







python日记——Pandas之Excel处理
- 创建文件
import pandas as pd
df = pd.DataFrame({'ID':[1,2,3],'Name':['Tom','BOb','Gigi']})
df.to_excel("C:/Temp/Output.xlsx")
print("done!")- 读取文件
import pandas as pd
people = pd.read_excel("C:/Temp/people.xlsx",index_col='ID')
#index_col用于设置索引
print(people.shape)
print(people.columns)
print(people.index)
print(people.head(3))#打印前三行,默认5行
print(people.tail(3))#打印后三行,默认5行当head比较“脏”,即第一行不是表头时:
people = pd.read_excel("C:/Temp/people.xlsx",header=1)
#header的值由表头的位置决定
#当第一行为空时,不需要设置header,自动跳过空行当表在其他位置时,如何读取:
people = pd.read_excel('C:/Temp/people.xlsx',skiprows=3,usecols="C:F")
#skiprows用于跳过行,usecols用于规定列当没有表头时,可自行进行设置:
people.columns = ['序号','姓名','年龄']当创建一个新的表格时,会生成自动索引,怎样去掉默认的自动索引:
people = people.set_index("序号")
#people.set_index("序号",inplace=True)- 行、列、单元格
pandas的Serise对象可以当作Excel中的一列,由此可以根据Serise创建Excel:
import pandas as pd
A = pd.Series([1,2,3],index=[1,2,3],name="A")
B = pd.Series([10,20,30],index=[1,2,3],name="B")
C = pd.Series([100,200,300],index=[1,2,3],name="C")
D = pd.DataFrame({A.name:A,B.name:B,C.name:C},index=[1,2,3])
#D = pd.DataFrame([A,B,C]) 当以这种方式创建时,ABC将分别作为行来创建
D.to_excel("C:/Temp/output.xlsx")
print("done!")- Excel自动填充
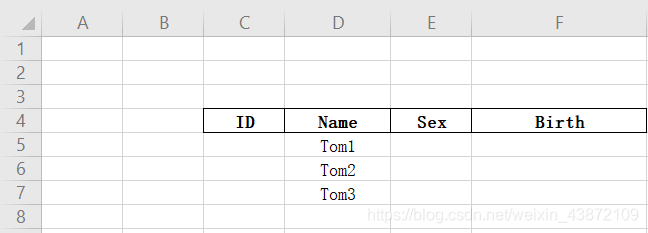
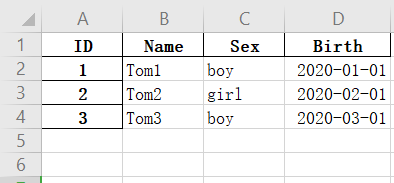
给出如下表people.xlsx,实现ID的自动填充,Sex填充为”boy“、”girl“交替进行,Birth实现按日以此递增,按月依次递增、按年以此递增。
import pandas as pd
from datetime import date,timedelta
def add_month(d,md):
yd = md//12
m = d.month + md % 12
if m != 12:
yd += m//12
m = m%12
return date(d.year + yd,m,d.day)
people = pd.read_excel('C:/Temp/people.xlsx',
skiprows=3,usecols="C:F",dtype={'ID':str,'Sex':str,'Birth':str})
'''
skiprows用于跳过行,usecols用于规定列
当单元格为空时,单元格默认为NaN
当Serise存在NaN时,默认dtype为float64类型,因此在添加空单元格时需要注意类型
此处通过读取时设置dtype将其全部转换为str类型
'''
start = date(2020,1,1)
for i in people.index:
people['ID'].at[i] = i+1
people['Sex'].at[i] = 'boy' if i%2==0 else 'girl'
people['Birth'].at[i] =add_month(start,i)
people = people.set_index('ID')
people.to_excel("C:/Temp/output.xlsx")运行效果
- 函数填充、计算列
根据其他列计算另一列,或者修改自身列
import pandas as pd
student_grades = pd.read_excel("C:/Temp/student.xlsx")
student_grades.Math_grades += 2
student_grades.English_grades -= 3
student_grades.Total_grades = student_grades.Math_grades + student_grades.English_grades
student_grades = student_grades.set_index("ID")
student_grades.to_excel("C:/Temp/output_stu.xlsx")
print('done!')- 排序、多重排序
对于一个学生成绩表,按照总分排序,以及按照班级进行总分排序(多重排序)
import pandas as pd
student = pd.read_excel("C:/Temp/output_stu.xlsx",index_col="ID")
#只按照总分排序
student.sort_values(by='Total_grades',inplace=True,ascending=False)
#按照每个班级进行总分由高到低排序
student.sort_values(by=['Class','Total_grades'],inplace=True,ascending=[True,False])
student.to_excel("C:/Temp/stu_output.xlsx")- 数据过滤、筛选
筛选出数学、英语成绩均大于80的
import pandas as pd
student = pd.read_excel("C:/Temp/stu_output.xlsx")
student = student.loc[student.Math_grades.apply(lambda a:a>=80)].loc[student.English_grades.apply(lambda a:a>=80)]
print(student)以下所用到的相关文件连接如下:excel文件,提取码:falj
- 行列转换
import pandas as pd
worker = pd.read_excel("C:/Temp/worker.xlsx",index_col='ID')
table = worker.transpose()
print(table)
- 统计分析,求和、求平均
import pandas as pd
pd.options.display.max_columns=777
stu = pd.read_excel("C:/Temp/student.xlsx",sheet_name="stu_grades")
temp = stu[['Math_grades','English_grades']]
row_sum = temp.sum(axis=1)
row_mean = temp.mean(axis=1)
stu['Total_grades'] = row_sum
stu['Average_grades'] = row_mean
col_mean = stu[['Math_grades','English_grades','Total_grades']].mean()
col_mean['Name'] = 'summary'
stu = stu.append(col_mean,ignore_index=True)
print(stu)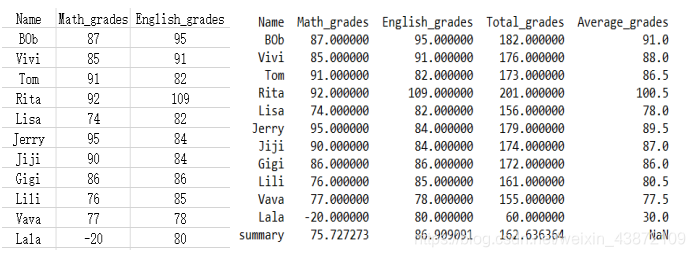
- 定位、消除重复数据
import pandas as pd
worker = pd.read_excel("C:/Temp/worker.xlsx")
#数据定位
dupe = worker.duplicated(subset='Worker_num')
dupe = dupe[dupe]
print(worker.iloc[dupe.index])
#数据消除
worker.drop_duplicates(subset='Worker_num',inplace=True,keep='first')
#subset用于选择列,keep用于选择保留的重复部分,last保留后面重复部分
print(worker)- 数据校验
import pandas as pd
def grades_check(df):
try:
assert 0<=df.Math_grades<=100 and 0<=df.English_grades<=100
#assert(断言)用于判断一个表达式,在表达式条件为 false 的时候触发异常。
except:
print(f'#{df.Name} has invalid grades')
#print字符串前面加f表示格式化字符串,加f后可以在字符串里面使用用花括号括起来的变量和表达式
stu = pd.read_excel("C:/Temp/student.xlsx",sheet_name='stu_grades')
stu.apply(grades_check,axis=1)
#df.apply()可以传入自定义的函数,axis=1表示一行一行进行校验- 多表联合
import pandas as pd
stu_grades = pd.read_excel("C:/Temp/student.xlsx",sheet_name="stu_grades",index_col='Name')
stu_class = pd.read_excel("C:/Temp/student.xlsx",sheet_name="stu_class",index_col='Name')
table = stu_grades.join(stu_class,how='right').fillna(0)
#join默认采用index进行表的联合,也可通过 on 进行设置
#how用于确定是保留左表还是右表 fillna用于填充NaN
table[['Math_grades','English_grades','Total_grades']]=table[['Math_grades',
'English_grades','Total_grades']].astype(int)
print(table)- 一列数据分割为两列
#将Name分割为first name和last name
import pandas as pd
people = pd.read_excel("C:/Temp/people.xlsx",index_col='ID')
df = people.Name.str.split(expand=True)
#expand为True时可在分割后直接扩充为多列
people['first_name'] = df[0]
people['last_name'] = df[1]
#创建新的列时,不能使用a.b的方式
people = people.drop("Name",axis=1)
#drop默认删除行索引,删除列索引时,需要添加axis=1
print(people)














 1012
1012











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









