







文章目录
1. 简介

论文:https://arxiv.org/pdf/1904.05298v1.pdf
代码:https://github.com/wabyking/qnn.git
2. 动机
2.1 启发
量子物理认为微观粒子可以同时处于不同的状态(量子叠加),这种有别于经典物理的常识,比如在没有观测之前,人们难以想象一个同时处于死了和或者的猫。不仅如此,一对纠缠粒子可以在相聚很远的时候,其中一个粒子的测量的结果可以影响到与之纠缠的另外一个粒子。
从量子物理发展来描述物理系统中的不确定的数学语言,是否对语言的形式化描述也有所裨益?这是本文关心的问题。在语言本身,词语存在一些不确定性,比如 apple 这个英文单词可以是一种水果,也可以一个生产 iPhone 和 Mac 的公司。如果把水果和生产 iPhone 和 Mac 的公司定义成基本语义单元,那么 apple 这个词就可以认为是这些基本语言单元的叠加态。
因此本文提出来一种基于复数表达的可解释性的匹配网络,源自量子力学中概率驱动网络来做预测。本质上思路可分为两点:
- 由量子概率驱动网络来做预测
- 在希尔伯特空间状态来表达不同粒度的语言单元。
关于希尔伯特,其本质就是复数表达域。空间关系见下图,可以看到欧式空间和希尔伯特空间都属于内积空间。
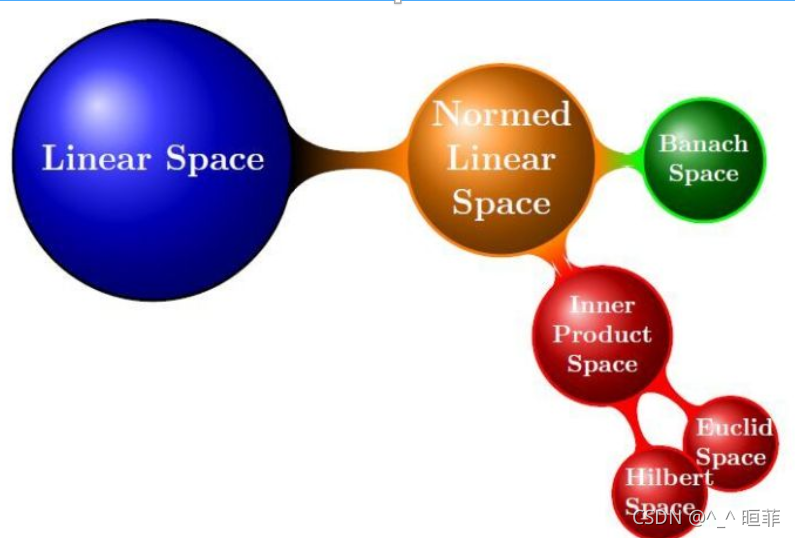
所提到的可解释性体现在两方面:
- 模型怎么工作
- 神经网络学习到了什么?
2.2 知识补充
现实中物理可实现的信号都是实信号,实信号的频谱具有共轭对称性,即正负频谱的幅度相等,相位相反。如果只取信号的正频部分 z ( t ) z(t) z(t),则 z ( t ) z(t) z(t)称为信号
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









