







在Prometheus的整体方案中,告警管理功能主要通过Alertmanager来完成,本文将接着上篇,讲解使用Alertmanager来实现警报的发送与管理 。
1、Alertmanager简介
Alertmanager作为一个独立的组件,负责接收并处理来自Prometheus Server(也可以是其它的客户端程序)的告警信息。Alertmanager可以对这些告警信息进行进一步的处理,比如当接收到大量重复告警时能够消除重复的告警信息,同时对告警信息进行分组并且路由到正确的通知方。
Alertmanager内置了对邮件,Slack等多种通知方式的支持,同时还支持通过Webhook的方式接入企业微信、钉钉等国内IM工具。
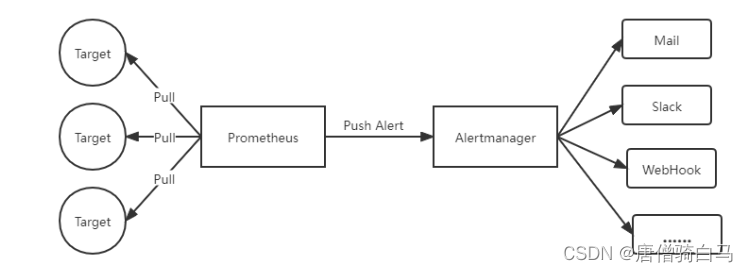
Alertmanager除了提供基本告警通知能力以外,还具有以下几个特点:
1.1 分组
分组机制可以将相同性质的警报合并为一个通知。比如在某些故障场景中,可能导致大量的告警被同时触发,在这种情况下分组机制可以将这些被触发的告警合并为一个告警通知,避免一次性接受收大量的通知信息,而无法对问题进行快速定位。
例如:当一台宿主机上运行着数十个虚拟机,如果机器发生网络或硬件故障,运维人员可能收到数十个告警,包括物理机与上面的所有虚拟机。而逐个查看这些故障本身是个耗时的工作,也容易导致对主要问题的忽略。
作为告警接收人,我们希望可以在一个通知中就能查看到受影响的所有实例信息,这时可以按照告警名称或所属宿主机对告警进行分组,而将这些告警合并到一个通知中查收。
告警分组功能可以通过Alertmanager的配置文件进行配置。
1.2 抑制
抑制是指当某一告警发出后,可以停止重复发送由此告警引发的其它告警的机制。
例如:当集群不可访问时触发了一次告警,通过配置Alertmanager可以忽略与该集群有关的其它所有告警。这样可以避免接收到大量与实际问题无关的告警通知。
抑制机制同样通过Alertmanager的配置文件进行设置。
1.3 静默
静默提供了一种简单的方法对特定的告警在特定时间内进行静音处理,它根据标签进行匹配。如果Alertmanager接收到的告警信息符合静默的配置,它将不会发送告警通知。静默功能适合在机器进行维护等场景下,暂时屏蔽告警通知[也就是维护窗口]。
静默设置需要在Alertmanager的Wer页面上进行设置。
2、安装配置
Alertmanager和Prometheus Server一样均采用Golang实现,并且没有第三方依赖。一般来说我们可以通过以下几种方式来部署Alertmanager:二进制包、容器以及源码方式安装。
使用二进制包部署AlertManager,下载地址https://github.com/prometheus/alertmanager/releases
tar zxvf alertmanager-0.15.3.linux-amd64.tar.gz -C /usr/local/
cd /usr/local
mv alertmanager-0.15.3.linux-amd64/ alertmanager
注:amtool是一个Alertmanager管理工具,支持用命令行方式进行管理。
查看版本号验证安装是否正常

3、配置介绍
Alertmanager与Prometheus Server一样,也是通过yml格式的配置文件进行配置。下面是一个基本的配置文件模板:
global:
resolve_timeout: 3m
smtp_smarthost: 'localhost:25'
smtp_from: 'devops@example.com'
smtp_require_tls: false
templates:
- '/etc/alertmanager/template/*.tmpl'
route:
receiver: 'admin'
group_by: ['alertname']
group_wait: 20s
group_interval: 10m
repeat_interval: 3h
receivers:
- name: 'admin'
email_configs:
- to: 'admin@example.com'
该配置文件总共定义了四个模块,global、templates、route和receivers。
- 全局配置(global):用于定义一些全局的公共参数,如全局的SMTP配置,Slack配置等内容;
- 模板(templates):用于定义告警通知时的模板,如HTML模板,邮件模板等;
- 告警路由(route):根据标签匹配,确定当前告警应该如何处理;
- 接收人(receivers):接收人是一个抽象的概念,它可以是一个邮箱也可以是微信,Slack或者Webhook等,接收人一般配合告警路由使用;
- 抑制规则(inhibit_rules):合理设置抑制规则可以减少垃圾告警的产生
global
用于定义Alertmanager的全局配置。
在示例中我们只配置几个参数,其中resolve_timeout定义持续多长时间未接收到告警标记后,就将告警状态标记为resolved。而smtp_smarthost指定SMTP服务器地址,smtp_from定义了邮件发件的的地址,smtp_require_tls配置禁用TLS的传输方式。
templates
用于指定告警通知时的模板,如邮件模板等。
由于Alertmanager的信息可以发送到多种接收介质,如邮件、Slack等,我们通常需要能够自定义警报所包含的信息,这个就可以通过模板来实现。
限于篇幅原因,相关模板的配置方式本文不做介绍,有兴趣的朋友可上官网查看:https://prometheus.io/docs/alerting/latest/notifications/。
route
用于定义Alertmanager接收警报的处理方式,根据规则进行匹配并采取相应的操作。
路由是一个基于标签匹配规则的树状结构,所有的告警信息都会从配置中的顶级路由(route)进入路由树。从顶级路由开始,根据标签匹配规则进入到不同的子路由,并且根据子路由设置的接收者发送告警。在示例配置中只定义了顶级路由,并且配置的接收者为admin,因此,所有的告警都会发送给到admin的接收者。
group_by用于定义分组规则,前面讲过Alertmanager支持告警分组功能,这里使用告警名称做为规则,满足规则的告警将会被合并到一个通知中;group_wait配置分组等待的时间间隔,在这个时间内收到的告警,会根据前面的规则做合并;group_interval定义相同group间发送告警通知的时间间隔;repeat_interval用于定义重复警报发送间隔,默认为3小时。
receivers
用于定义接收者的地址信息。
由于我们示例配置是邮件告警的方式,这里email_configs参数配置相关的邮件地址信息,另外还支持wechat_configs、webhook_configs等方式。
4、启动alertmanager
nohup ./alertmanager &
用户也在启动Alertmanager时使用参数修改相关配置。–config.file用于指定alertmanager配置文件路径,–storage.path用于指定数据存储路径。
查看运行状态
Alertmanager启动后可以通过9093端口访问,http://192.168.75.160:9093/#/alerts
5、Prometheus关联Alertmanager
Prometheus的配置文件中,alerting模块用于配置Alertmanager地址。当配置完成后,Prometheus会将触发告警规则的警报发送到Alertmanager。
# Alertmanager configuration
alerting:
alertmanagers:
- static_configs:
- targets:
- 192.168.75.160:9093
# Load rules once and periodically evaluate them according to the global 'evaluation_interval'.
rule_files:
- /usr/local/prometheus/rules/*.rules
我们可以试着将上篇文章中的cpu告警规则调低,触发Prometheus告警规则来验证配置,此处我们改为CPU使用率大于1%触发告警。
[root@server prometheus]# cat rules/hoststats-alert.rules
groups:
- name: hostStatsAlert
rules:
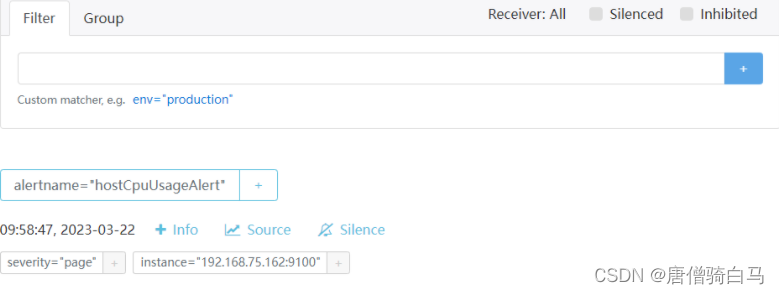
- alert: hostCpuUsageAlert
expr: sum(avg without (cpu)(irate(node_cpu_seconds_total{mode!='idle'}[5m]))) by (instance) > 0.45
for: 1m
labels:
severity: page
annotations:
summary: "Instance {{ $labels.instance }} CPU usgae high"
description: "{{ $labels.instance }} CPU usage above 85% (current value: {{ $value }})"
- alert: hostMemUsageAlert
expr: (node_memory_MemTotal_bytes - node_memory_MemAvailable_bytes)/node_memory_MemTotal_bytes > 0.45
for: 1m
labels:
severity: page
annotations:
summary: "Instance {{ $labels.instance }} MEM usgae high"
description: "{{ $labels.instance }} MEM usage above 85% (current value: {{ $value }})"
可以使用stress压测CPU,在Prometheus界面看到已成功触发告警规则
stress --cpu 4 --timeout 120
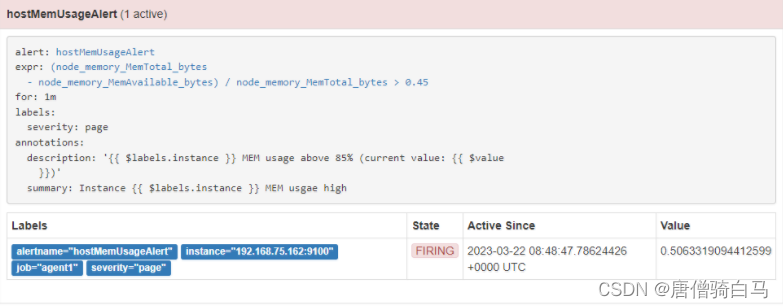
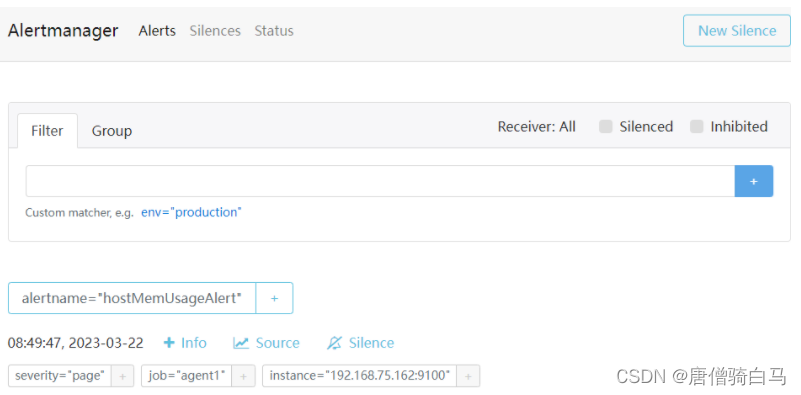
打开Alertmanager,可看到接收到的警报信息。
6、标签路由
在前面的示例中,我们只定义了一个顶级路由,这意味着所有的告警都由admin的接收者获取。但在实际环境中,告警的需求往往要比这个来得复杂。
例如:我们需要根据资源类型,将数据库的告警发送给DBA团队,将服务器的告警发送给运维团队;或者根据告警的严重级别,普通告警发送给技术人员,严重告警还需要通知到领导层等等。
对于此类需求,我们可以使用子路由的方式来实现,这些Route支持通过标签的方式进行匹配,并发送给相关的receiver。
route:
receiver: 'admin'
group_by: ['alertname']
group_wait: 20s
group_interval: 10m
repeat_interval: 3h
routes:
- receiver: 'database'
continue: true
match_re
type: mysql|mongodb
- receiver: 'devops'
continue: true
match:
type: server
receivers:
- name: 'admin'
email_configs:
- to: 'admin@example.com'
- name: 'database'
email_configs:
- to: 'database1@example.com |database2@example.com'
- name: 'devops'
email_configs:
- to: 'devops1@example.com |devops2@example.com'
在上面的这个示例中,我们配置了顶级路由,然后又根据不同的标签,定义了两个子路由和相关的接收者。其中continue的值如果为false,那么告警在匹配到第一个子节点之后就直接停止,如果continue为true,报警则会继续进行后续子节点的匹配。
对于告警信息的匹配,可以通过match和match_re进行标签的匹配,其中match匹配字符,而match_re支持正则表达式的方式。
7、静默告警
在某些情况下,我们可能希望对告警信息进行屏蔽,不收到相关的告警信息。例如对服务器进行关机维护、实例重启等场景。对此,Alertmanager提供了静默功能,用于处理此类需求。
静默功能的配置可以UI界面上进行,在页面上点击 "Slience"按键。
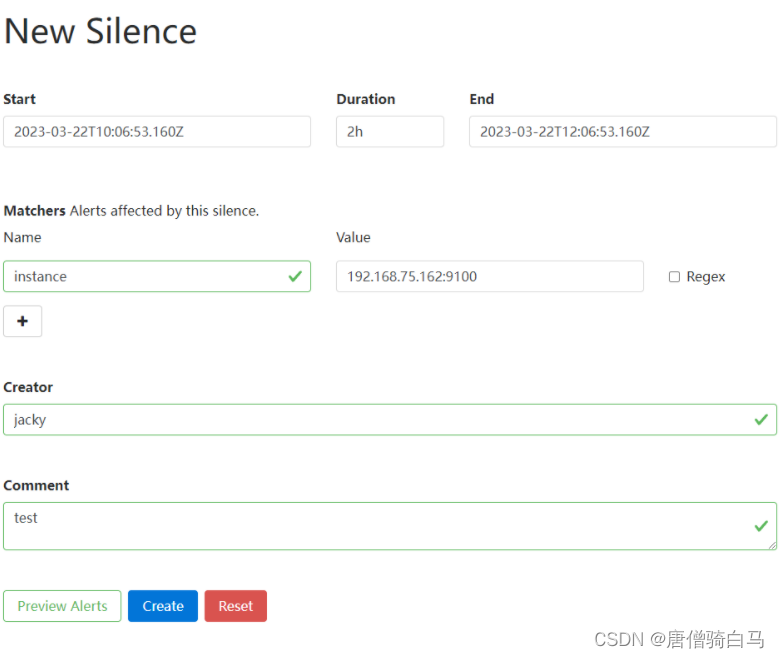
在"New Slience“页面进行配置,Matchers通过标签配置需要屏蔽的告警,如果勾上Regex,则可以在Value处使用正则表达式做匹配。在Start处填写开始时间,然后在End或Duration中填写一处即可,另外一个会自动计算出来。

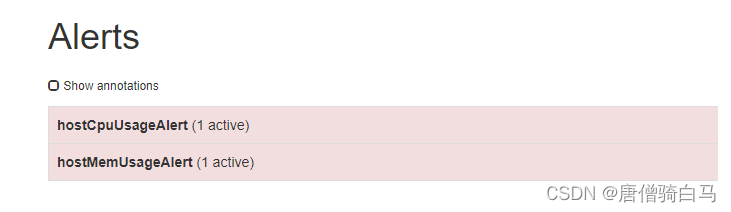
配置完成后,点击 "Create”完成创建。此时点击”Sliences”,可看到已经生成的Slience。当需要提前中止该Slience时,可点击旁边的Expire红色字体,让其过期即可。

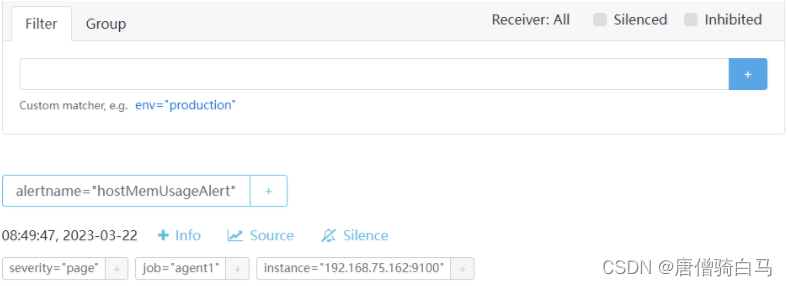
此时触发告警,虽然Prometheus的alerts页面有触发告警,但是Alertmanager的告警页面没有接收到告警,说明静默配置成功,取消静默后触发告警测试正常。
上一篇:Prometheus监控实战系列十二:配置告警规则
下一篇:Prometheus监控实战系列十四:Pushgateway















 6247
6247











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









