




 本文讲述了HiveDDL在导入导出数据中的关键操作,包括创建表、数据导入、导出步骤,以及所需参数和代码实例。
本文讲述了HiveDDL在导入导出数据中的关键操作,包括创建表、数据导入、导出步骤,以及所需参数和代码实例。
一、HiveDDL数据导入导出的理论解说
- HiveDDL是Hive的数据定义语言,用于定义和管理Hive中的表、分区、视图等对象。通过HiveDDL可以方便地进行数据导入和导出操作。
- Hive支持多种数据导入导出方式,包括从本地文件系统导入导出、从HDFS导入导出、从其他数据库导入导出等。
- Hive提供了多种文件格式,如文本格式、序列文件格式、ORC格式等,可以根据需求选择合适的文件格式进行数据导入导出。
- HiveDDL的数据导入导出操作可以通过命令行工具、HiveQL语句、Hive API等方式进行。
二、HiveDDL数据导入导出的操作步骤
- 创建表:首先需要创建一个Hive表,用于存储导入导出的数据。可以通过HiveQL语句或命令行工具创建表,并指定表的列名和数据类型。
- 导入数据:可以使用LOAD DATA语句或命令行工具将数据导入到Hive表中。导入数据时需要指定数据源的路径、目标表的名称以及数据的格式等参数。
- 导出数据:可以使用INSERT OVERWRITE语句将Hive表中的数据导出到指定的路径。导出数据时需要指定数据的存储格式、目标路径等参数。
三、HiveDDL数据导入导出的参数介绍和完整代码案例
1.参数介绍:
- LOCATION:指定数据的路径,可以是本地文件系统或HDFS路径。
- OVERWRITE:指定是否覆盖已存在的数据。
- FILEFORMAT:指定数据的存储格式,如TEXTFILE、SEQUENCEFILE、ORC等。
- TABLE:指定目标表的名称。
2.完整代码案例:
(1)创建表
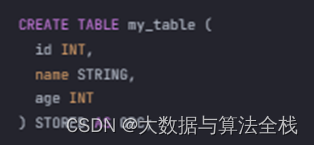
|
CREATE TABLE my_table ( id INT, name STRING, age INT ) STORED AS ORC; |
(2)从本地文件系统导入数据:
LOAD DATA LOCAL INPATH '/path/to/data' INTO TABLE my_table;
(3)从HDFS导入数据:
LOAD DATA INPATH '/path/to/data' INTO TABLE my_table;
(4)导出数据到本地文件系统:
INSERT OVERWRITE LOCAL DIRECTORY '/path/to/output' ROW FORMAT DELIMITED FIELDS TERMINATED BY ',' SELECT * FROM my_table;
(5)导出数据到HDFS:
INSERT OVERWRITE DIRECTORY '/path/to/output' ROW FORMAT DELIMITED FIELDS TERMINATED BY ',' SELECT * FROM my_table;
四、总结
HiveDDL数据导入导出是Hive的重要功能之一,通过HiveDDL可以方便地将数据导入到Hive表中或将Hive表中的数据导出到其他存储系统中。在进行数据导入导出时,需要指定数据的路径、存储格式等参数,以及使用相应的HiveQL语句或命令行工具进行操作。通过掌握HiveDDL数据导入导出的理论和操作步骤,可以更好地利用Hive进行数据处理和分析。



















 460
460

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











