







UDP和TCP的基础知识和选用
首先我们要知道UDP协议和TCP协议都是TCP/IP模型中传输层的协议;都是通过端口来识别进程的,在TCP/IP协议中, ⽤ “源IP”, “源端⼝号”, “目的IP”, “目的端⼝号”, “协议号” 这样⼀个五元组来标识⼀个通信(可以通过netstat -n查看);并且UPD,TCP协议都是全双工(数据可以双向走)
**
UDP协议
**
UDP协议的协议字段: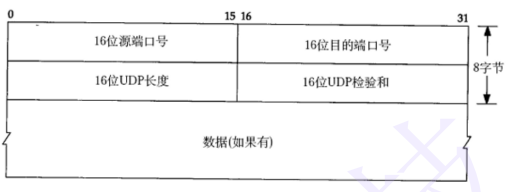
1. 16位源端口号:用于储存源端口号
16位目的端口号:用于储存目的端口号
16位数据报长度:用于指定整个UDP数据报的长度(包含头部)
16位校验和:比较简短,最好和内容有关。(使用的是CRC冗余校验的方式)
2. 16位的数据报长度决定了一个udp协议的数据长度不能大于64k,否则发送失败;
若是大于64k:则可以在应用层通过代码把应用数据拆分成多个数据报,在使用多个UDP数据报来
分别发送, 但是代码实现的成本大大提高了
3. 用户每次调用发送接口发送数据的时候,UDP会直接为这条数据封装DUP头部信息,直接发送出去.
*
UDP的特点
UDP的特点是:无连接,不可靠,面向数据报
无连接不可靠:通信时不需要建立连接,只需要知道对端地址信息,就可以发送数据
面向数据报:数据只能整条向应用层交付
TCP协议
TCP 的封装:

源/目的端⼝号: 表⽰数据是从哪个进程来, 到哪个进程去;
32位序号:TCP将每个字节的数据都进⾏了编号. 即为序列号
32位确认号: 每⼀个ACK都带有对应的确认序列号, 意思是告诉发送者, 我已经收到了哪些数据; 下⼀次你从哪⾥开始发
4位TCP报头⻓度: 表⽰该TCP头部有多少个32位bit(有多少个4字节); 所以TCP头部最⼤⻓度是
15 * 4 =60;
6位标志位:
URG: 紧急指针是否有效
ACK: 确认号是否有效
PSH: 提⽰接收端应⽤程序⽴刻从TCP缓冲区把数据读⾛
RST: 对⽅要求重新建⽴连接; 我们把携带RST标识的称为复位报⽂段
SYN: 请求建⽴连接; 我们把携带SYN标识的称为同步报⽂段
FIN: 通知对⽅, 本端要关闭了, 我们称携带FIN标识的为结束报文段
16位窗⼝⼤⼩: 是⽆需等待确认应答⽽可以继续发送数据的最⼤值. 上图的窗⼝⼤⼩就是4000个字节
16位校验和: 发送端填充, CRC校验. 接收端校验不通过, 则认为数据有问题. 此处的检验和不光包含TCP
⾸部, 也包含TCP数据部分.
16位紧急指针: 标识哪部分数据是紧急数据;
40字节头部选项: 暂时忽略;
TCP的特点:
1.有连接:发送数据前要先建立连接
2.可靠传输:发送者能感知到失败
3.面向字节流:
TCP的相关机制
TCP的相关机制很多都是围绕可靠传输和尽可能提高传输效率来展开
一。确认应答(可靠性的核心机制)

1.序号:按照每个字节的方式来编号
2.确认序号:表示当前序号之前的数据已经正确收到了,接下来对端应该给我发送确认序号开始的数据
二。超时重传

主机A发送数据给B之后, 可能因为⺴络拥堵等原因, 数据⽆法到达主机B;
如果主机A在⼀个特定时间间隔内没有收到B发来的确认应答, 就会进⾏重发;
但是, 主机A未收到B发来的确认应答, 也可能是因为ACK丢失了;

因此主机B会收到很多重复数据. 那么TCP协议需要能够识别出那些包是重复的包, 并且 把重复的丢弃掉.
这时候我们可以利⽤前⾯提到的序列号, 就可以很容易做到去重的效果.
那么, 如果超时的时间如何确定?
最理想的情况下, 找到⼀个最⼩的时间, 保证 "确认应答⼀定能在这个时间内返回".
但是这个时间的⻓短, 随着⺴络环境的不同, 是有差异的.
如果超时时间设的太⻓, 会影响整体的重传效率;
如果超时时间设的太短, 有可能会频繁发送重复的包;
TCP为了保证⽆论在任何环境下都能⽐较⾼性能的通信, 因此会动态计算这个最⼤超时时间.
Linux中(BSD Unix和Windows也是如此), 超时以500ms为⼀个单位进⾏控制, 每次判定超时重发的
超时时间都是500ms的整数倍.
如果重发⼀次之后, 仍然得不到应答, 等待 2*500ms 后再进⾏重传.
如果仍然得不到应答, 等待 4*500ms 进⾏重传. 依次类推, 以指数形式递增.
累计到⼀定的重传次数, TCP认为⺴络或者对端主机出现异常, 强制关闭连接.
三。连接管理**(也是可靠性的一部分)
建立连接的意义:
1.双方是否合适建立连接
2.双方可以协商一些重要数据,序号从几开始
三次握手:

四次挥手:

ACK是由内核控制的;
FIN是由用户代码控制的,执行到socket对象关闭方法的时候会发送FIN你;
四。 滑动窗口(提高传输效率)
刚才我们讨论了确认应答策略, 对每⼀个发送的数据段, 都要给⼀个ACK确认应答. 收到ACK后再发送下⼀个

数据段. 这样做有⼀个⽐较⼤的缺点, 就是性能较差. 尤其是数据往返的时间较⻓的时候.

既然这样⼀发⼀收的⽅式性能较低, 那么我们⼀次发送多条数据, 就可以⼤⼤的提⾼性能(其实是将多个段的等待时间重叠在⼀起了).
窗⼝⼤⼩指的是⽆需等待确认应答⽽可以继续发送数据的最⼤值. 上图的窗⼝⼤⼩就是4000个字节
(四个段).
发送前四个段的时候, 不需要等待任何ACK, 直接发送;
收到第⼀个ACK后, 滑动窗⼝向后移动, 继续发送第五个段的数据; 依次类推;
操作系统内核为了维护这个滑动窗⼝, 需要开辟 发送缓冲区 来记录当前还有哪些数据没有应答; 只
有确认应答过的数据, 才能从缓冲区删掉;
窗⼝越⼤, 则⺴络的吞吐率就越⾼;
滑动的含义:每次收到ack数据的同时,就继续往后发下一组数据
注: 但如果窗口越大,传输效率就越大。但窗口不能太大,如果窗口太大可能会影响可靠性

⼀: 数据包已经抵达, ACK被丢了.

这种情况下, 部分ACK丢了并不要紧, 因为可以通过后续的ACK进⾏确认;
情况⼆: 数据包就直接丢了.

当某⼀段报⽂段丢失之后, 发送端会⼀直收到 1001 这样的ACK, 就像是在提醒发送端 "我想要的是
1001" ⼀样;
如果发送端主机连续三次收到了同样⼀个 "1001" 这样的应答, 就会将对应的数据 1001 - 2000 重新
发送;
这个时候接收端收到了 1001 之后, 再次返回的ACK就是7001了(因为2001 - 7000)接收端其实之前
就已经收到了, 被放到了接收端操作系统内核的接收缓冲区中;
这种机制被称为 "⾼速重发控制"(也叫 "快重传").
流量控制
接收端处理数据的速度是有限的. 如果发送端发的太快, 导致接收端的缓冲区被打满, 这个时候如果发送端
五。流量控制(由缓冲区大小控制)
数据的发送速度超过了接受速度,接受缓冲区的内容就会越来越多,达到一定程度缓冲区满了,此时再
传输的数据就会丢包。
使用接受缓冲区空余大小,用这个指标衡量接收端的处理能力。
通过这个指标来控制发送端的窗口大小(发送速度)。
接收端的缓冲区空余空间大小,作为TCP协议报头中的窗口大小,这个值就是发送端的滑动窗口大小的一个“建议值”)。
六。拥塞控制(跟网络环境的好坏有关)
滑动窗口的大小不能无限大,即使接收端处理速度很快,也肯能因为网络环境不佳导致数据丢失。
最终的滑动窗口大小是由 流量控制和拥塞控制 共同决定
拥塞窗口:拥塞控制机制所建议的窗口大小,从一个比较小的数字开始,如果网络通畅,放大窗口大小。如果网络丢包,缩小窗口大小。
滑动窗口的最终值就是流量控制的窗口 和拥塞窗口的较小值
慢开始:刚开始传输的时候拥塞窗口设置的小一些
七。延时应答(提高传输效率)
在可靠性的基础上,尽量提高窗口大小
也是和滑动窗口以及流量控制有关。
流量控制中需要再ACK中反馈接受缓冲区剩余空间的大小,此时采取的策略
八。捎带应答
建立在延时应答的基础之上
内核反馈ack的实际和程序反馈响应的时机合二为一,通过同一个数据报同时带上两方面的信息
九。面向字节流
带来 粘包问题:由于面向字节流读取数据方式没有具体的约定,很难从接收缓存区中直接获取到一个完整的应用层数据报;
粘包问题不是TCP自身问题,是面向字节流导致的一个问题,和应用层的代码直接相关;
解决粘包问题只能从应用层角度入手:只要在应用层协议设定的时候,明确包的边界就可以了;
如何确定包的边界:
1.指定分割符
2.指定包的长度
十。小结

异常情况
1.程序异常结束(没啥影响,四次挥手会正常完成)
2.系统关机(没啥影响,本质上就是先关闭所有程序)
3.主基掉电/拔网线
a)掉电的是接收方,发送方会触发超时重传,尝试重新建立连接,彻底释放连接 【强制释放】
b)掉电的是发送方:接收方如果一直收不到数据的话,达到一定时间之后,就会给对方发送一个“心跳包”,如果没有心跳了,就会重新建立连接,如果建立失败,就会彻底释放。
TCP和UDP的对比和选用
1.如果需要使用使用可靠传输,优先考虑TCP
2.如果传输的单个数据报比较大,还是考虑TCP (UDP最大的传输数据最大不能超过64k)
3.如果对可靠性要求比较低(网络环境比较安全),但是对效率要求很高,优先考虑UDP
4.如果需要实现广播,那么优先考虑UDP.















 1183
1183











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









