






熵:原本物理学中的定义,后来香农将其引申到啦信息论领域,用来表示信息量的大小。信息量大(分类越不“纯净”),对应的熵值就越大,反之亦然。
信息熵的计算公式:
联合熵:一维随机变量分布推广到多维随机变量分布。
联合熵的计算公式:
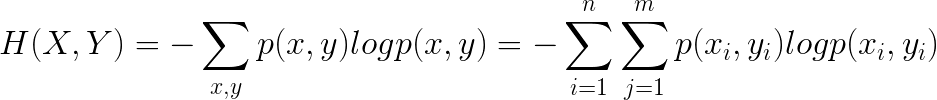
条件熵: H(Y|X) 表示在已知随机变量 X 的条件下随机变量 Y 的不确定性。条件熵 H(Y|X) 定义为 X 给定条件下 Y 的条件概率分布的熵对 X 的数学期望。
条件熵的计算公式:

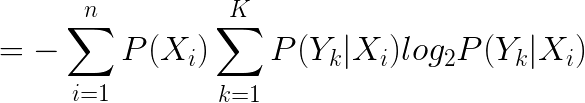
信息增益:以某特征划分数据集前后的熵的差值。即待分类集合的熵和选定某个特征的条件熵之差。
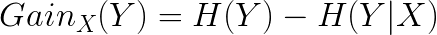
基尼不纯度即基尼指数
基尼不纯度的计算公式:
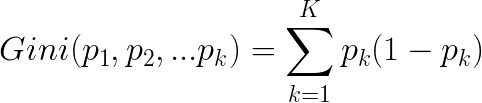
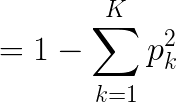
决策树的不同分类算法
ID3算法
原理:ID3算法是一种贪心算法,用来构造决策树。ID3算法起源于概念学习系统
(CLS),以信息熵的下降速度为选取测试属性的标准,即在每个节点选取还尚未被用来划分的具有最高信息增益的属性作为划分标准,然后继续这个过程,直到生成的决策树能完美分类训练样例。
应用场景:决策树ID3算法是一个很有实用价值的示例学习算法,它的基础理论清晰,算法比较简单,学习能力较强,适于处理大规模的学习问题,是数据挖掘和知识发现领域中的一个很好的范例,为后来各学者提出优化算法奠定了理论基础。ID3算法特别在机器学习、知识发现和数据挖掘等领域得到了极大发展。
C4.5
原理:C4.5是一系列用在机器学习和数据挖掘的分类问题中的算法。它的目标是监督学习:给定一个数据集,其中的每一个元组都能用一组属性值来描述,每一个元组属于一个互斥的类别中的某一类。C4.5的目标是通过学习,找到一个从属性值到类别的映射关系,并且这个映射能用于对新的类别未知的实体进行分类。
应用场景:决策树(Decision Tree)是用于分类和预测的主要技术,它着眼于从一组无规则的事例推理出决策树表示形式的分类规则,采用自顶向下的递归方式,在决策树的内部节点进行属性值的比较,并根据不同属性判断从该节点向下分支,在决策树的叶节点得到结论。因此,从根节点到叶节点就对应着一条合理规则,整棵树就对应着一组表达式规则。基于决策树算法的一个最大的优点是它在学习过程中不需要使用者了解很多背景知识,只要训练事例能够用属性即结论的方式表达出来,就能使用该算法进行学习。
决策树算法在很多方面都有应用,如决策树算法在医学、制造和生产、金融分析、天文学、遥感影像分类和分子生物学、机器学习和知识发现等领域得到了广泛应用。
CART分类树
原理:是一种应用广泛的决策树算法,不同于 ID3 与 C4.5, CART 为一种二分决策树, 每次对特征进行切分后只会产生两个子节点,而ID3 或 C4.5 中决策树的分支是根据选定特征的取值来的,切分特征有多少种不同取值,就有多少个子节点(连续特征进行离散化即可)。CART 设计回归与分类,接下来将分别介绍分类树与回归树。
应用场景:CART算法既可以处理离散型问题,也可以处理连续型问题。CART算法是一种非常有趣且十分有效的非参数分类和回归方法。它通过构建二叉树达到预测目的。它已在统计、数据挖掘和机器学习领域中普遍使用,是一种应用广泛的决策树算法。
回归树原理
决策树实际上是将空间用超平面进行划分的一种方法,每次分割的时候,都将当前的空间一分为二, 这样使得每一个叶子节点都是在空间中的一个不相交的区域,在进行决策的时候,会根据输入样本每一维feature的值,一步一步往下,最后使得样本落入N个区域中的一个(假设有N个叶子节点)
防止过拟合的方法
减少特征值
控制迭代次数
正则化















 7951
7951
09-02
“相关推荐”对你有帮助么?
-

 非常没帮助
非常没帮助 -

 没帮助
没帮助 -

 一般
一般 -

 有帮助
有帮助 -

 非常有帮助
非常有帮助
提交

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









