







目录
1.re.search---------re.search("正则表达式","目标字符串")
2.re.match---------re.match("正则表达式","目标字符串")
3.re.findall---------re.findall("正则表达式","目标字符串")
4.re.finditer---------re.finditer("正则表达式","目标字符串")
一.正则表达式的作用
1.正则表达式的用途:
• 数据挖掘
从一大堆文本中找到一小堆文本时。如,从文本是寻找email, ip, telephone等
• 验证
使用正则确认获得的数据是否是期望值。如,email、用户名是否合法等
• 非必要时慎用正则,如果有更简单的方法匹配,可以不使用正则
2.正则表达式的目的:
• 指定一个匹配规则,从而识别该规则是否在一个更大的文本字符串中。
• 正则表达式可以识别匹配规则的文本是否存在
• 还能将一个规则分解为一个或多个子规则,并展示每个子规则匹配的文本
3.正则表达式的优缺点:
• 优点:提高工作效率、节省代码
• 缺点:复杂,难于理解
注意:正则表达式并不是只有在python中可以使用,只要是支持正则表达式引擎的都可以使用
python中的re模块支持正则表达式,它是python中的标准库,无需额外下载
二.re模块的基本用法
1.re.search---------re.search("正则表达式","目标字符串")
• 查找匹配项
• 接受一个正则表达式和字符串,并返回发现的第一个匹配,返回的是一个match对象。
• 如果完全没有找到匹配,re.search返回None
#######以下代码均在linux中的python3中使用
[root@xieshan ~]# python3
Python 3.6.8 (default, Nov 16 2020, 16:55:22)
[GCC 4.8.5 20150623 (Red Hat 4.8.5-44)] on linux
Type "help", "copyright", "credits" or "license" for more information.
>>> import re
>>> re.search("s.{6}","hello world,sanchuang tongle")
<_sre.SRE_Match object; span=(12, 19), match='sanchua'>
>>> result = re.search("s.{6}","hello world,sanchuang tongle")
>>> result
<_sre.SRE_Match object; span=(12, 19), match='sanchua'>
>>> result2 = re.search("x.{6}","hello world,sanchuang tongle")
>>> result2
>>> print(result2)
None2.re.match---------re.match("正则表达式","目标字符串")
• 从字符串头查找匹配项
• 接受一个正则表达式和字符串,从主串第一个字符开始匹配,并返回发现的第一个匹配,返回的是一个match对象。
• 如果字符串开始不符合正则表达式,则匹配失败,re.match返回None
#######以下代码均在linux中的python3中使用
[root@xieshan ~]# python3
Python 3.6.8 (default, Nov 16 2020, 16:55:22)
[GCC 4.8.5 20150623 (Red Hat 4.8.5-44)] on linux
Type "help", "copyright", "credits" or "license" for more information.
>>> import re
>>> re.match("s.{6}","hello world,sanchuang tongle")
>>> re.match("h.{6}","hello world,sanchuang tongle")
<_sre.SRE_Match object; span=(0, 7), match='hello w'>
>>> re.match("e.{6}","hello world,sanchuang tongle")
>>> result2 = re.search("s.{6}","hello world,sanchuang tongle sanchuang")
>>> result
<_sre.SRE_Match object; span=(12, 19), match='sanchua'>
2.1 match对象:
1.match.group(default=0):返回匹配的字符串。
• group是由于正则表达式可以分拆为多个只调出匹配子集的子组。
• 0是默认参数,表示匹配的整个串,n 表示第n个分组

2.match.start()
• start方法提供了原始字符串中匹配开始的索引
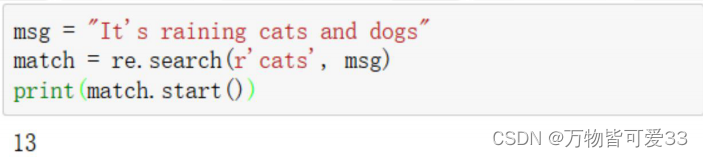
3.match.end()
• end方法提供了原始字符串中匹配开始的索引
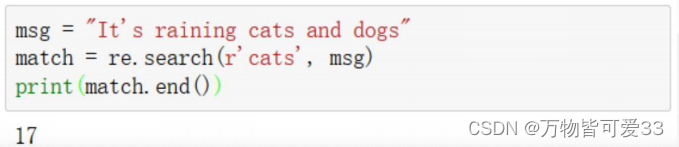
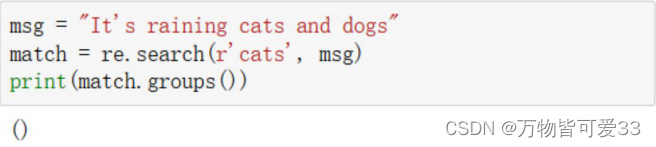
4. match.groups()
• groups返回一个包含所有小组字符串的元组,从 1 到 所含的小组号。
#######以下代码均在linux中的python3中使用
[root@xieshan ~]# python3
Python 3.6.8 (default, Nov 16 2020, 16:55:22)
[GCC 4.8.5 20150623 (Red Hat 4.8.5-44)] on linux
Type "help", "copyright", "credits" or "license" for more information.
>>> import re
>>> result = re.search("s.{6}","hello world,sanchuang tongle")
>>> result
<_sre.SRE_Match object; span=(12, 19), match='sanchua'>
>>> result.start()
12
>>> result.end()
19
>>> result.group()
'sanchua'2.2 raw的用法
使用正则表达式的时候,在有转义字符的地方,在前面加上一个r,会变得更加准确。r代表的就是raw(原始字符串)
• 原始字符串与正常字符串的区别是原始字符串不会将\字符解释成一个转义字符
• 正则表达式使用原始字符很常见且有用
•在正则表达式里面遇到转义字符的时候,首先python系统会先进行一次转义,然后将转义过的字符再交给正则表达式去处理,会进行第二次转义,相当于在正则表达里面会进行两次转义,但是普通的转义,在python中只会进行一次转义,这就导致有时候两边可能一样,但是却匹配不上(这都是在没有加上r的情况下)
[root@xieshan ~]# python3
Python 3.6.8 (default, Nov 16 2020, 16:55:22)
[GCC 4.8.5 20150623 (Red Hat 4.8.5-44)] on linux
Type "help", "copyright", "credits" or "license" for more information.
>>> import re
>>> rest = re.search('\\tsanle','hello\\tsanle')
>>> print(rest)
None
>>> rest = re.search(r'\\tsanle','hello\\tsanle')
>>> print(rest)
<_sre.SRE_Match object; span=(5, 12), match='\\tsanle'>
>>>
>>> re.search("hello\tworld", "sanchuang hello\tworld")
<_sre.SRE_Match object; span=(10, 21), match='hello\tworld'>
>>> re.search(r"hello\tworld", "sanchuang hello\tworld")
<_sre.SRE_Match object; span=(10, 21), match='hello\tworld'>
>>> re.search("hello\\tworld", "sanchuang hello\tworld")
<_sre.SRE_Match object; span=(10, 21), match='hello\tworld'>
>>> re.search(r"hello\\tworld", "sanchuang hello\tworld")
>>> re.search("hello\\\tworld", "sanchuang hello\tworld")
<_sre.SRE_Match object; span=(10, 21), match='hello\tworld'>
>>> re.search(r"hello\\\tworld", "sanchuang hello\tworld")
>>> re.search("hello\\\\tworld", "sanchuang hello\tworld")
>>>3.re.findall---------re.findall("正则表达式","目标字符串")
找到所有匹配的内容,放到一个列表里面然后返回,会直接返回匹配上的字符串
[root@xieshan ~]# python3
Python 3.6.8 (default, Nov 16 2020, 16:55:22)
[GCC 4.8.5 20150623 (Red Hat 4.8.5-44)] on linux
Type "help", "copyright", "credits" or "license" for more information.
>>> import re
>>> re.findall("s.{6}", "hello sanle sanchuang nihao world ssssssss")
['sanle s', 'sssssss']4.re.finditer---------re.finditer("正则表达式","目标字符串")
找到所有匹配内容,返回一个迭代器,惰性求值;finditer 找到的每个内容都是一个match对象,需要调用group来获取里面具体的匹配字符串
[root@xieshan ~]# python3
Python 3.6.8 (default, Nov 16 2020, 16:55:22)
[GCC 4.8.5 20150623 (Red Hat 4.8.5-44)] on linux
Type "help", "copyright", "credits" or "license" for more information.
>>> import re
>>> re.finditer("s.{6}", "hello sanle sanchuang nihao world ssssssss")
<callable_iterator object at 0x7f1c303a1240>
>>> result = re.finditer("s.{6}", "hello sanle sanchuang nihao world ssssssss")
>>> for i in result:
... print(i)
...
<_sre.SRE_Match object; span=(6, 13), match='sanle s'>
<_sre.SRE_Match object; span=(34, 41), match='sssssss'>
>>> result = re.finditer("s.{6}", "hello sanle sanchuang nihao world ssssssss")
>>> for i in result:
... print(i.group())
...
sanle s
sssssss5.正则替换
基本语法:re.sub("匹配正则","替换内容","string")
• 将string中匹配的内容替换为新内容
[root@xieshan ~]# python3
Python 3.6.8 (default, Nov 16 2020, 16:55:22)
[GCC 4.8.5 20150623 (Red Hat 4.8.5-44)] on linux
Type "help", "copyright", "credits" or "license" for more information.
>>> import re
>>> str1 = "hello , i am learning python python"
>>> print(re.sub("p.{2}","xixi",str1))
hello , i am learning xixihon xixihon
6.正则编译
编译正则的特点:
• 复杂的正则可复用。
• 使用编译正则更方便,省略了参数。
• re模块缓存它即席编译的正则表达式,因此在大多数情况下,使用compile并没有很大
的性能优势
#####取出字符串中的名字
import re
msg = "hello, my name is jack"
msg2 = "hello, my name is rose"
##方法1
result = re.findall("is\s(.*)", msg)
result2 = re.findall("is\s(.*)$", msg2)
print(result)
print(result2)
##方法2:正则编译
reg = re.compile("is\s(.*)$")
print(reg.findall(msg))
print(reg.findall(msg2))三.基本正则匹配
1.区间
最简单的正则表达式是那些仅包含简单的字母数字字符的表达式,复杂的正则可以实现强大的匹配
n 区间:[] 根据ascii码来的
• 正则匹配区分大小写
• 匹配所有字母:[a-zA-Z]
• 匹配所有字母及-:[a-zA-Z\-]
• 匹配所有数字:[0-9] #切记区间内不可以直接写成数字范围,例如0-99,不能写成[0-99],ascii表中只有数字0-9
ret = re.findall("[12pP]x","2px 1xx Python pxoo")
print(ret)
ret = re.findall("[0-9]","2340dsfjskdjfk4dfd")
print(ret)
ret = re.findall("[a-z]","2340dsfjskdjJKJKHJHFGDRfk4dfd")
print(ret)
ret = re.findall("[A-Z]","2340dsfjskdjJKJKHJHFGDRfk4dfd")
print(ret)
ret = re.findall("[A-Za-z0-9\-]","2340dsfjskdjJKJKHJHFGDR-/fk4d\\fd")
print(ret)1.1 区间取反
区间取反就是在区间前面加上^
ret = re.findall(r"[^A-z][0-9]","234hjkhkdjf98908sdfsdnmxolie")
print(ret)2.匹配或
匹配a或b:a|b
msg = "四是四 十是十 十四是十四 四十是四十"
ret = re.findall("四|十",msg)
print(ret)
3.任意字符(占位符)
任意字符:“.”占位符
• 匹配任何(除\n外)的单个字符,它仅仅只以出现在方括号字符组以外
ret = re.findall("p.thon","Pxthon python p-thon pthon p\nthon")
print(ret)4.快捷方式
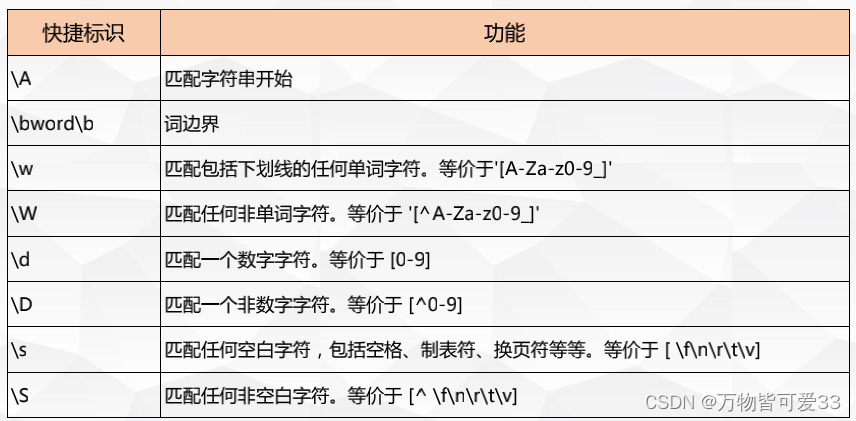
ret = re.findall(r"\ahello","hello world")
print(ret)
ret = re.findall(r"\bword\B","word123 word# abcword #word你好")
print(ret)
ret = re.findall(r"\dword\D","word123 word# abcword #word你好 12worda ")
print(ret)5.开始与结束
开始与结束:^,$
• 匹配以python开头:^python
• 匹配以python结尾:python$
ret = re.findall(r"^python","python is python")
print(ret)
ret = re.findall(r"python$","python is python")
print(ret)
ret = re.findall(r"^python$","python")
print(ret)6.正则重复
通配符:?,*,+

# ? 匹配前一项0次或1次
ret = re.findall("py?","pythonppyy")
print(ret)
# + 匹配前一项1次以上 1-n次
ret = re.findall("py+","pythonppyy")
print(ret)
# * 匹配前一项任意次 0-n次
ret = re.findall("py*","pythonppyy")
print(ret)
# {n,m} 匹配n到m次 {n,} n次以上 {,m} 0-m次
ret = re.findall("py{1,3}","pythonppyy")
print(ret)7.贪婪模式与非贪婪模式
贪婪模式与非贪婪模式
• 贪婪模式(.*): 匹配尽可能多的字符-默认模式
• 非贪婪模式(.*?): 尽可能匹配短的字符串 加个?就变成非贪婪模式 正则 \d*?
ret = re.findall("py*","pythonppyyyyyyyy")
print(ret)
msg = "cats and dogs,cats1 and dogs1"
print(re.findall(r"c.*?s",msg))8.正则分组
当使用分组时,除了可以获得整个匹配,还能够获得选择每一个单独组,使用 () 进行分组
8.1简单分组
group 默认参数是0 表示输出整个匹配字符串
参数n (n>0) 输出第几个组的匹配字符串
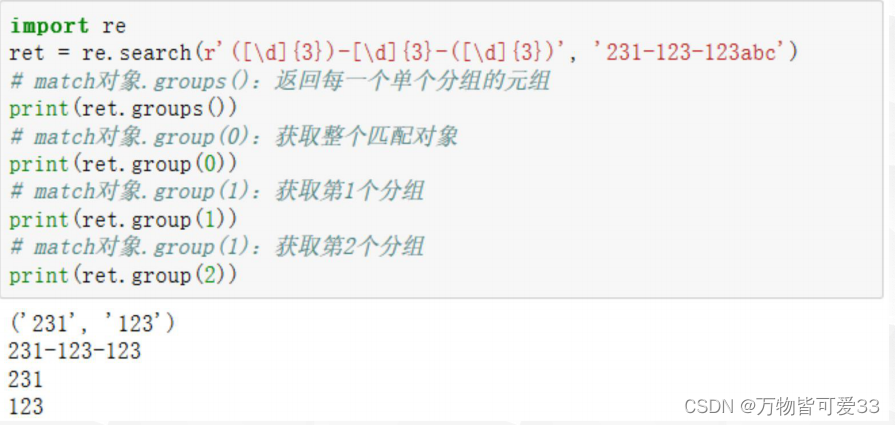
8.2分组向后引用
msg = "tel:172-7572-2991"
ret = re.search(r'(\d{3})-(\d{4})-\2',msg)
print(ret.group())
###输出的结果为:msg = "tel:172-7572-7572"8.3捕获分组与非捕获分组
捕获分组
分组之后匹配到的数据会放在内存里,并且给定一个从1开始的索引
捕获分组是可以进行分组向后引用
非捕获分组 (?:正则表达式)
只分组 不捕获,就是匹配到的分组数据不放在内存里
非捕获分组不能使用分组向后引用
msg = "tel:172-7572-7572"
ret = re.search(r'(?:\d{3})-(\d{4})-\1',msg)
print(ret.group())
print(ret.group(1))如果有捕获分组,findall只会匹配捕获分组里的内容
msg = "tel:172-7572-7572"
ret = re.findall(r'(?:\d{3})-(\d{4})-\1',msg)
print(ret)8.4命名分组(?P<名字>正则表达式)
msg = "tel:173-7572-7572"
ret = re.search(r'(?P<first>\d{3})-(\d{4})-\2',msg)
print(ret.group())
print(ret.group("first"))
print(ret.groupdict())四.正则标记-第三个参数
1.第三个参数

msg = "you jump, i jump"
#对大小写不明感的标记
ret = re.findall(r"jump", msg, re.I)
print(ret)
多行模式 影响^ 和 $
msg = """YOU JUMP, I JUMP2
you jump, i jump"""
ret = re.findall(r"^you jump, i jump$", msg, re.I|re.M)
print(ret)
#re.S 让.匹配任意字符,包括换行符
msg = """YOU JUMP, I JUMP2
you jump, i jump"""
ret = re.findall(r"^you.*jump$", msg, re.I|re.S)
print(ret)
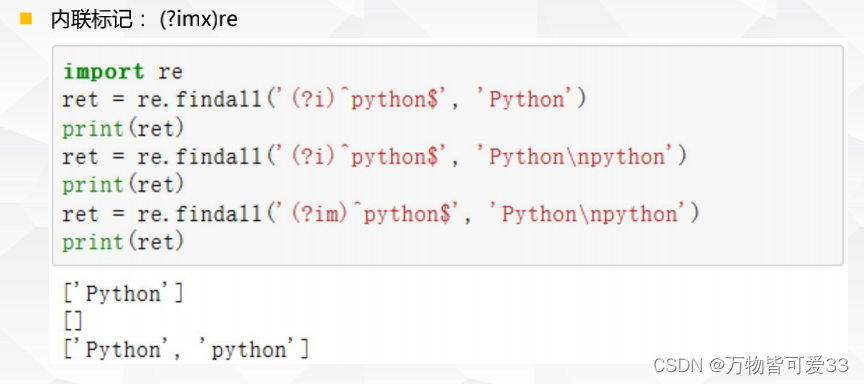
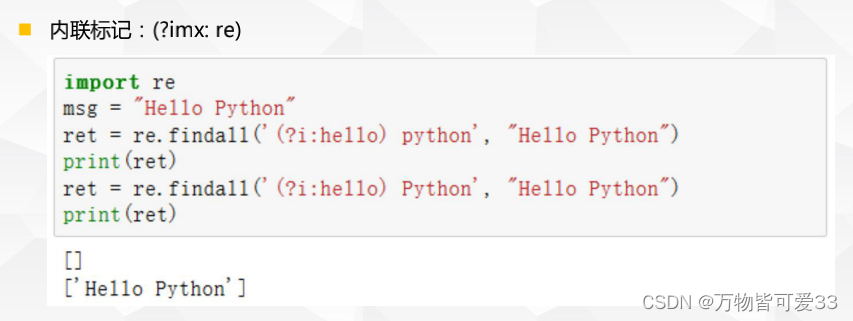
2.内联标记

五.正则表达式断言
正则表达式的断言分为:先行断言(lookahead)和后行断言(lookbehind)
零宽表示不占用匹配宽度,用来确定位置
正则表达式的先行断言和后行断言一共有4种形式:
(?=pattern) 零宽正向先行断言(zero-width positive lookahead assertion)
• 代表字符串中的一个位置,紧接该位置之后的字符序列能够匹配pattern。
(?!pattern) 零宽负向先行断言(zero-width negative lookahead assertion)
• 代表字符串中的一个位置,紧接该位置之后的字符序列不能匹配pattern。
(?<=pattern) 零宽正向后行断言(zero-width positive lookbehind assertion)
• 代表字符串中的一个位置,紧接该位置之前的字符序列能够匹配pattern。
(?<!pattern) 零宽负向后行断言(zero-width negative lookbehind assertion)
• 代表字符串中的一个位置,紧接该位置之前的字符序列不能匹配pattern。
• 零宽
• ^python
• 正向、负向
• 正向:匹配(?=pattern)/(?<=pattern)
• 负向:不匹配(?!pattern)/(?<!pattern)
• 先行、后行
• 先行:向后匹配(?=pattern)/(?!pattern)
• 后行:向前匹配(?<=pattern)/(?<!pattern)
str1 = "红鲤鱼与绿鲤鱼与驴"
print(re.findall(r".鲤鱼(?=与驴)", str1))
print(re.findall(r".鲤鱼(?!与驴)", str1))
print(re.findall(r"(?<=红)鲤鱼..", str1))
print(re.findall(r"(?<!红)鲤鱼..", str1))六.练习
1、验证ipv4地址 合法的ip地址 1-255.1-255.1-255.1-255
import re
while True:
ip = input("请输入要验证的地址: ")
ret = re.compile("^((25[0-5]|2[0-4]\d|1?\d\d?)\.){3}(25[0-5]|2[0-4]\d|1?\d\d?)$")
if ret.findall(ip):
print("正确")
else:
print("错误")2.验证邮箱地址, 邮箱地址为126或者qq或者163
while True:
mail = input("请输入一个邮箱(按q退出):")
if re.findall("^[A-Za-z0-9]+@(qq|126|163)\.com$", mail):
print(f"{mail}是一个合法的邮箱")
elif mail == "q":
break
else:
print(f"{mail}不是一个合法的邮箱!")3、msg="comy@xx.comcom123@qq.comaaa@126.combbb@163.comcc@abc.com"
#--- 爬取正确的126 163 qq 邮箱
#---com123@qq.com aaa@126.com bbb@163.com
msg="comy@xx.comcom123@qq.comaaa@126.combbb@163.comcc@abc.com"
print(re.findall(r"(?:\.com)?(\w+@(?:qq|163|126)\.com)", msg))4.从msg中截取出正确的ip地址
msg = """
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
inet6 ::1/128 scope host
valid_lft forever preferred_lft forever
2: ens33: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc fq_codel state UP group default qlen 1000
link/ether 00:0c:29:a2:f8:96 brd ff:ff:ff:ff:ff:ff
inet 192.168.0.103/24 brd 192.168.0.255 scope global dynamic noprefixroute ens33
valid_lft 86382sec preferred_lft 86382sec
inet6 fe80::5a57:c3e5:6e36:230/64 scope link noprefixroute
valid_lft forever preferred_lft forever
"""
print(re.findall(r"(?<=inet)\s\d*\.\d*\.\d*\.\d*/\d*",msg))
5.爬取出百度官网的图片
"""author: xieshan
data: 2022/6/12
project: 下载图片.py
"""
import requests
import re
url = 'https://www.baidu.com'
html = requests.get(url) #得到一个Response对象,并不是网页的源代码
#查看网页源代码的两种方式:.text属性和.content属性
#方法一:
#print(html.text) #.text返回文本信息
#方法二:
# html_bytes = html.content #属性.content用来显示bytes型网页的源代码
# html_str = html_bytes.decode() #属性.decode()用来把bytes型的数据解码为字符串型的数据,默认编码格式UTF-8
img = re.findall(r'(?<=src=//).*(?=\swidth)',html.text)
#print(img)
x = 0
for i in img:
pic = requests.get('https://'+i)
with open(f"image{x+1}.png", "wb") as f:
f.write(pic.content)
x += 1
print(f"第{x}张")
print("下载完毕")














 15万+
15万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









