







Tensorflow学习笔记3
第三讲 TensorFlow框架
1、基于tensorflow的神经网络(NN)简介:
用张量表示数据,用计算图搭建神经网络,用绘画执行计算图,优化线上的权重(参数),得到模型。
①张量(tensor):多维数组(列表),用阶来表示张量的维数。
0阶张量(标量):s=123
1阶张量(向量):v=[1,2,3]
2阶张量(矩阵):m=[[1,2,3],[4,5,6],[7,8,9]]
n阶张量(张量):t=[[[…(n个[)
#tensorflow的使用:
import tensorflow as if
a = tf.constant([1.0,2.0]) #定义张量a
a = tf.constant([3.0,4.0]) #定义张量b
result = a+b
print result
#Tensor("add:0", shape=(2,), dtype=float32) add为节点名,0是第零个输出,shape时维度,2是一位数组长度,dtype是数据类型。
②计算图(graph):搭建神经网络的计算过程,只搭建,不运算。
如下搭建了矩阵乘法:

仅搭建了运算图,并没有得到计算结果。
③会话(session):执行计算图中的节点运算。
#语法:
with tf.Session() as sess:
print sess.run(y) #计算变量结果
这里有个vim去掉长段警告的方法

看到这里心血来潮搜了一下矩阵乘法(其实是忘记怎么算了TAT),发现了几种特殊积,记录了下来:
- 哈达马积(Hadamard product):
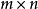 矩阵
矩阵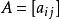 与
与 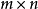 矩阵
矩阵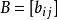 的Hadamard积记作
的Hadamard积记作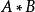 。其元素定义为两个矩对应元素的乘积
。其元素定义为两个矩对应元素的乘积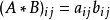 的m×n矩阵。例如,
的m×n矩阵。例如, 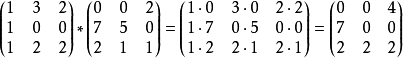
- 克罗内克积(Kronecker Product):
克罗内克积是两个任意大小的矩阵间的运算,符号记作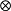 。克罗内克积也被称为直积或张量积.以德国数学家利奥波德·克罗内克命名。计算过程如下例所示:
。克罗内克积也被称为直积或张量积.以德国数学家利奥波德·克罗内克命名。计算过程如下例所示:
④参数:权重w,用变量表示,随机给初值。
W = tf.Variable(tf.random_normal([2,3], stddev=2, mean=0, seed=1)) #定义变量
随机种子如果去掉,每次的结果都不相同。过大偏离点为随机数据偏离平均值超过两个标准差。

2、神经网络的实现过程**:
①准备数据集,提取特征,作为输入喂给神经网路。
②搭建NN结构,从输入到输出(先搭建计算图,再使用会话执行)
(NN前向传播算法-》计算输出)
③大量特征数据喂给NN,迭代优化NN参数(用计算结果优化,机器自动训练参数)
(NN反向传播算法-》优化参数训练模型)
④使用训练好的模型预测和分类
3、前向传播:搭建模型,实现推理(以全连接网络为例)
这里视频中给出一个例子:

在纸上推理出各个矩阵:

神经网络的层数为计算层的层数,不计输入。
#变量初始化、计算图节点运算都要用会话(with结构)实现:
with tf.Session() as sess:
sess.run()
#如果是变量初始化:
init_op = tf.global_variables_initializer()
sess.run(init_op)
#如果是计算图节点运算,写入待运算的节点:
sess.run(y)
#用tf.placeholder占位,在sess.run函数中用feed_dict喂数据:
#喂一组数据:
x = tf.placeholder(tf.float32,shape=(1,2)) #2为特征数
sess.run(y,feed_dict={x:[[0.5,0.6]]})
#喂多组数据:
x = tf.placeholder(tf.float32,shape=(none,2))
sess.run(y,feed_dict={x:[[0.1,0.2],[0.2,0.3],[0.3,0.4],[0.4,0.5]]})
4、反向传播:训练模型参数,在所有参数上用梯度下降,使NN模型在训练数据上的损失函数最小。
损失函数(loss):预测值(y)与已知答案(y_)的差距
loss=tf.reduce_mean(tf.square(y_-y))
均方误差MSE:MSE(y_,y)= 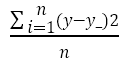
反向传播训练法:以减小loss值为优化目标,主要方法有梯度下降(tf.train.GrandientDescentOptimizer)、Momentum优化器(tf.train.MomentumOptimizer)、Adam优化器(tf.train.AdamOptimizer)
学习率:决定参数每次更新的幅度,一般选择比较小的值(0.001)
几个重要函数:
①numpy.random.seed()与numpy.random.RandomState()这两个在数据处理中比较常用的函数,两者实现的作用是一样的,都是使每次随机生成数一样。
②tf.reduce_mean()函数用于计算张量tensor沿着指定的数轴(tensor的某一维度)上的的平均值,主要用作降维或者计算tensor(图像)的平均值。
reduce_mean(input_tensor,
axis=None,
keep_dims=False,
name=None,
reduction_indices=None)
input_tensor: 输入的待降维的tensor;
axis: 指定的轴,如果不指定,则计算所有元素的均值;
keep_dims:是否降维度,设置为True,输出的结果保持输入tensor的形状,设置为False,输出结果会降低维度;
name: 操作的名称;
reduction_indices:在以前版本中用来指定轴,已弃用;
类似函数还有:
tf.reduce_sum :计算tensor指定轴方向上的所有元素的累加和;
tf.reduce_max : 计算tensor指定轴方向上的各个元素的最大值;
tf.reduce_all : 计算tensor指定轴方向上的各个元素的逻辑和(and运算);
tf.reduce_any: 计算tensor指定轴方向上的各个元素的逻辑或(or运算);
③tf.square(x, name=None)函数对x内的所有元素进行平方操作
④tf.random_normal()函数用于从服从指定正太分布的数值中取出指定个数的值。
tf.random_normal(shape,mean=0.0,stddev=1.0,dtype=tf.float32,seed=None,name=None)
shape: 输出张量的形状,必选
mean: 正态分布的均值,默认为0
stddev: 正态分布的标准差,默认为1.0
dtype: 输出的类型,默认为tf.float32
seed: 随机数种子,是一个整数,当设置之后,每次生成的随机数都一样
name: 操作的名称
5、小结:搭建神经网络的八股(准备、前传、反传、迭代)
准备:import、定义常量、生成数据集
前向传播:定义输入、参数和输出(x、y_、w1、w2、a、y)
反向传播:定义损失函数、反向传播方法(loss、train_step)
迭代:生成会话,训练STEPS轮
with tf.Session() as sess:
init_op = tf.global_variables_initializer()
sess.run(init_op)
#训练模型
STEPS = 3000
for i in range(STEPS):
start =
end =
sess.run(train_step, feed_dict={})
以上学习内容来自中国MOOC网课程:https://www.icourse163.org/course/PKU-1002536002















 772
772











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









