







循环依赖问题作为Spring中最经典的问题之一,常常会在面试中被问到,也是我们研读源码的一大阻碍,接下来就一一为大家解析此问题在Spring中的一个呈现。
一:什么是循环依赖?
1.如下图所示:
public class A {
private B b;
public B getB() {return b;}
public void setB(.B b) {this.b = b;}
}
public class B {
private A a;
public A getA() {return a;}
public void setA(A a) {this.a = a;}
}在我们平时的创建对象的时候,这样写确实没有什么问题,因为我们只需要A a = new A();就可以了,而在Spring中创建对象是一个极其复杂的过程,并不是简单的new一下,这里就涉及到了Bean的生命周期,而需要注意的是Spring中的依赖问题大致分为构造器依赖(构造函数)和set依赖(get set方法)。
-
构造器依赖
<bean id="testA" class="com.bean.TestA"> <constructor-arg index="0" ref="testB"></constructor-arg> </bean> <bean id="testB" class="com.bean.TestB"> <constructor-arg index="0" ref="testA"></constructor-arg> </bean>上图为XML配置文件,此依赖是无法解决的,因为构造器依赖是在创建对象之前的注入,当A对象在创建时需要注入B属性,发现B属性并没有被创建,之后去创建B对象,在创建B对象时发现需要注入属性A,这时发现A并没有被创建所以又重新创建A对象,这时就出现了循环依赖的问题,Spring会抛出一个异常。
throw new BeanCurrentlyInCreationException -
set依赖
在Spring中我们主要分析的是set的依赖注入问题,例如这样<bean id="testA" class="com.bean.TestA"> <property name="testB" ref="testB"></property> </bean> <bean id="testB" class="com.bean.TestB"> <property name="testA" ref="testA"></property> </bean>这个可以被解决一个关键的步骤是:setter依赖是在对象存在之后才会去注入属性,这时我们可能会有一个疑问------对象存在之后不就是属性已经注入了吗?不就是一个完整的对象了吗?(带着问题继续看..)
其实这个问题就涉及到了Spring的强大之处,大家都知道一个对象的创建必然离不开实例化和初始化的操作,而在Spring中实例化和初始化是分开进行,也就说是有在实例化后才进行初始化,这样就可以做到提前暴露正在创建的对象,正因为提前暴露的对象就为解决循环依赖提供了一个强有力的保证。
上文提到,Spring一些机制已经帮我们解决了一部分的循环依赖问题,而这个机制还把实例化和初始化分开进行操作,这个机制就是"三级缓存"
二:三级缓存
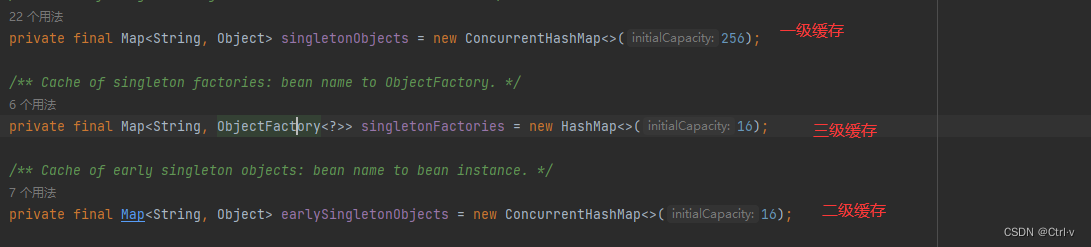
- 一级缓存:singletonObjects
存放完整的一个Bean对象-----经历了Bean完整的生命周期。
- 二级缓存:earlySingletonObjects
存放实例化之后原始对象的引用(半成品)。
- 三级缓存:singletonFactories
用于存放ObjectFactory对象工厂,来创建对象。
思考:大家看到这里可能对于循环依赖还是一头雾水,先不要着急,下面我会从代码中进行分析三级缓存的具体应用。
三:思路分析
- Bean创建过程大致分为一下几个步骤:
- Spring首先会去加载Bean的XML配置文件,得到BeanDefinition。
- 根据得到的BeanDefinition,去实例化Bean。
- 实例化完之后这个得到一个原始对象(暂时可以理解为一个半成品)。
- 调用popluateBean()方法,进行初始化属性填充的工作。
- 如果存在AOP代理,那么将会生成一个代理对象。
- 之后将代理对象生成的单例Bean,放进一级缓存(也就是singletonObjects),下次使用时直接从缓存池中得到。
对于Bean加载步骤还有很多,这里不一一介绍了,我们需要思考的是如果在第四步填充属性时发现属性并没有被创建(如上文配置文件中的情况),那么这个时候无法顺利初始化,为帮助大家理解,特整理下图:
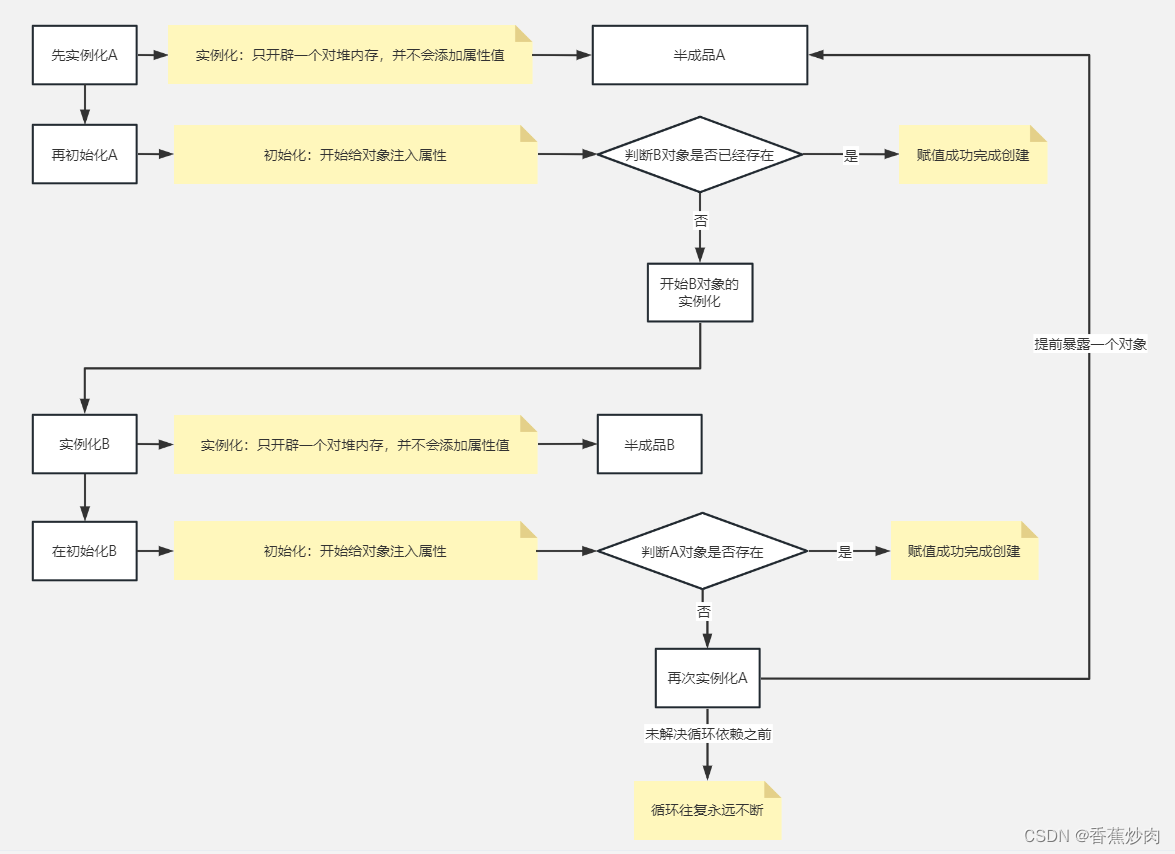
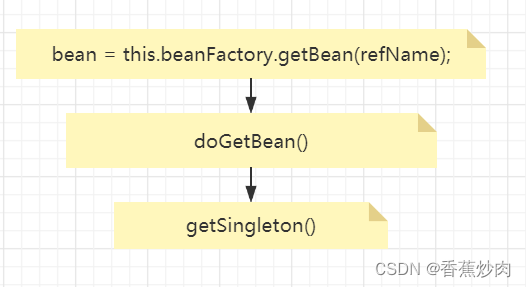
通过上图大家可以清晰的理解循环依赖的产生,而Spring解决循环依赖的办法就是提前暴露一个对象,也就是对象在未完成创建之前就暴露出来一个原始对象的引用,而对象开始创建时会通过getBean()方法进行获取,方法很复杂,这里拿出了几个比较重要去分析,其余的就不一一列出了,感兴趣的可以去下载源码查看。
//缓存中查找单例bean
Object sharedInstance = getSingleton(beanName);protected Object getSingleton(String beanName, boolean allowEarlyReference) {
// Quick check for existing instance without full singleton lock
//在一级缓存中进行一个查找
Object singletonObject = this.singletonObjects.get(beanName);
//判断一级缓存中是否存在但当前bean 或者当前bean是否在创建
if (singletonObject == null && isSingletonCurrentlyInCreation(beanName)) {
singletonObject = this.earlySingletonObjects.get(beanName);
if (singletonObject == null && allowEarlyReference) {
synchronized (this.singletonObjects) {
// Consistent creation of early reference within full singleton lock
singletonObject = this.singletonObjects.get(beanName);
if (singletonObject == null) {
singletonObject = this.earlySingletonObjects.get(beanName);
if (singletonObject == null) {
ObjectFactory<?> singletonFactory = this.singletonFactories.get(beanName);
if (singletonFactory != null) {
singletonObject = singletonFactory.getObject();
this.earlySingletonObjects.put(beanName, singletonObject);
this.singletonFactories.remove(beanName);
}
}
}
}
}
}
return singletonObject;
}
在此方法中"Object singletonObject = this.singletonObjects.get(beanName);"会在一级缓存中进行查找,如果没有找到返回null,而在下面的if条件中"isSingletonCurrentlyInCreation(beanName)"表示当前的bean是否在创建中,当这些条件不满足的时候直接返回。
// Create bean instance.
if (mbd.isSingleton()) {
//此处是一个匿名内部类
/**
* bean的加载定义其实是在传入ObjectFactory类型的参数singletofactory中定义的。
*/
sharedInstance = getSingleton(beanName, () -> {
try {
//ObjectFactory核心调用就是加载了creatBean的方法。
return createBean(beanName, mbd, args);
}
catch (BeansException ex) {
// Explicitly remove instance from singleton cache: It might have been put there
// eagerly by the creation process, to allow for circular reference resolution.
// Also remove any beans that received a temporary reference to the bean.
destroySingleton(beanName);
throw ex;
}
});
bean = getObjectForBeanInstance(sharedInstance, name, beanName, mbd);
}之后会进入CreatBean()方法,开始创建当前bean,
Object beanInstance = doCreateBean(beanName, mbdToUse, args);读到这里大家不难发现,在Spring中所有的实际业务逻辑方法都是以do开头的。
protected Object doCreateBean(String beanName, RootBeanDefinition mbd, @Nullable Object[] args)
throws BeanCreationException {
// Instantiate the bean.
//这个BeanWrapper 是用来持有创建出来的bean对象的
BeanWrapper instanceWrapper = null;
if (mbd.isSingleton()) {
//如果是单例对象 就从factorybean实例中移除当前的bean定义信息。(清除缓存)
instanceWrapper = this.factoryBeanInstanceCache.remove(beanName);
}
if (instanceWrapper == null) {
//根据执行的bean使用对应的策略创建新的实例,如 工厂方法,构造函数主动注入,简单初始化。
instanceWrapper = createBeanInstance(beanName, mbd, args);
}
//只是获得bean对象但是并没有注入属性
Object bean = instanceWrapper.getWrappedInstance();
Class<?> beanType = instanceWrapper.getWrappedClass();
if (beanType != NullBean.class) {
mbd.resolvedTargetType = beanType;
}
// Allow post-processors to modify the merged bean definition.
synchronized (mbd.postProcessingLock) {
if (!mbd.postProcessed) {
try {
//Autowried注解正是通过此方法实现诸如类型的预解析
applyMergedBeanDefinitionPostProcessors(mbd, beanType, beanName);
}
catch (Throwable ex) {
throw new BeanCreationException(mbd.getResourceDescription(), beanName,
"Post-processing of merged bean definition failed", ex);
}
mbd.postProcessed = true;
}
}
// Eagerly cache singletons to be able to resolve circular references
// even when triggered by lifecycle interfaces like BeanFactoryAware.
boolean earlySingletonExposure = (mbd.isSingleton() && this.allowCircularReferences &&
isSingletonCurrentlyInCreation(beanName));
if (earlySingletonExposure) {
if (logger.isTraceEnabled()) {
logger.trace("Eagerly caching bean '" + beanName +
"' to allow for resolving potential circular references");
}
//这边不去执行 lambada表达式 只有调用getobject 的时候才会执行
addSingletonFactory(beanName, () -> getEarlyBeanReference(beanName, mbd, bean));
}
// Initialize the bean instance.
Object exposedObject = bean;
try {
//填充属性值
populateBean(beanName, mbd, instanceWrapper);
exposedObject = initializeBean(beanName, exposedObject, mbd);
}
catch (Throwable ex) {
if (ex instanceof BeanCreationException && beanName.equals(((BeanCreationException) ex).getBeanName())) {
throw (BeanCreationException) ex;
}
else {
throw new BeanCreationException(
mbd.getResourceDescription(), beanName, "Initialization of bean failed", ex);
}
}
if (earlySingletonExposure) {
Object earlySingletonReference = getSingleton(beanName, false);
if (earlySingletonReference != null) {
if (exposedObject == bean) {
exposedObject = earlySingletonReference;
}
else if (!this.allowRawInjectionDespiteWrapping && hasDependentBean(beanName)) {
String[] dependentBeans = getDependentBeans(beanName);
Set<String> actualDependentBeans = new LinkedHashSet<>(dependentBeans.length);
for (String dependentBean : dependentBeans) {
if (!removeSingletonIfCreatedForTypeCheckOnly(dependentBean)) {
actualDependentBeans.add(dependentBean);
}
}
if (!actualDependentBeans.isEmpty()) {
throw new BeanCurrentlyInCreationException(beanName,
"Bean with name '" + beanName + "' has been injected into other beans [" +
StringUtils.collectionToCommaDelimitedString(actualDependentBeans) +
"] in its raw version as part of a circular reference, but has eventually been " +
"wrapped. This means that said other beans do not use the final version of the " +
"bean. This is often the result of over-eager type matching - consider using " +
"'getBeanNamesForType' with the 'allowEagerInit' flag turned off, for example.");
}
}
}
}
// Register bean as disposable.
try {
registerDisposableBeanIfNecessary(beanName, bean, mbd);
}
catch (BeanDefinitionValidationException ex) {
throw new BeanCreationException(
mbd.getResourceDescription(), beanName, "Invalid destruction signature", ex);
}
return exposedObject;
}
在doCreateBean方法对于解决循环依赖的问题,有两个方法比较重要,
instanceWrapper = createBeanInstance(beanName, mbd, args);是为了在堆内存中开辟一个空间(实例化),最终会返回一个Bean原始对象BeanReference(原始对象的引用,也就是上文提到的半成品)。而第二个方法就是
// Eagerly cache singletons to be able to resolve circular references
// even when triggered by lifecycle interfaces like BeanFactoryAware.
boolean earlySingletonExposure = (mbd.isSingleton() && this.allowCircularReferences &&
isSingletonCurrentlyInCreation(beanName));
if (earlySingletonExposure) {
if (logger.isTraceEnabled()) {
logger.trace("Eagerly caching bean '" + beanName +
"' to allow for resolving potential circular references");
}
//这边不去执行 lambada表达式 只有调用getobject 的时候才会执行
addSingletonFactory(beanName, () -> getEarlyBeanReference(beanName, mbd, bean));
}-
mbd.isSingleton():是否是单例。
-
this.allowCircularReferences:是否允许循环依赖。
-
isSingletonCurrentlyInCreation(beanName):是都是一个单例增量
protected void addSingletonFactory(String beanName, ObjectFactory<?> singletonFactory) {
Assert.notNull(singletonFactory, "Singleton factory must not be null");
synchronized (this.singletonObjects) {
//判断一级缓存是否存在beanName
if (!this.singletonObjects.containsKey(beanName)) {
//向三级缓存放东西
this.singletonFactories.put(beanName, singletonFactory);
//移除二级缓存的beanname
this.earlySingletonObjects.remove(beanName);
this.registeredSingletons.add(beanName);
}
}
}addSingletonFactory()三级缓存是首先判断一下一级缓存中是否有此对象如果没有则放进去三级缓存中并且移除二级缓存的bean,需要注意的是这时二级缓存没有Bean,(如下图所示)
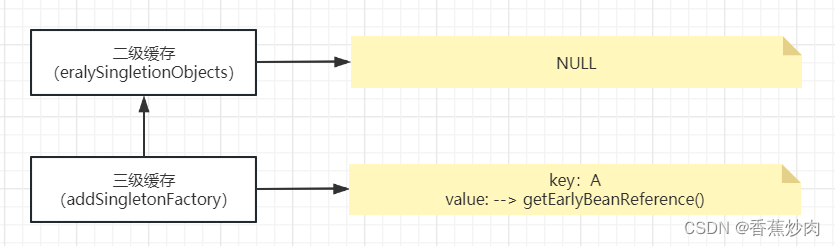
这时对象A就已经实例化完成,并且已经存在三级缓存中,实例化完成之后在初始化的时候doCreatBean()中实现了一个方法
Object exposedObject = bean;
try {
//填充属性值
populateBean(beanName, mbd, instanceWrapper);
exposedObject = initializeBean(beanName, exposedObject, mbd);
}popluateBean()方法中有一个applyPropertyValues(),再次方法去到了注入属性的name和value
String propertyName = pv.getName();
Object originalValue = pv.getValue();
//值传进来之后 进行一个相关的处理工作
Object resolvedValue = valueResolver.resolveValueIfNecessary(pv, originalValue);注入的是B对象所以propertyName="testB" originaValue = "B对象的引用"这些值作为参数传入resolveValueIfNecessary(pv, originalValue);
public Object resolveValueIfNecessary(Object argName, @Nullable Object value) {
// We must check each value to see whether it requires a runtime reference
// to another bean to be resolved.
//判断value的类型是否是RuntimeBeanReference
if (value instanceof RuntimeBeanReference) {
RuntimeBeanReference ref = (RuntimeBeanReference) value;
return resolveReference(argName, ref);
}
private Object resolveReference(Object argName, RuntimeBeanReference ref) {
try {
Object bean;
String refName = ref.getBeanName();
refName = String.valueOf(doEvaluate(refName));
if (ref.isToParent()) {
if (this.beanFactory.getParentBeanFactory() == null) {
throw new BeanCreationException(
this.beanDefinition.getResourceDescription(), this.beanName,
"Can't resolve reference to bean '" + refName +
"' in parent factory: no parent factory available");
}
//在没有找到b对象的情况下 进行getBean()
bean = this.beanFactory.getParentBeanFactory().getBean(refName);
}
else {
bean = this.beanFactory.getBean(refName);
this.beanFactory.registerDependentBean(refName, this.beanName);
}
if (bean instanceof NullBean) {
bean = null;
}
return bean;
}
catch (BeansException ex) {
throw new BeanCreationException(
this.beanDefinition.getResourceDescription(), this.beanName,
"Cannot resolve reference to bean '" + ref.getBeanName() + "' while setting " + argName, ex);
}
}最终会在resolveReference方法中实现一个语bean = this.beanFactory.getBean(refName);(大家牢记这个方法,这是解决问题的关键所在)这个是为了在beanFactory中进行一个查找,这时就看见了我们上文中提高的getBean(),递归调用而此方法执行代码在doGetBean()中直接进入,再次判断singletonObjects(一级缓存)B对象是否正在创建,并且判断该对象是正在创建。如果没有找到并且没有在创建则沿用上文中的操作直到B的实例化结束,到现在为止缓存是这样体现的: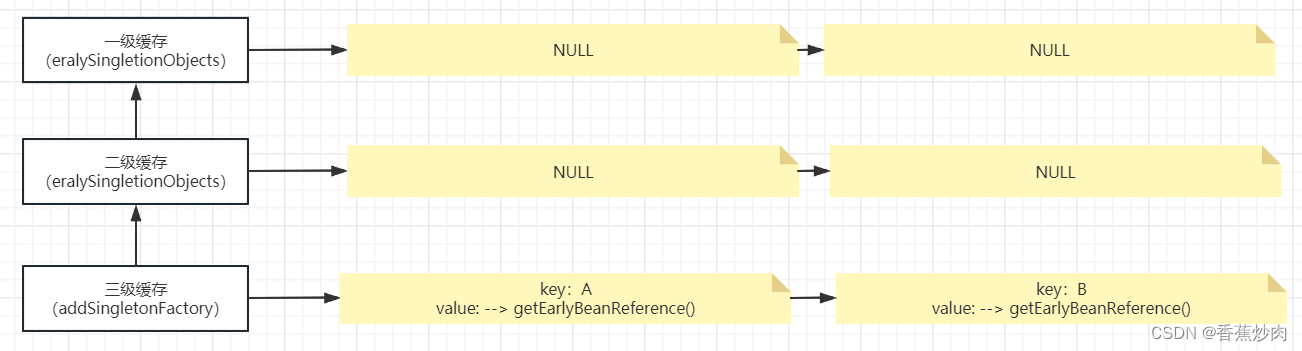
当B的实例化结束之后,开始初始化调用populateBean()注入A属性,沿用上文的逻辑:
需要注意的时候,再次调用getSingleton()方法去查找的时候,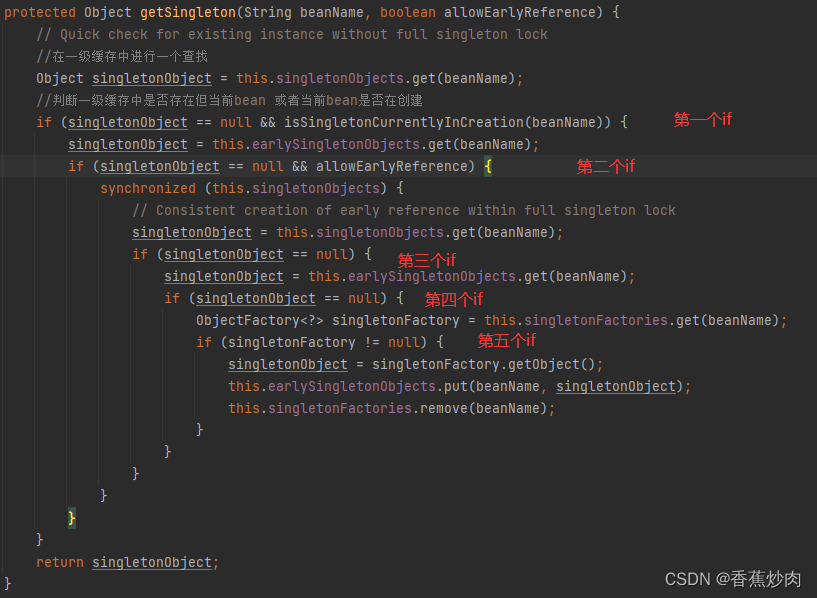
这时在singletonObjects(一级缓存)中查找依旧为null,可是区别之前的是现在的A对象是在被创建的过程当中,进入第一个if条件句中,第二个if条件在earlySingletonObjects(二级缓存),查找为空并且是一个早期的Bean引用(可以理解为在三级缓存中存储的半成品对象),这时意味着第三个和第四个if的条件也满足,最终进入三级缓存中寻找:
singletonObject = this.earlySingletonObjects.get(beanName);根据上文分析,三级缓存中存在A对象的引用,所以singletonObject !=null,进去最后一个if,得到一个ojbect(A对象)并把它存进去二级缓存中且移除掉三级缓存中A对象的信息。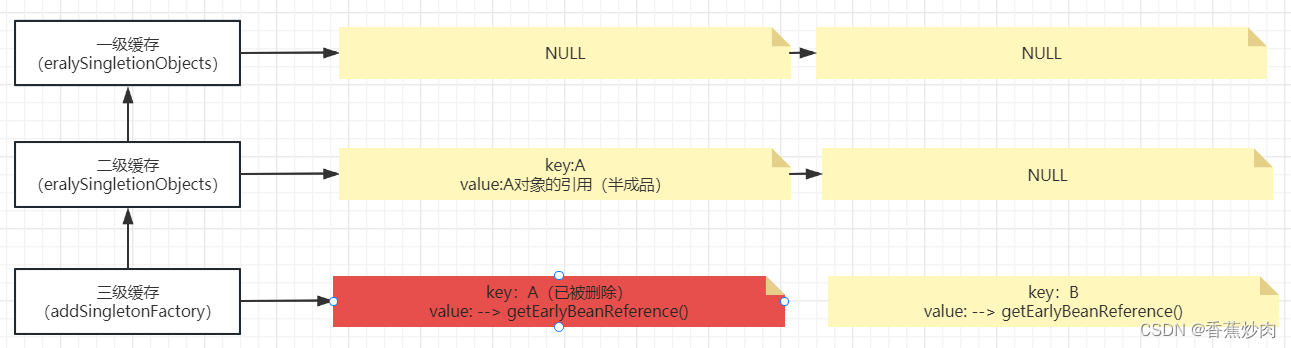
这时在BeanFactory中查找是有A对象的存在的,虽然是一个半成品(此时不要着急,接着看,结果马上呈现)
bean = this.beanFactory.getBean(refName);此时这里已经返回了A对象,也就是说B对象在注入属性A的时候成功了,虽然现在注入B对象中的A属性是一个半成品,这时大家已经能够熟悉下图的一个流程了,
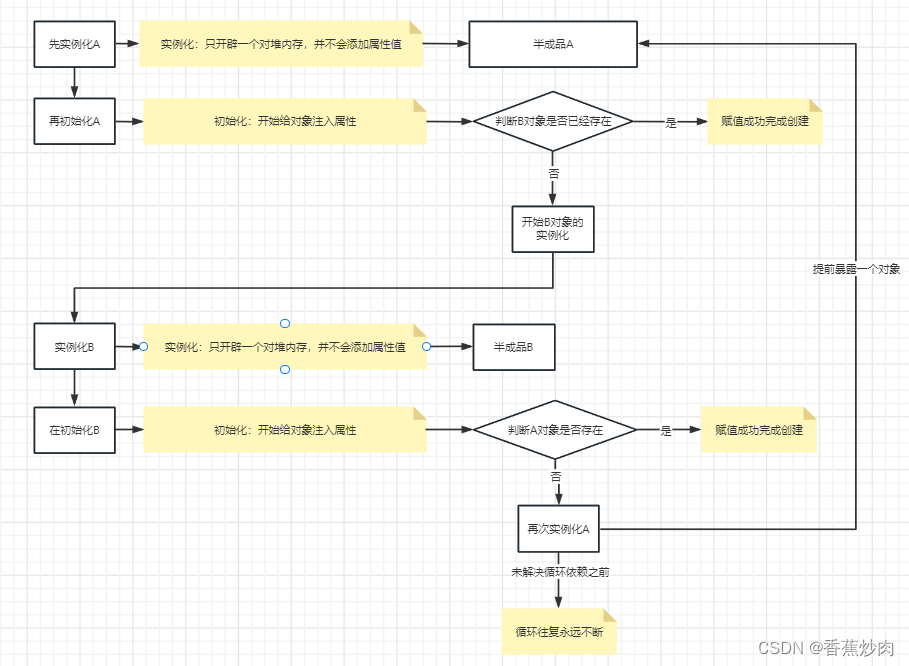
思考:走到这里B对象已经完成创建了,也就是实例化和初始化全部结束,B已然成为了一个完整的对象,回想起我们是如何创建的,不难发现是为了在给A对象注入属性B的时候发生的。这是只有A对象还是一个半成品,而注入A对象的B属性已经存在接下来的实现就浮出了水面。
不知道大家有没有发现在我们creatBean方法的时候,有一个getSingleton方法作为Lambda表达式传入 。而在此方法中有一个极其重要的方法addSingleton(beanName, singletonObject);
protected void addSingleton(String beanName, Object singletonObject) {
synchronized (this.singletonObjects) {
this.singletonObjects.put(beanName, singletonObject);
this.singletonFactories.remove(beanName);
this.earlySingletonObjects.remove(beanName);
this.registeredSingletons.add(beanName);
}
}首先将已经创建完成的B对象放入一级缓存(singletonObjects)中,移除三级缓存(singletonFactories)和二级缓存中(earlySingletonObjects)的内容。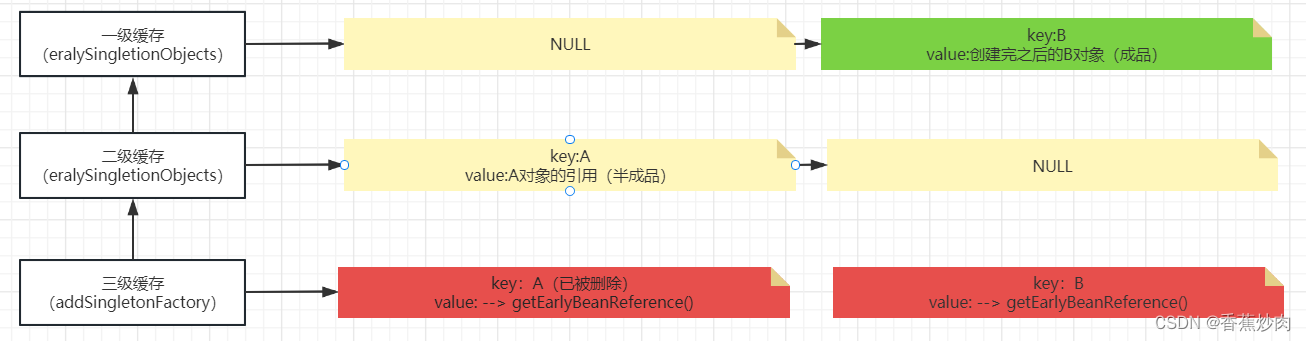
由于我是在给A对象初始化的时候开始创建B对象的,而这时由于B对象已经找到,所以返回到A对象初始化的时候,之后A对象创建成功,并将三级缓存(singletonFactories)和二级缓存中(earlySingletonObjects)的内容移除掉。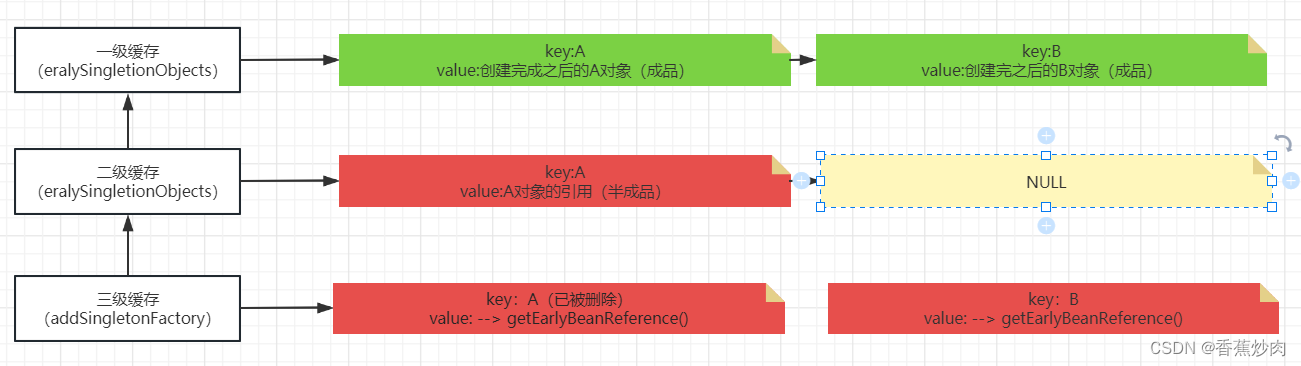
此刻!!!!!所有的对象创建完毕,当我们下次使用时候不必在重新创建,只需要从一级缓存中调取即可,至此循环依赖问题已被解决。
四:总结
总结几个可能会在面试中问到问题:
- 如果只用一级缓存能不能解决问题?
- 答案是:不能,有我在整个处理过程中,缓存中存放的是成品或者半成品对象,如果只有一级缓存,那么就有可能混乱,那么在调取的时候可能出现取到半成品的情况,由于半成品是不可以使用的,所以导致出现问题。
- 只使用二级缓存能不能解决问题?为什么要使用三级缓存?
- 答案是:只使用二级缓存是可以解决循环依赖的问题的,但是我们都知道到在Spring中有两大特点:IOC(控制反转)和AOP(动态代理),所以三级缓存的存在就是为了解决AOP代理的问题。(此问题会在后续文章中更新,感兴趣的可以关注一下呦...)
- 多例情况下的循环依赖可以被解决吗?
- 答案是:不可以,因为在Spring中,prototype作用域的bean,Spring是无法完成依赖注入的,因为Spring容器不进行缓存'prototype'作用域的bean,因此无法做到提前暴露一个正在创建当中的bean。
















 296
296











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











