







文章基本上都是来源于redis官网所整理的!!!
redis中文官网:https://www.redis.com.cn/tutorial.html
一、Redis简介
Redis 是一个开源(BSD 许可)的内存数据结构存储,可用作数据库、缓存、消息代理和流引擎。其中基于value值 提供了多种数据结构。
常用的有五种: strings、hashes、lists、sets、Sorted sets(一般我们叫的时候是不带s的,但是官网介绍当中是带着s的)
Redis的五种数据类型详解:https://blog.csdn.net/weixin_43888891/article/details/125837793
不常用的有四种: bitmaps、hyperloglogs、geospatial indexes(Redis 3.2 版本新增加的数据结构) 、streams(Redis 5.0 版本新增加的数据结构)
每一种数据结构都有他独特的作用,当我们把所有的都掌握了,我们就可以根据实际开发当中来进行自由选择使用。
二、四种特殊的数据类型
1、bitmaps
bitmaps本质其实不是实际的数据类型,而是在 String 类型上定义的一组面向位的操作(所谓的位就是二进制当中0或者1就是占用了一位)。由于字符串是二进制安全 blob,它们的最大长度为 512 MB,因此它们适合设置最多 2^32 个不同的位。
位图的最大优势之一是它们在存储信息时通常可以极大地节省空间。例如,在不同用户由增量用户 ID 表示的系统中,仅使用 512 MB 内存就可以记住 40 亿用户的单个位信息(例如,知道用户是否想要接收新闻通讯)。
统计用户信息,活跃,不活跃!登录、未登录!打卡,365打卡!两个状态的,都可以使用Bitmaps!
bitmaps命令:
setbit:赋值后会返回操作之前的值getbit:查看值bitcount:统计为1的值
127.0.0.1:6379> setbit sign 0 1
(integer) 0
127.0.0.1:6379> setbit sign 1 1
(integer) 0
127.0.0.1:6379> setbit sign 2 0
(integer) 0
127.0.0.1:6379> setbit sign 3 0
(integer) 0
127.0.0.1:6379> setbit sign 4 1
(integer) 0
127.0.0.1:6379> setbit sign 5 1
(integer) 0
127.0.0.1:6379> setbit sign 6 0
(integer) 0
127.0.0.1:6379> setbit sign 7 1
(integer) 0
127.0.0.1:6379> getbit sign 3
(integer) 0
127.0.0.1:6379> BITCOUNT sign # #统计这周的打卡记录,就可以看到是否有全勤!
(integer) 5
2、hyperloglogs
Redis HyperLogLog 是用来做基数统计的算法,HyperLogLog 的优点是,在输入元素的数量或者体积非常非常大时,计算基数所需的空间总是固定 的、并且是很小的。
在 Redis 里面,每个 HyperLogLog 键只需要花费 12 KB 内存,就可以计算接近 264 个不同元素的基 数。这和计算基数时,元素越多耗费内存就越多的集合形成鲜明对比。
什么是基数?
比如数据集 {1, 3, 5, 7, 5, 7, 8}, 那么这个数据集的基数集为 {1, 3, 5 ,7, 8}, 基数(不重复元素)为5。
缺点:
- 在数据量特别大的情况,会存在将近1%的误差,如果对数据准确度要求非常高,不建议使用
- HyperLogLog 只会根据输入元素来计算基数,而不会储存输入元素本身,所以 HyperLogLog 不能像集合那样,返回输入的各个元素(可以快速求出不重复元素的个数,但是无法输出不重复的元素本身)。
HyperLogLog命令:
PFADD:添加指定元素到 HyperLogLog 中。PFCOUNT:返回给定 HyperLogLog 的基数估算值。PFMERGE:将多个 HyperLogLog 合并为一个 HyperLogLog
127.0.0.1:6379> PFADD mykey a b c d e f g h i j #创建第一组元素 mykey
(integer) 1
127.0.0.1:6379> PFCOUNT mykey # 统计 mykey元素的基数数量
(integer) 10
127.0.0.1:6379> PFADD mykey2 i j z x c v b n m # 创建第一组元素 mykey
(integer) 1
127.0.0.1:6379> PFCOUNT mykey2
(integer) 9
127.0.0.1:6379> PFMERGE mykey3 mykey mykey2 # 合并两组 mykey mykey2 => mykey3 并集
OK
127.0.0.1:6379> PFCOUNT mykey3 # 看并集的数量!
(integer) 15
如果允许容错,那么一定可以使用Hyperloglog如果不允许容错,就使用set或者自己的数据类型即可!
3、geospatial indexes
应用场景:我们可以通过geo数据类型存储城市的经纬度,然后根据redis提供的命令,能够快速的根据城市经纬度计算朋友的定位、附近的人、打车距离等等。
Redis GEO 操作方法有:
geoadd:添加地理位置的坐标。geopos:获取地理位置的坐标。geodist:计算两个位置之间的距离。georadius:根据用户给定的经纬度坐标来获取指定范围内的地理位置集合。georadiusbymember:根据储存在位置集合里面的某个地点获取指定范围内的地理位置集合。geohash:返回一个或多个位置对象的 geohash 值。
(1)geoadd 语法格式如下:
- key 还是正常的redis当中的key
- longitude:地理经度
- latitude:地理纬度
- member:成员(一般我们可以当做城市名字)
GEOADD key longitude latitude member [longitude latitude member ...]
127.0.0.1:6379> GEOADD china:city 116.40 39.90 beijing
(integer) 1
127.0.0.1:6379> GEOADD china:city 121.47 31.23 shanghai 106.50 29.53 chongqing
(integer) 2
127.0.0.1:6379> GEOADD china:city 114.05 22.52 zhengzhou 120.16 30.24 hangzhou
(integer) 2
(2)geopos 语法格式如下:
GEOPOS key member [member ...]
geopos 用于从给定的 key 里返回所指定名称(member)的位置(经度和纬度),不存在的返回 nil。
127.0.0.1:6379> GEOPOS china:city beijing
1) "116.39999896287918091"
2) "39.90000009167092543"
(3)geodist语法格式如下:
GEODIST key member1 member2 [m|km|ft|mi]
geodist 用于返回两个给定位置之间的距离。
最后一个距离单位参数说明:
- m :米,默认单位。
- km :千米。
- mi :英里。
- ft :英尺。
127.0.0.1:6379> GEODIST china:city beijing shanghai km # 北京到上海的距离
"1067.3788"
127.0.0.1:6379> GEODIST china:city beijing chongqing km # 北京到重庆的距离
"1464.0708"
(4)georadius语法格式如下:
GEORADIUS key longitude latitude radius m|km|ft|mi [WITHCOORD] [WITHDIST] [WITHHASH] [COUNT count] [ASC|DESC] [STORE key] [STOREDIST key]
WITHDIST: 在返回位置元素的同时, 将位置元素与中心之间的距离也一并返回。WITHCOORD: 将位置元素的经度和维度也一并返回(默认是只返回名称(member))。WITHHASH: 以 52 位有符号整数的形式, 返回位置元素经过原始 geohash 编码的有序集合分值。 这个选项主要用于底层应用或者调试, 实际中的作用并不大。COUNT限定返回的记录数。ASC: 查找结果根据距离从近到远排序。DESC: 查找结果根据从远到近排序。radius:距离数
georadius 以给定的经纬度为中心, 返回与中心的距离不超过给定最大距离的所有位置元素。
我附近的人这个应该都知道,微信就有这个功能,他就可以通过这个命令来实现,以经纬度为中心,然后按照圆的半径来计算是否在这个范围的。
georadiusbymember 和 GEORADIUS 命令一样, 都可以找出位于指定范围内的元素, 但是 georadiusbymember 的中心点是由给定的位置元素决定的, 而不是使用经度和纬度来决定中心点。
127.0.0.1:6379> GEORADIUS china:city 110 30 1000 km # 以110, 30这个经纬度为中心,寻找方圆1000km内的城市
1) "chongqing"
2) "zhengzhou"
3) "hangzhou"
127.0.0.1:6379> GEORADIUS china:city 110 30 500 km WITHDIST #显示到中间距离的位置
1) 1) "chongqing"
2) "341.9374"
127.0.0.1:6379> GEORADIUS china:city 110 30 500 km WITHCOORD #显示他人的定位信息
1) 1) "chongqing"
2) 1) "106.49999767541885376"
2) "29.52999957900659211"
127.0.0.1:6379> GEORADIUS china:city 110 30 500 km WITHDIST WITHCOORD COUNT 1 # 限定返回结果
1) 1) "chongqing"
2) "341.9374"
3) 1) "106.49999767541885376"
2) "29.52999957900659211"
(5)georadiusbymember语法格式如下:
GEORADIUSBYMEMBER key member radius m|km|ft|mi [WITHCOORD] [WITHDIST] [WITHHASH] [COUNT count] [ASC|DESC] [STORE key] [STOREDIST key]
127.0.0.1:6379> GEORADIUSBYMEMBER china:city shanghai 500 km
1) "hangzhou"
2) "shanghai"
(6)geohash语法格式如下:
GEOHAS Hkey member [member ...]
将二维的经纬度转换为一维的字符串,如果两个字符申越接近,那么则距离越近!
127.0.0.1:6379> GEOHASH china:city beijing chongqing
1) "wx4fbxxfke0"
2) "wm5xzrybty0"
(7)GEO 底层的实现原理其实就是Zset!我们可以使用Zset命令来操作geo!
127.0.0.1:6379> ZRANGE china:city 0 -1 # 查看当前key的所有元素
1) "chongqing"
2) "zhengzhou"
3) "hangzhou"
4) "shanghai"
5) "beijing"
4、streams
Redis Stream 是 Redis 5.0 版本新增加的数据结构。
Redis Stream 主要用于消息队列(MQ,Message Queue),Redis 本身是有一个 Redis 发布订阅 (pub/sub) 来实现消息队列的功能,但它有个缺点就是消息无法持久化,如果出现网络断开、Redis 宕机等,消息就会被丢弃。
简单来说发布订阅 (pub/sub) 可以分发消息,但无法记录历史消息。
而 Redis Stream 提供了消息的持久化和主备复制功能,可以让任何客户端访问任何时刻的数据,并且能记住每一个客户端的访问位置,还能保证消息不丢失。
官网介绍:https://www.redis.com.cn/redis-stream.html
Redis Stream 的结构如下所示,它有一个消息链表,将所有加入的消息都串起来,每个消息都有一个唯一的 ID 和对应的内容:
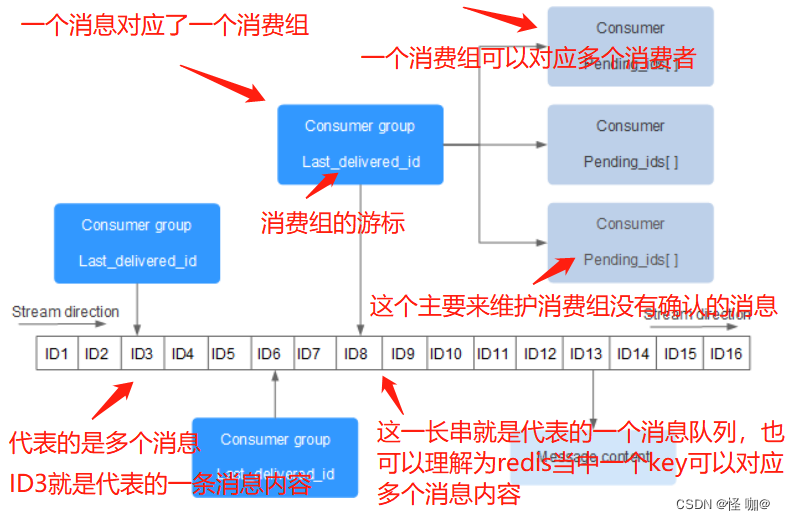
每个 Stream 都有唯一的名称,它就是 Redis 的 key,在我们首次使用 xadd 指令追加消息时自动创建。
上图解析:
Consumer Group:消费组,使用 XGROUP CREATE 命令创建,一个消费组有多个消费者(Consumer)。消费者组最初是由流行的消息传递系统Kafka (TM)引入的。Redis 用完全不同的术语重新实现了类似的想法,但目标是相同的:允许一组客户端合作消费同一消息流的不同部分。lastdeliveredid:游标,每个消费组会有个游标 lastdeliveredid,任意一个消费者读取了消息都会使游标 lastdeliveredid 往前移动。pendingids:消费者(Consumer)的状态变量,作用是维护消费者的未确认的 id。 pendingids 记录了当前已经被客户端读取的消息,但是还没有 ack (Acknowledge character:确认字符)。
消息队列相关命令:
XADD- 添加消息到末尾XTRIM- 对流进行修剪,限制长度XDEL- 删除消息XLEN- 获取流包含的元素数量,即消息长度XRANGE- 获取消息列表,会自动过滤已经删除的消息XREVRANGE- 反向获取消息列表,ID 从大到小XREAD- 以阻塞或非阻塞方式获取消息列表
消费者组相关命令:
XGROUP CREATE- 创建消费者组XREADGROUP GROUP- 读取消费者组中的消息XACK- 将消息标记为"已处理"XGROUP SETID- 为消费者组设置新的最后递送消息IDXGROUP DELCONSUMER- 删除消费者XGROUP DESTROY- 删除消费者组XPENDING- 显示待处理消息的相关信息XCLAIM- 转移消息的归属权XINFO- 查看流和消费者组的相关信息;XINFO GROUPS- 打印消费者组的信息;XINFO STREAM- 打印流信息
(1)XADD、XLEN、XRANGE、XDEL
使用 XADD 向队列添加消息,如果指定的队列不存在,则创建一个队列,XADD 语法格式:
XADD key ID field value [field value ...]
- key :队列名称,如果不存在就创建
- ID :消息 id,我们使用 * 表示由 redis 生成,他是有顺序的,先生成的永远比后生成的小,类似zk当中的有序节点,当然也可以自定义,但是要自己保证递增性。
- field value : 记录。
其实仔细会发现stream数据类型的value其实就是java当中的 Map<消息id,Map<String,String>>,一个key对应了多个消息,消息内容又是一个map类型。
127.0.0.1:6379> XADD mystream * message1 zhangsan # 添加消息到末尾
"1658368133295-0"
127.0.0.1:6379> XADD mystream * message2 lisi message3 wangwu # 这样就代表的是一条消息多个field/value
"1658368207086-0"
127.0.0.1:6379> XLEN mystream # 获取流包含的元素数量,即消息长度
(integer) 2
127.0.0.1:6379> XRANGE mystream - + # 获取消息列表,会自动过滤已经删除的消息
1) 1) "1658368133295-0" # 第一条消息就是第一次xadd的数据(消息队列遵循先进先出)
2) 1) "message1"
2) "zhangsan"
2) 1) "1658368207086-0" # 第二条消息
2) 1) "message2"
2) "lisi"
3) "message3"
4) "wangwu"
(2)限制流的长度
127.0.0.1:6379> XADD mystream * k1 v1
"1658383458982-0"
127.0.0.1:6379> XADD mystream * k2 v2
"1658383464259-0"
127.0.0.1:6379> XADD mystream * k3 v3
"1658383468096-0"
127.0.0.1:6379> XRANGE mystream - + # 获取消息列表
1) 1) "1658383458982-0"
2) 1) "k1"
2) "v1"
2) 1) "1658383464259-0"
2) 1) "k2"
2) "v2"
3) 1) "1658383468096-0"
2) 1) "k3"
2) "v3"
127.0.0.1:6379> XADD mystream maxlen 3 * www aaa # 流的最大长度为3,当已经存在3个元素的时候,会将第一个进入队列当中的元素移除
"1658383685489-0"
127.0.0.1:6379> XRANGE mystream - + # 获取消息列表
1) 1) "1658383464259-0"
2) 1) "k2"
2) "v2"
2) 1) "1658383468096-0"
2) 1) "k3"
2) "v3"
3) 1) "1658383685489-0"
2) 1) "www"
2) "aaa"
(3)XTRIM 语法格式:
XTRIM命令与带有MAXLEN选项的XADD命令一样,都是根据先进先出规则来淘汰旧元素的
XTRIM key MAXLEN|MINID [~] threshold [count]
可以使用以下策略之一对流进行修剪:
- MAXLEN:只要流的长度超过指定的threshold,threshold就逐出条目,其中是一个正整数。
- MINID:逐出ID低于的条目threshold,其中threshold是流ID。
127.0.0.1:6379> XADD mystream * k1 v1
"1658384303812-0"
127.0.0.1:6379> XADD mystream * k2 v3
"1658384307343-0"
127.0.0.1:6379> XADD mystream * k3 v4
"1658384311653-0"
127.0.0.1:6379> XRANGE mystream - + # 获取消息列表
1) 1) "1658384303812-0"
2) 1) "k1"
2) "v1"
2) 1) "1658384307343-0"
2) 1) "k2"
2) "v3"
3) 1) "1658384311653-0"
2) 1) "k3"
2) "v4"
127.0.0.1:6379> XTRIM mystream maxlen 2 # 裁剪为2
(integer) 1
127.0.0.1:6379> XRANGE mystream - +
1) 1) "1658384307343-0"
2) 1) "k2"
2) "v3"
2) 1) "1658384311653-0"
2) 1) "k3"
2) "v4"
127.0.0.1:6379> XTRIM mystream maxlen ~ 1 # 参数~意思是,用户不是真的需要精确的1个项目,它可以多几十个条目,但决不能少于1个,使用此参数,仅当我们可以删除整个节点时才执行修剪。这使它更有效率,而且它通常是你想要的。
(integer) 0
127.0.0.1:6379> XRANGE mystream - +
1) 1) "1658384307343-0"
2) 1) "k2"
2) "v3"
2) 1) "1658384311653-0"
2) 1) "k3"
2) "v4"
(4)XDEL 语法格式:
XDEL key ID [ID ...]
- key:队列名称
- ID :消息 ID
127.0.0.1:6379> XADD mystream * k1 v1
"1658385325724-0"
127.0.0.1:6379> XADD mystream * k2 v2
"1658385331168-0"
127.0.0.1:6379> XADD mystream * k3 v3
"1658385338964-0"
127.0.0.1:6379> XRANGE mystream - +
1) 1) "1658385325724-0"
2) 1) "k1"
2) "v1"
2) 1) "1658385331168-0"
2) 1) "k2"
2) "v2"
3) 1) "1658385338964-0"
2) 1) "k3"
2) "v3"
127.0.0.1:6379> XDEL mystream 1658385338964-0 # 删除
(integer) 1
127.0.0.1:6379> XRANGE mystream - +
1) 1) "1658385325724-0"
2) 1) "k1"
2) "v1"
2) 1) "1658385331168-0"
2) 1) "k2"
2) "v2"
(5)XRANGE 语法格式:
XREVRANGE key end start [COUNT count]
- key :队列名
- end :结束值, + 表示最大值
- start :开始值, - 表示最小值
- count :数量
127.0.0.1:6379> XADD mystream * k1 v1
"1658386831077-0"
127.0.0.1:6379> XADD mystream * k2 v2
"1658386834879-0"
127.0.0.1:6379> XADD mystream * k3 v3
"1658386838271-0"
127.0.0.1:6379> XRANGE mystream - + count 1
1) 1) "1658386831077-0"
2) 1) "k1"
2) "v1"
127.0.0.1:6379> XRANGE mystream - + count 2 # 查询两个
1) 1) "1658386831077-0"
2) 1) "k1"
2) "v1"
2) 1) "1658386834879-0"
2) 1) "k2"
2) "v2"
127.0.0.1:6379> XRANGE mystream - + count 1 # 只查询1个
1) 1) "1658386831077-0"
2) 1) "k1"
2) "v1"
127.0.0.1:6379> XRANGE mystream - + # 查询所有
1) 1) "1658386831077-0"
2) 1) "k1"
2) "v1"
2) 1) "1658386834879-0"
2) 1) "k2"
2) "v2"
3) 1) "1658386838271-0"
2) 1) "k3"
2) "v3"
(6)XREVRANGE 语法格式:
XREVRANGE key end start [COUNT count]
XREVRANGE 和 XRANGE 正好是相反的。在XREVRANGE中,你需要先指定结束ID,再指定开始ID,该命令就会从结束ID侧开始生成两个ID之间(或完全相同)的所有元素。
127.0.0.1:6379> XRange mystream - +
1) 1) "1658386831077-0"
2) 1) "k1"
2) "v1"
2) 1) "1658386834879-0"
2) 1) "k2"
2) "v2"
3) 1) "1658386838271-0"
2) 1) "k3"
2) "v3"
127.0.0.1:6379> XREVRANGE mystream + -
1) 1) "1658386838271-0"
2) 1) "k3"
2) "v3"
2) 1) "1658386834879-0"
2) 1) "k2"
2) "v2"
3) 1) "1658386831077-0"
2) 1) "k1"
2) "v1"
(7)XREAD 语法格式:
使用 XREAD 以阻塞或非阻塞方式获取消息列表 ,语法格式:
XREAD [COUNT count] [BLOCK milliseconds] STREAMS key [key ...] id [id ...]
- count :数量
- milliseconds :可选,阻塞毫秒数,没有设置就是非阻塞模式
- key :队列名
- id :消息 ID
127.0.0.1:6379> XADD mystream1 * k1 v1 # 新建mystream1
"1658391926142-0"
127.0.0.1:6379> XADD mystream1 * k2 v2
"1658391930089-0"
127.0.0.1:6379> XADD mystream1 * k3 v3
"1658391934807-0"
127.0.0.1:6379> XADD mystream2 * k4 v4 # 新建mystream2
"1658391943541-0"
127.0.0.1:6379> XADD mystream2 * k5 v5
"1658391948819-0"
127.0.0.1:6379>
127.0.0.1:6379> XRANGE mystream1 - + # 查询所有
1) 1) "1658391926142-0"
2) 1) "k1"
2) "v1"
2) 1) "1658391930089-0"
2) 1) "k2"
2) "v2"
3) 1) "1658391934807-0"
2) 1) "k3"
2) "v3"
127.0.0.1:6379> XRANGE mystream2 - + # 查询所有
1) 1) "1658391943541-0"
2) 1) "k4"
2) "v4"
2) 1) "1658391948819-0"
2) 1) "k5"
2) "v5"
127.0.0.1:6379> xread count 1 streams mystream1 mystream2 1658391926142-0 1658391943541-0 # 读取流中id大于给定id的元素(count 1代表只取1个)
1) 1) "mystream1"
2) 1) 1) "1658391930089-0"
2) 1) "k2"
2) "v2"
2) 1) "mystream2"
2) 1) 1) "1658391948819-0"
2) 1) "k5"
2) "v5"
127.0.0.1:6379> xread streams mystream1 mystream2 1658391926142-0 1658391943541-0 # 不使用count命令时返回所有大于指定id的元素
1) 1) "mystream1"
2) 1) 1) "1658391930089-0"
2) 1) "k2"
2) "v2"
2) 1) "1658391934807-0"
2) 1) "k3"
2) "v3"
2) 1) "mystream2"
2) 1) 1) "1658391948819-0"
2) 1) "k5"
2) "v5"
127.0.0.1:6379> XREAD count 2 streams mystream1 0-0 # 从 Stream 头部读取两条消息
1) 1) "mystream1"
2) 1) 1) "1658391926142-0"
2) 1) "k1"
2) "v1"
2) 1) "1658391930089-0"
2) 1) "k2"
2) "v2"
(8)XREAD 阻塞使用
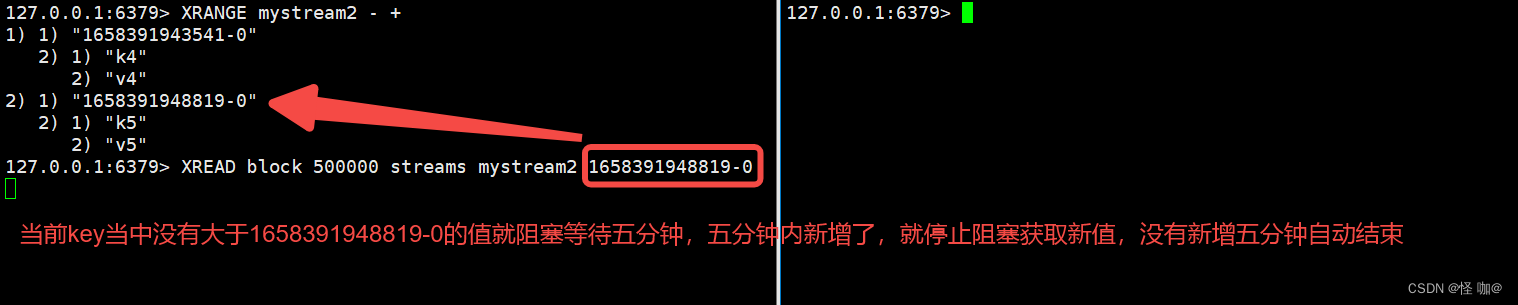
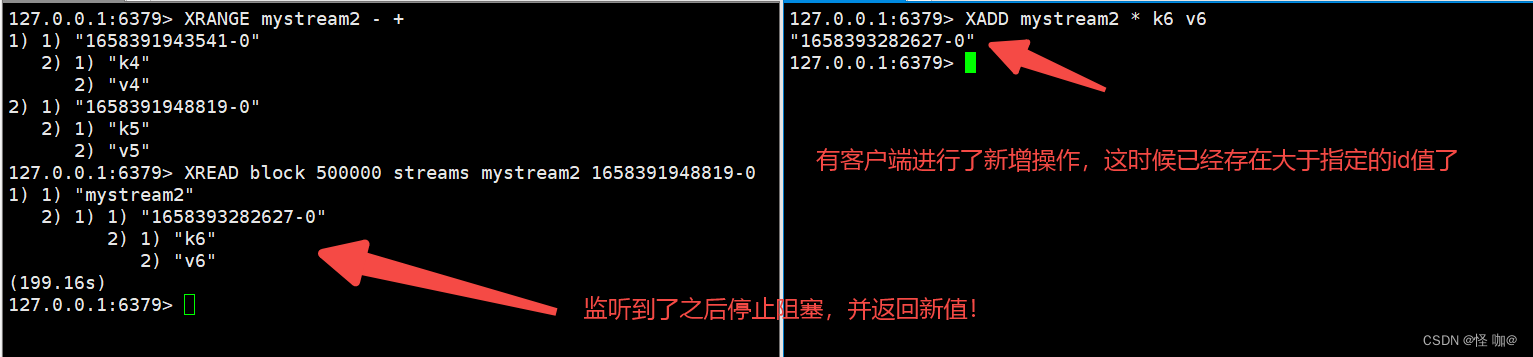
(9)XGROUP CREATE
以上都属于stream的基本操作,以下才开始真正的关于消费组等等相关的内容!
如果你了解kafka的消费者组,那么你就也了解了streams的消费者组。如果不了解也没关系,笔者简单解释一下,假设有三个消费者C1,C2,C3。在streams中总计有7条消息:1, 2, 3, 4, 5, 6, 7,那么消费关系如下所示:
1 -> C1
2 -> C2
3 -> C3
4 -> C1
5 -> C2
6 -> C3
7 -> C1
消费者组具备如下几个特点:
同一个消息不会被投递到一个消费者组下的多个消费者,只可能是一个消费者。这一点和我刚开始接触的时候以为的不一样,接触过消息队列的应该都知道,消息是有广播形式的,而这个很明显是轮播。- 同一个消费者组下,每个消费者都是唯一的,通过大小写敏感的名字区分。
- 消费者组中的消费者请求的消息,一定是新的,从来没有投递过的消息。
- 消费一个消息后,需要用命令(XACK)确认,意思是说:这条消息已经给成功处理。正因为如此,当访问streams的历史消息时,每个消费者只能看到投递给它自己的消息。
使用 XGROUP CREATE 创建消费者组,语法格式:
XGROUP [CREATE key groupname id-or-$] [SETID key groupname id-or-$] [DESTROY key groupname] [DELCONSUMER key groupname consumername]
- key :队列名称,如果不存在就创建
- groupname :组名。
- $ : 表示从尾部开始消费,只接受新消息,当前 Stream 消息会全部忽略。
127.0.0.1:6379> XADD mystream * k1 v1
"1658396779994-0"
127.0.0.1:6379> XADD mystream * k2 v2
"1658396782915-0"
127.0.0.1:6379> XADD mystream * k3 v3
"1658396786069-0"
127.0.0.1:6379> XGROUP CREATE mystream group1 0-0 # 从头开始消费
OK
127.0.0.1:6379> XGROUP CREATE mystream group2 $ # 从尾部开始消费
OK
127.0.0.1:6379> XINFO GROUPS mystream # 打印消费者组的信息
1) 1) "name"
2) "group1"
3) "consumers"
4) (integer) 0
5) "pending"
6) (integer) 0
7) "last-delivered-id"
8) "0-0"
9) "entries-read"
10) (nil)
11) "lag"
12) (integer) 3
2) 1) "name"
2) "group2"
3) "consumers"
4) (integer) 0
5) "pending"
6) (integer) 0
7) "last-delivered-id"
8) "1658396786069-0"
9) "entries-read"
10) (nil)
11) "lag"
12) (integer) 0
(10)XREADGROUP GROUP
使用 XREADGROUP GROUP 读取消费组中的消息,语法格式:
XREADGROUP GROUP group consumer [COUNT count] [BLOCK milliseconds] [NOACK] STREAMS key [key ...] ID [ID ...]
- group :消费组名
- consumer :消费者名。
- count : 读取数量。
- milliseconds : 阻塞毫秒数。
- key : 队列名。
- ID : 消息 ID。
127.0.0.1:6379> XADD mystream * k1 v1
"1658401776508-0"
127.0.0.1:6379> XADD mystream * k2 v2
"1658401781308-0"
127.0.0.1:6379> XADD mystream * k3 v3
"1658401793152-0"
127.0.0.1:6379> XGROUP CREATE mystream group2 $
OK
# 名为zhangsan的消费者,需要注意的是streams名称mystream后面的特殊符号`>`表示这个消费者只接收从来没有被投递给其他消费者的消息,即新的消息。当然我们也可以指定具体的ID,例如指定0表示访问所有投递给该消费者的历史消息,指定1540081890919-1表示投递给该消费者且大于这个ID的历史消息:
127.0.0.1:6379> XREADGROUP GROUP group2 zhangsan count 1 block 0 streams mystream >
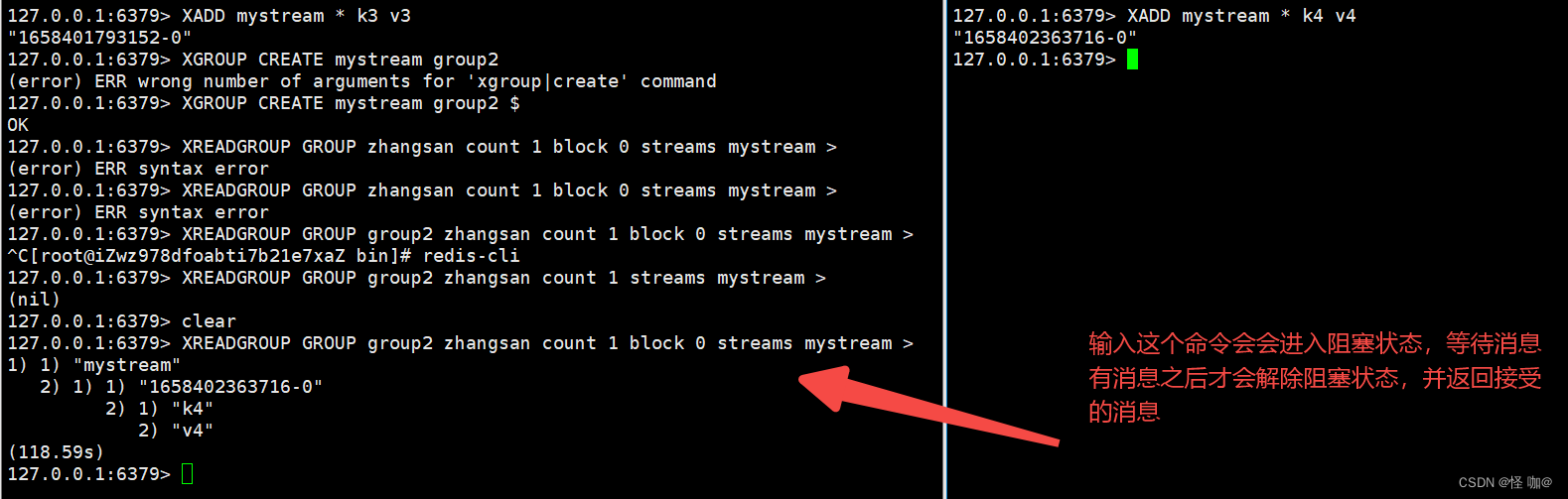
指定0表示访问所有投递给该消费者的历史消息(ack确认后就查不到了)

在两个客户端当中分别通过不同的消费者进行阻塞监听,会发现一条就会被zhangsan消费,另一条被lisi消费
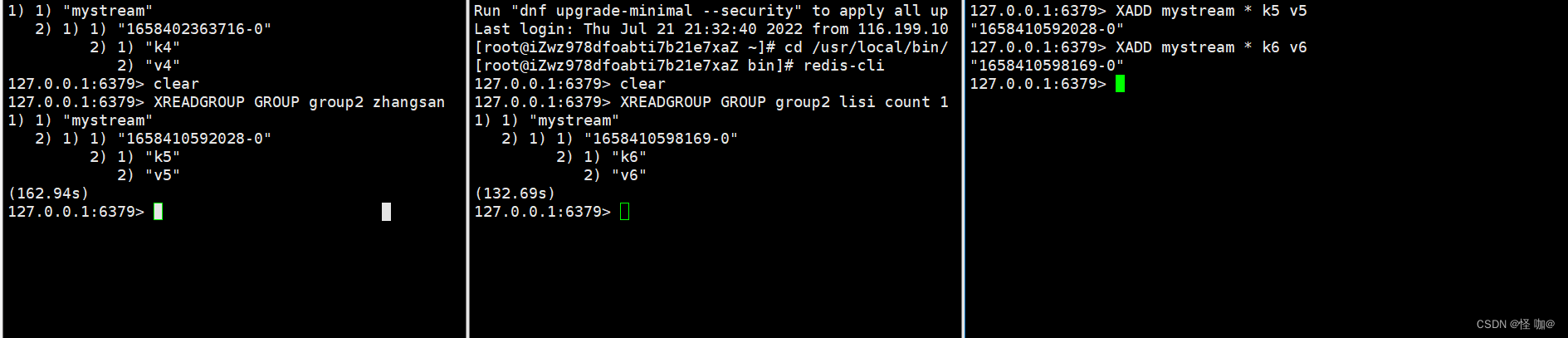
(11)XACK
127.0.0.1:6379> XREADGROUP GROUP group2 zhangsan count 1 block 0 streams mystream 0 # 获取一条历史消息
1) 1) "mystream"
2) 1) 1) "1658402363716-0"
2) 1) "k4"
2) "v4"
127.0.0.1:6379> xack mystream group2 1658402363716-0 # 通过命令ack这条消息
(integer) 1
127.0.0.1:6379> XREADGROUP GROUP group2 zhangsan count 1 block 0 streams mystream 0 # 获取一条历史消息
1) 1) "mystream"
2) 1) 1) "1658410592028-0"
2) 1) "k5"
2) "v5"
127.0.0.1:6379> xack mystream group2 1658410592028-0 # 通过命令ack这条消息
(integer) 1
127.0.0.1:6379> XREADGROUP GROUP group2 zhangsan count 1 block 0 streams mystream 0 # 获取一条历史消息(通过ack后通过0就查不到)
1) 1) "mystream"
2) (empty array)
(12)XPENDING
XPENDING key group [start end count][consumer]
返回streams中消费者组的pending消息,即消费者接收到但是还没有ack的消息,用法参考:
127.0.0.1:6379> XREADGROUP GROUP group2 zhangsan count 1 block 0 streams mystream 0 # 这块是只查zhangsan消费者还没有确认的消息
1) 1) "mystream"
2) (empty array)
127.0.0.1:6379> XPENDING mystream group2 - + 10 # 这是查当前分组(分组下的所有消费者)没有ack的消息
1) 1) "1658410598169-0"
2) "lisi"
3) (integer) 2646545
4) (integer) 1
(13)XCLAIM
XCLAIM key group consumer min-idle-time ID [ID …][IDLE ms] [TIME ms-unix-time][RETRYCOUNT count] [FORCE][JUSTID]
作用是改变消费者组中消息的所有权,用法参考:
127.0.0.1:6379> XREADGROUP GROUP group2 lisi count 5 block 0 streams mystream 0 # 李四是有一条没有确认的消息的
1) 1) "mystream"
2) 1) 1) "1658410598169-0"
2) 1) "k6"
2) "v6"
127.0.0.1:6379> XREADGROUP GROUP group2 zhangsan count 5 block 0 streams mystream 0 # zhangsan是没有消息的
1) 1) "mystream"
2) (empty array)
# lisi本来有1条消息,转权给zhangsan
127.0.0.1:6379> XCLAIM mystream group2 zhangsan 360 1658410598169-0
1) 1) "1658410598169-0"
2) 1) "k6"
2) "v6"
127.0.0.1:6379> XREADGROUP GROUP group2 zhangsan count 5 block 0 streams mystream 0
1) 1) "mystream"
2) 1) 1) "1658410598169-0"
2) 1) "k6"
2) "v6"
127.0.0.1:6379> XREADGROUP GROUP group2 lisi count 5 block 0 streams mystream 0
1) 1) "mystream"
2) (empty array)
(14)XINFO
XINFO [CONSUMERS key groupname][GROUPS key] [STREAM key][HELP]
其作用是得到streams和消费者组的一些信息,使用参考:
127.0.0.1:6379> XINFO CONSUMERS mystream group2
1) 1) "name" # 当前分组消费者名字
2) "lisi"
3) "pending"
4) (integer) 0
5) "idle"
6) (integer) 251200
2) 1) "name" # 当前分组消费者名字
2) "zhangsan"
3) "pending"
4) (integer) 1 # 当前消费者有几条没有ack的消息
5) "idle"
6) (integer) 259774
127.0.0.1:6379> XINFO STREAM mystream # 获取当前消息队列的一些信息
1) "length"
2) (integer) 6
3) "radix-tree-keys"
4) (integer) 1
5) "radix-tree-nodes"
6) (integer) 2
7) "last-generated-id"
8) "1658410598169-0"
9) "max-deleted-entry-id"
10) "0-0"
11) "entries-added"
12) (integer) 6
13) "recorded-first-entry-id"
14) "1658401776508-0"
15) "groups"
16) (integer) 1
17) "first-entry"
18) 1) "1658401776508-0"
2) 1) "k1"
2) "v1"
19) "last-entry"
20) 1) "1658410598169-0"
2) 1) "k6"
2) "v6"

















 439
439











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











