









下载
cd /opt/software
wget https://archive.apache.org/dist/dolphinscheduler/3.0.1/apache-dolphinscheduler-3.0.1-bin.tar.gz
解压目录
tar -zxvf apache-dolphinscheduler-3.0.1-bin.tar.gz
使用root登录,设置部署用户名
useradd dolphinscheduler
设置用户密码
echo "123456" | passwd --stdin dolphinscheduler
修改目录权限,使得部署用户对dolphinscheduler目录有操作权限
sudo chown -R dolphinscheduler:dolphinscheduler apache-dolphinscheduler-3.0.1-bin
配置sudo免密
sudo echo 'dolphinscheduler ALL=(ALL) NOPASSWD: NOPASSWD: ALL' >> /etc/sudoers
sudo sed -i 's/Defaults requirett/#Defaults requirett/g' /etc/sudoers
添加数据库
mysql -uroot -p
CREATE DATABASE dolphinscheduler DEFAULT CHARACTER SET utf8 DEFAULT COLLATE utf8_general_ci;
GRANT ALL PRIVILEGES ON dolphinscheduler.* TO 'dolphinscheduler'@'%' IDENTIFIED BY '123456';
GRANT ALL PRIVILEGES ON dolphinscheduler.* TO 'dolphinscheduler'@'localhost' IDENTIFIED BY '123456';
flush privileges;
添加驱动
pwd
/opt/software/apache-dolphinscheduler-3.0.1-bin
cp -rp mysql-connector-java-8.0.16.jar alert-server/libs/
cp -rp mysql-connector-java-8.0.16.jar api-server/libs/
cp -rp mysql-connector-java-8.0.16.jar master-server/libs/
cp -rp mysql-connector-java-8.0.16.jar standalone-server/libs/
cp -rp mysql-connector-java-8.0.16.jar tools/libs/
cp -rp mysql-connector-java-8.0.16.jar worker-server/libs/
修改配置文件install_env.sh
vim bin/env/install_env.sh
ips="hostname"
sshPort="22"
masters="hostname"
workers="hostname"
alertServer="hostname"
apiServers="hostname"
installPath="/opt/module/dolphinscheduler"
deployUser="dolphinscheduler"
zkRoot="/dolphinscheduler"
修改配置文件dolphinscheduler_env.sh
vim bin/env/dolphinscheduler_env.sh
# JAVA_HOME, will use it to start DolphinScheduler server
export JAVA_HOME=/usr/java/jdk1.8.0_232/
# Database related configuration, set database type, username and password
export DATABASE=${DATABASE:-mysql}
export SPRING_PROFILES_ACTIVE=${DATABASE}
export SPRING_DATASOURCE_URL="jdbc:mysql://hostname:3306/dolphinscheduler?useUnicode=true&characterEncoding=UTF-8&useSSL=false"
export SPRING_DATASOURCE_USERNAME="dolphinscheduler"
export SPRING_DATASOURCE_PASSWORD="123456"
# DolphinScheduler server related configuration
export SPRING_CACHE_TYPE=${SPRING_CACHE_TYPE:-none}
export SPRING_JACKSON_TIME_ZONE=${SPRING_JACKSON_TIME_ZONE:-GMT+8}
export MASTER_FETCH_COMMAND_NUM=${MASTER_FETCH_COMMAND_NUM:-10}
# Registry center configuration, determines the type and link of the registry center
export REGISTRY_TYPE="zookeeper"
export REGISTRY_ZOOKEEPER_CONNECT_STRING="hostname:2181"
# Tasks related configurations, need to change the configuration if you use the related tasks.
export HADOOP_HOME=/opt/cloudera/parcels/CDH/lib/hadoop
export HADOOP_CONF_DIR=/opt/cloudera/parcels/CDH/lib/hadoop/etc/hadoop
export SPARK_HOME1=/opt/cloudera/parcels/CDH/lib/spark
export SPARK_HOME2=/opt/cloudera/parcels/CDH/lib/spark
export PYTHON_HOME=/usr/bin/python3
export HIVE_HOME=/opt/cloudera/parcels/CDH/lib/hive
export FLINK_HOME=/opt/cloudera/parcels/FLINK/lib/flink
export DATAX_HOME=${DATAX_HOME:-/opt/soft/datax}
export SEATUNNEL_HOME=${SEATUNNEL_HOME:-/opt/soft/seatunnel}
export CHUNJUN_HOME=${CHUNJUN_HOME:-/opt/soft/chunjun}
export PATH=$HADOOP_HOME/bin:$SPARK_HOME1/bin:$SPARK_HOME2/bin:$PYTHON_HOME/bin:$JAVA_HOME/bin:$HIVE_HOME/bin:$FLINK_HOME/bin:$DATAX_HOME/bin:$SEATUNNEL_HOME/bin:$CHUNJUN_HOME/bin:$PATH
配置HDFS
vim api-server/conf/common.properties
data.basedir.path=/tmp/dolphinscheduler
resource.storage.type=HDFS
resource.storage.upload.base.path=/dolphinscheduler
resource.hdfs.root.user=root
resource.hdfs.fs.defaultFS=hdfs://hostname:8020
yarn.application.status.address=http://hostname:%s/ws/v1/cluster/apps/%s
yarn.job.history.status.address=http://hostname:19888/ws/v1/history/mapreduce/jobs/%s
worker-server/conf/common.properties 跟上步骤一样的 直接复制过来就行
cp -rp api-server/conf/common.properties worker-server/conf
初始化数据库
bash tools/bin/upgrade-schema.sh
安装部署
./bin/install.sh
会安装在 /opt/module 可在上文中自定义
installPath=“/opt/module/dolphinscheduler”
cd /opt/module/dolphinscheduler

启动:
cd bin/
./start-all.sh
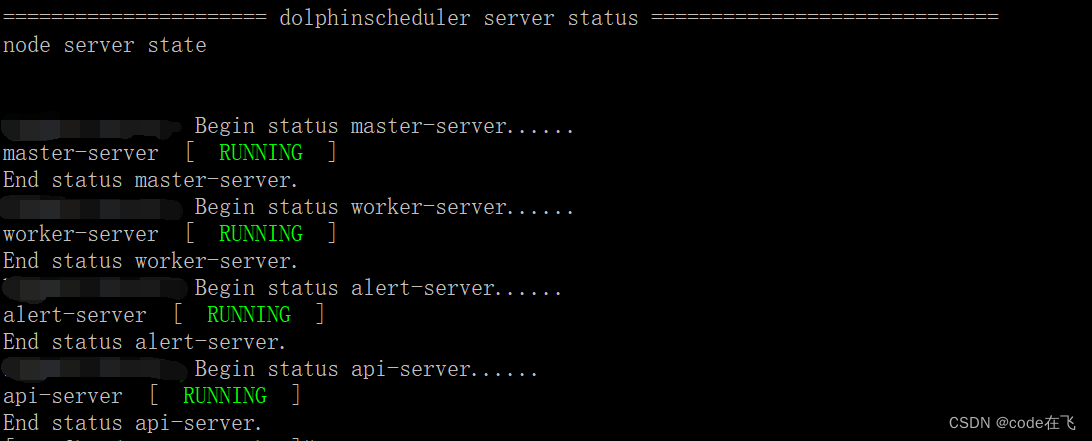
登录
http://ip:12345/dolphinscheduler/ui
默认用户名和密码
admin
dolphinscheduler123















 2629
2629











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









