







由于这是我自己随手记录的,所以显得比较乱,但是步骤基本都有,排版就以后再说。
重试一次,自定义jar包程序运行。
1.建立scala项目
2.添加spark下的jar包依赖【usr/local/spark/jars】,当然也有scala的sdk,一般我这边已经有了
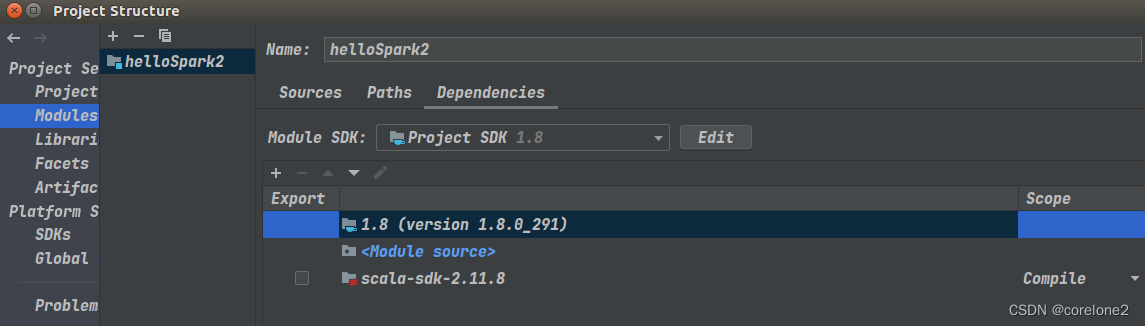
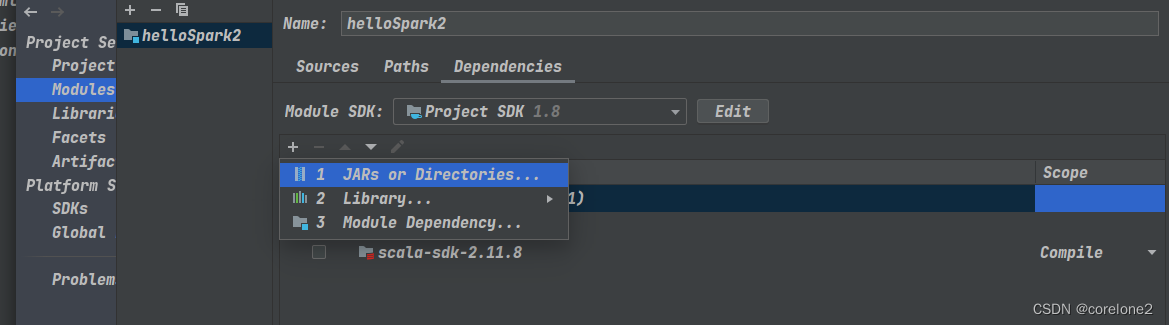
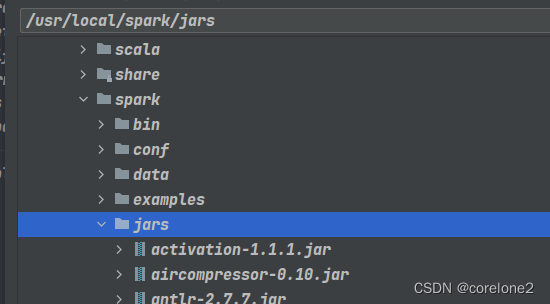
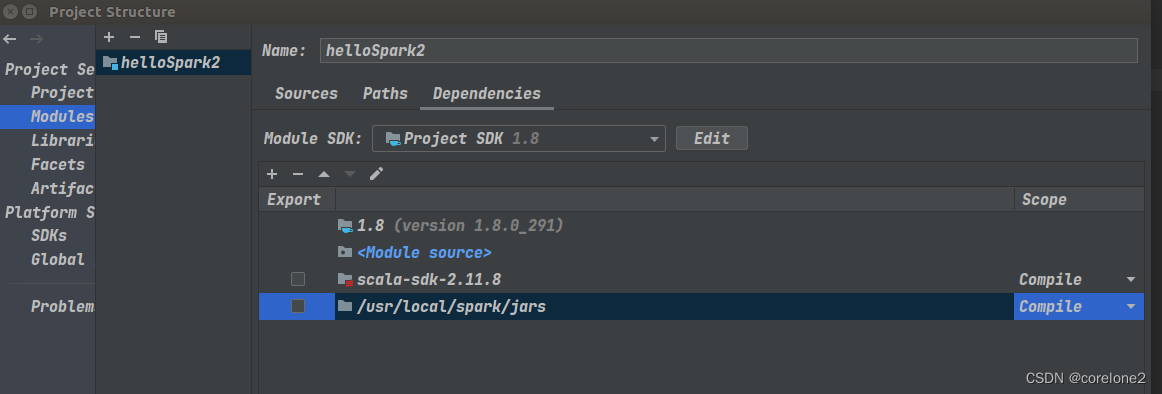
写程序:我终于,可以从头到尾,自己写下来所有的API。并且运行成功。
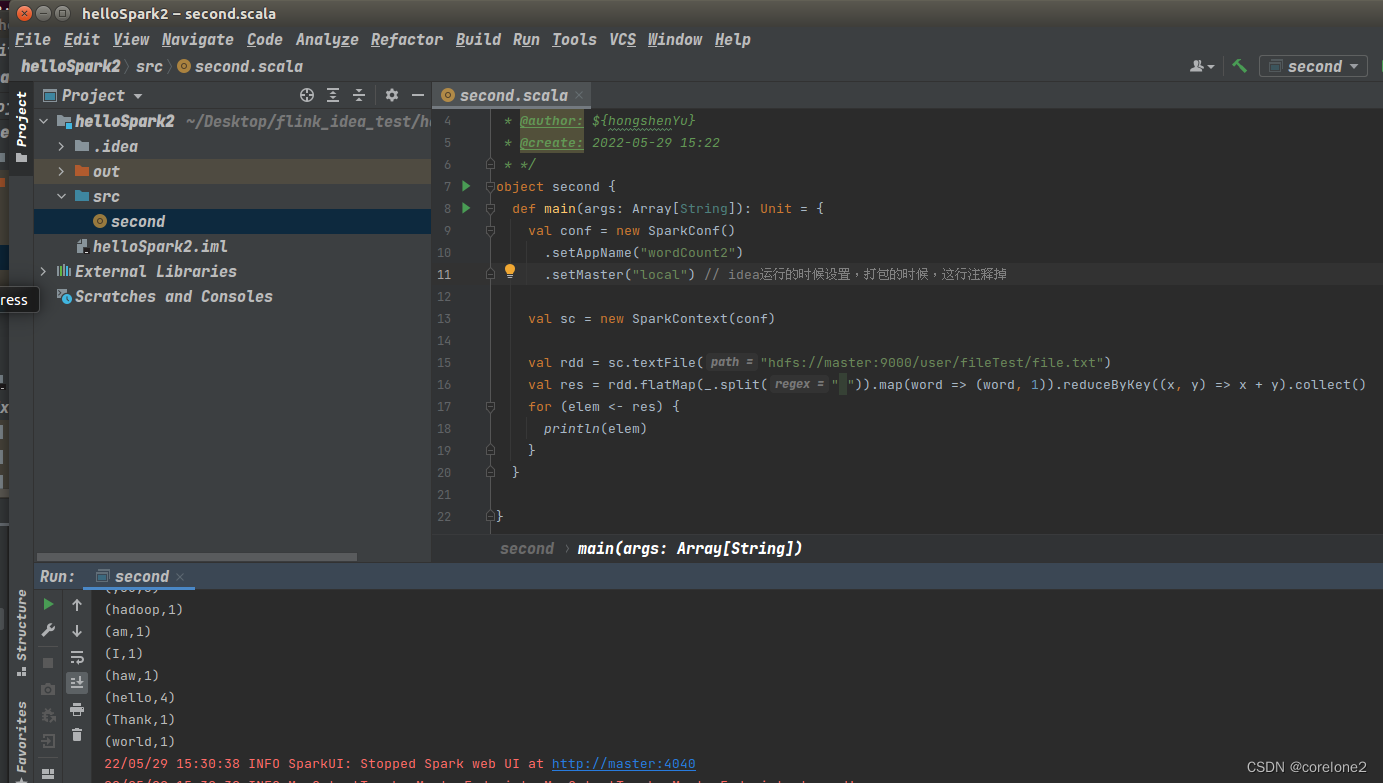
接下来开始打包,先注释掉,setMaster(“local”)
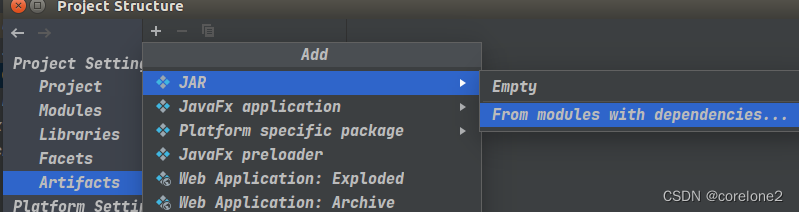
main class,这边自动给我识别,
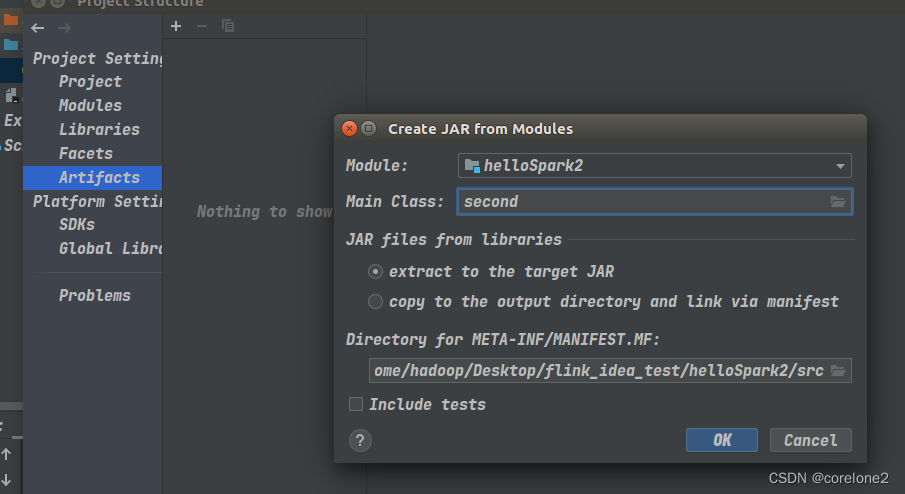
然后删除,除项目jar包以外的所有依赖,【集群环境里面有,所以不需要】
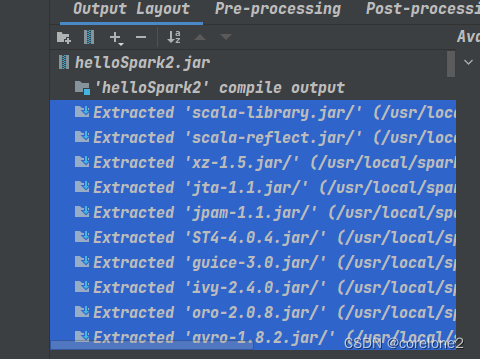
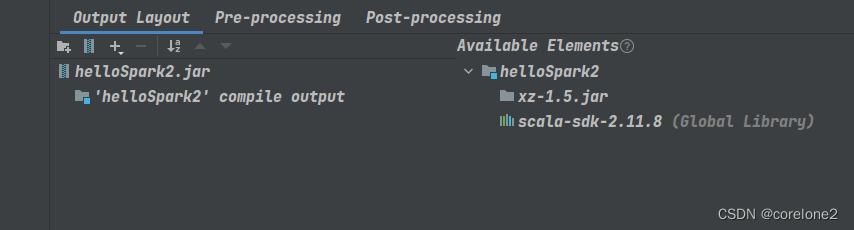
右边的不用动,就删左边的。
然后就开始打包。
首先是:build -> build Artifact -> build[rebuild 用于改了程序之后的第二次等]
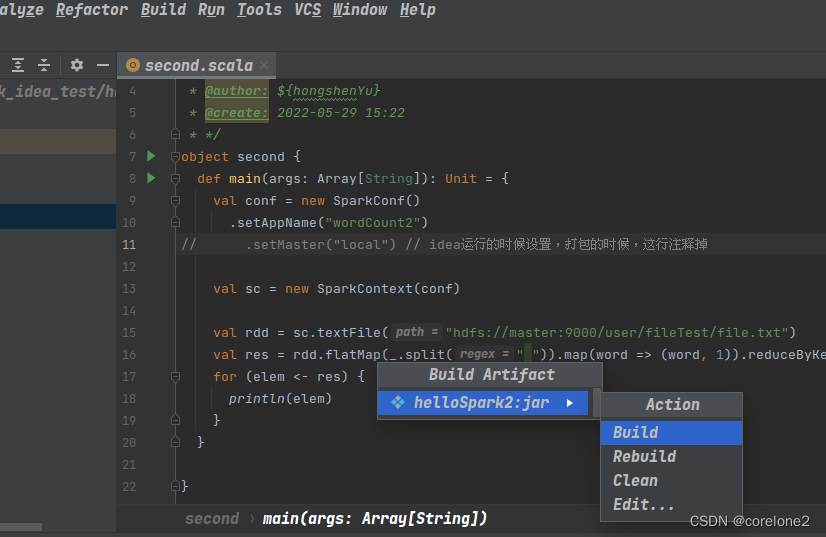
成功生成jar包:
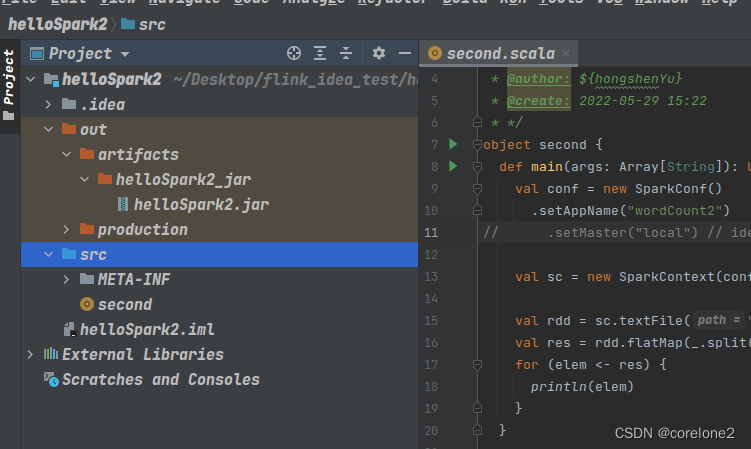
然后,我这边拷贝jar包到已经打开了,集群环境的master机器上。
【即使我先打开的start-master.sh,start-slaves.sh,后打开的start-all.sh,也没事】
选择放到spark的examples目录的jar包下,这样要是出错了,顺带可以跑一跑,自带的计算PI的jar包。
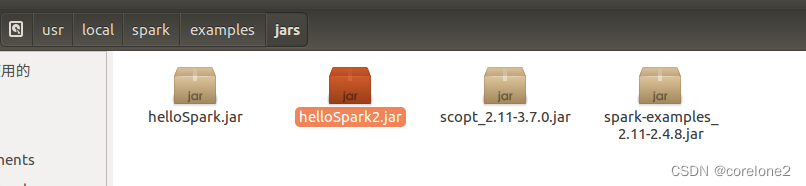
然后开始运行:jar包目录下执行命令:
【即使我先打开的start-master.sh,start-slaves.sh,后打开的start-all.sh,也没事】
./bin/spark-submit --class second --master spark://master:7077 examples/jars/helloSpark2.jar

运行成功:
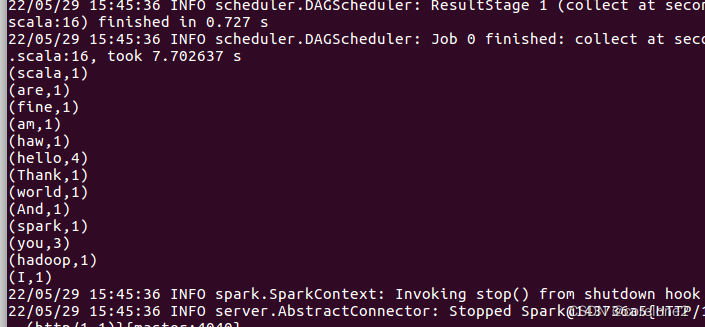
到这边集群上,运行自定义的jar包,勉强算是成功了。
再试一下命令: Yarn-client 模式,运行,成功了。
bin/spark-submit \
--class second \
--master yarn \
--deploy-mode client \
examples/jars/helloSpark2.jar
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-NM3GSE4L-1653811717201)(C:\Users\dell\AppData\Roaming\Typora\typora-user-images\image-20220529155522694.png)]](https://img-blog.csdnimg.cn/bbe2963f6bf645f898002d24c6574272.png)
试一下,yarn-cluster,成功了
bin/spark-submit \
--class second \
--master yarn \
--deploy-mode cluster \
examples/jars/helloSpark2.jar
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-b0kORiTT-1653811717201)(C:\Users\dell\AppData\Roaming\Typora\typora-user-images\image-20220529160705072.png)]](https://img-blog.csdnimg.cn/674503bce6aa4b8e8b830f39242b5749.png)
但是yarn-cluster集群模式下,不能在客户端上看到输出,只能去日志中看,或者web UI 上看。master:8088。
参考博客:
- https://blog.csdn.net/sinat_36226553/article/details/103302969
- https://blog.csdn.net/quitozang/article/details/77833390















 1553
1553











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









