骤:
1.下载Azkaban包:在Azkaban官方网站上下载最新的稳定版本的Azkaban。下载地址:https://azkaban.github.io/downloads.html
2.解压Azkaban包:将下载的Azkaban包解压到目标目录,例如:/opt/azkaban。
3.配置Azkaban环境变量:编辑~/.bashrc文件,添加以下内容:
export AZKABAN_HOME=/opt/azkaban export PATH=$PATH:$AZKABAN_HOME/bin
然后执行以下命令使环境变量生效:
$ source ~/.bashrc
4.配置Azkaban数据库:Azkaban需要使用数据库存储作业流的信息和状态。常用的数据库有MySQL、PostgreSQL等。
4.1 安装数据库:根据需求选择合适的数据库并进行安装和配置。
4.2 创建数据库:执行以下命令创建Azkaban数据库:
$ mysql -u root -p mysql> CREATE DATABASE azkaban; mysql> USE azkaban; mysql> SOURCE /opt/azkaban/azkaban-[version].sql;
其中,/opt/azkaban/azkaban-[version].sql是Azkaban数据库脚本的路径。
5.配置Azkaban服务器:打开azkaban.properties文件,配置以下参数:
database.type=mysql mysql.url=jdbc:mysql://localhost:3306/azkaban mysql.database=azkaban mysql.user=root mysql.password=your_password azkaban.webserver.name=azkaban-web-server azkaban.servlet.path=/azkaban azkaban.default.timezone.id=Asia/Shanghai executor.port=12321
其中,localhost:3306是数据库的地址和端口,azkaban-web-server是Azkaban的服务器名称,Asia/Shanghai是Azkaban的默认时区,12321是Azkaban的执行器端口。
6.启动Azkaban服务:执行以下命令启动Azkaban服务:
$ azkaban-start.sh
7.验证Azkaban服务:在浏览器中访问Azkaban的Web界面(http://localhost:8081/azkaban),如果能够正常显示界面,则表示Azkaban服务已成功启动。
三、Hadoop与Azkaban集成
Hadoop和Azkaban可以进行集成,以实现在Azkaban中调度和执行Hadoop作业。以下是集成的步骤:
1.创建Hadoop作业:在Azkaban中创建一个Hadoop作业,并定义该作业的输入输出路径。
2.编写Hadoop作业脚本:编写一个Hadoop作业的脚本,用于执行具体的Hadoop作业。
3.配置Azkaban调度流:在Azkaban中创建一个调度流,将Hadoop作业添加到该调度流中。
4.配置调度流参数:为调度流设置参数,如输入输出路径、作业执行时间等。
5.启动调度流:在Azkaban中启动调度流,Azkaban将按照预定的时间调度和执行Hadoop作业。
以下是一个简单的Hadoop作业脚本的示例(WordCount.java):
|
import java.io.IOException; import java.util.StringTokenizer; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.Mapper; import org.apache.hadoop.mapreduce.Reducer; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat; public class WordCount { public static class TokenizerMapper extends Mapper<Object, Text, Text, IntWritable>{ private final static IntWritable one = new IntWritable(1); private Text word = new Text(); public void map(Object key, Text value, Context context ) throws IOException, InterruptedException { StringTokenizer itr = new StringTokenizer(value.toString()); while (itr.hasMoreTokens()) { word.set(itr.nextToken()); context.write(word, one); } } } public static class IntSumReducer extends Reducer<Text,IntWritable,Text,IntWritable> { private IntWritable result = new IntWritable(); public void reduce(Text key, Iterable<IntWritable> values, Context context ) throws IOException, InterruptedException { int sum = 0; for (IntWritable val : values) { sum += val.get(); } result.set(sum); context.write(key, result); } } public static void main(String[] args) throws |



















 3584
3584

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











