






论文 High-Performance Large-Scale Image Recognition Without Normalization
arXiv https://arxiv.org/abs/2102.06171
Github https://github.com/deepmind/deepmind-research/tree/master/nfnets
摘要
BN是大多数分类模型的关键组分,但因其依赖于batch的大小以及在样本间引入相关性,也存在许多不受欢迎的特点。虽然近期有文章成功不适用BN训练了较深的ResNet,但这些模型的测试准确率通常无法与最佳BN网络的结果比肩,且对于大学习率和强数据增强不稳定。在本文中作者提出了一种自适应梯度裁剪技术以克服这些问题,并设计了一类效果显著的网络NENets。在ImageNet上,较小的模型测试结果可以与EfficientNet-B7相当,训练时间则加快了8.7倍,而最大的模型取得了86.5%的SOTA指标。此外,在3亿数据集上预训练后在ImageNet微调,NFNets相比BN网络取得更加优异的表现,Top1准确率达89.2%。
简介
CV中的绝大多数模型是使用BN的深度残差模型,二者的结合使研究人员可以训练更深的网络,在训练集和测试集上取得更高的准确率。BN也平滑了损失函数,使模型在更大的学习率和batch size下可以稳定训练。此外也起到正则化效果。但BN也有以下三个问题:
-
额外的计算开销:额外占用内存,影响某些网络的梯度计算时间
-
在训练与推理时引入偏差
-
打破了训练样本间的独立性(BN的期望和方差都基于每个batch内的数据计算,不可避免引入样本间的相关性)
第三点带来了一系列的不良后果:BN网络在不同的硬件上难以精确复现,分布式训练时存在细微误差,不适用于某些网络和任务。若batch内数据方差较大,网络表现会有所退化,且对batch size较为敏感,小batch size下难以取得较好的结果,而batch size反过来限制了在有限硬件条件下可训练的模型尺寸。
因此,虽然BN推动深度学习获得了实质性进展,长远来看它仍有可能阻碍进步。尽管提出了一些替代方案,但在测试精度上较差且有自身的缺陷,如推理时额外的计算消耗。幸运的是,近年来出现了两个有前途的研究主题。一者研究训练时BN的收益来自何处,另一者试图不用归一化层训练深度ResNets以取得可相比拟的精度。
这些工作的一个关键主题是,通过抑制残差分支上隐含激活层的规模,可以在没有归一化的情况下训练非常深的 ResNet。实现这一点的最简单的方式是在每个残差分支的最后引入一个可学习的归一化因子,但仅靠这一点难以取得令人满意的测试精度。此外有工作表明ReLU激活函数引入了均值漂移,导致随着网络深度加深,不同训练样本的隐含激活层逐渐相关。最近也有工作提出了“Normalizer-Free” ResNets,在初始化时抑制残差分支并使用Scaled Weight Standardization去除均值漂移。辅以额外的正则化方法,这些非归一化网络在ImageNet上可以取得和BN ResNets相媲美的表现,但是在大batch size下不稳定且效果不如EfficientNets。本文的贡献如下:
-
提出了自适应梯度裁剪技术(AGC),根据梯度范数与参数范数在单元尺度上的比例裁剪梯度,并论证AGC允许训练更大batch size和更强数据增强的NFNets
-
设计了一系列Normalizer-Free ResNets, 称之为NFNets,在ImageNet上取得SOTA的指标。NFNet-F1的准确率和EfficientNet-B7相近,训练时间快8.7倍,且最大的NFNet在使用额外数据预训练的前提下获得了86.5%的SOTA指标
-
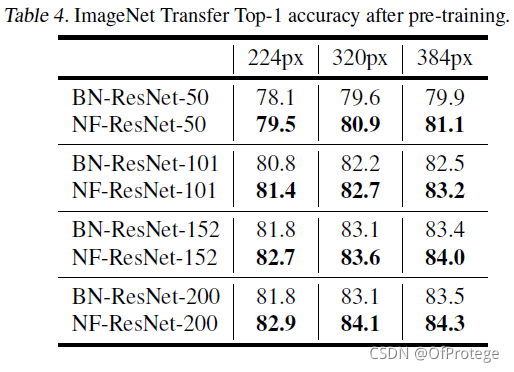
当使用3亿带标注数据预训练的前提下,NFNets比BN网络在ImageNet上取得了更高的验证集准确率。在微调后,最佳模型取得了89.2%的Top1准确率
BN
BN的主要优点如下:
-
BN减小了残差分支的规模:跳跃连接和BN是研究人员得以训练更深的网络。这主要得益于BN置于残差分支时减小了其隐含激活层的规模。(对BN如何downscale感兴趣的可以参考引文)
-
BN起到一定的正则化效应
-
BN允许高效的大Batch训练
移除BN
此处建议阅读Characterizing signal propagation to close the performance gap in unnormalized resnets,ICLR2021的文章。
文章使用了形式如下的残差模块
其中代表第i个残差模块的输入,
代表第i个残差分支的计算,
是激活层方差的增加速率,通常设为一个小数值如0.2,
是第i个残差模块的输入的标准差,
此外还引入了Scaled Weight Standardization
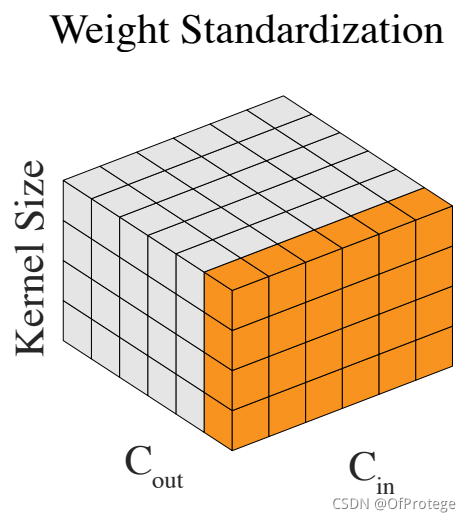
借助上图可以较好理解Weight Standardization,其实是对单个卷积核的参数进行标准化,N代表fan-in,即上图中黄色部分
而Scaled Weight Standardization
AGC
较为常见的梯度裁剪有两种,一种是给定对称区间[-value, value],大于value的梯度裁剪至value;另一种则是给定梯度范数的阈值,对于范数大于该阈值的梯度进行相应缩放,即文中所说的
另表示第l层权重矩阵,
表示
的梯度,
表示F范数,
AGC的主要思路是梯度的F范数与权重的F范数可以提供单次梯度下降对权重影响的度量。如果使用不带动量的梯度下降,那么
参数更新时,,h表示学习率
当较大时训练过程将不稳定,希望基于
去进行梯度裁剪。但在实际应用中,我们基于单元尺度的梯度范数与权重范数之比进行梯度裁剪,表现比整层裁剪更好,公式如下
其中是一个缩放超参,定义
,默认
以阻止零初始化的参数梯度一直被裁剪为零。卷积层中AGC应用在fan-in上。在AGC的帮助下,可以在更大的batch size和更强的数据增强如RandAugment下稳定训练NF-ResNets。最优的裁剪参数\lambda取决于优化器、学习率与batch size。通常batch越大,
越小。
消融实验
在ImageNet上训练pre-activation的NF-ResNet-50和NF-ResNet-200, batch size从256到4096,在[0.01, 0.02, 0.04, 0.08, 0.16]内
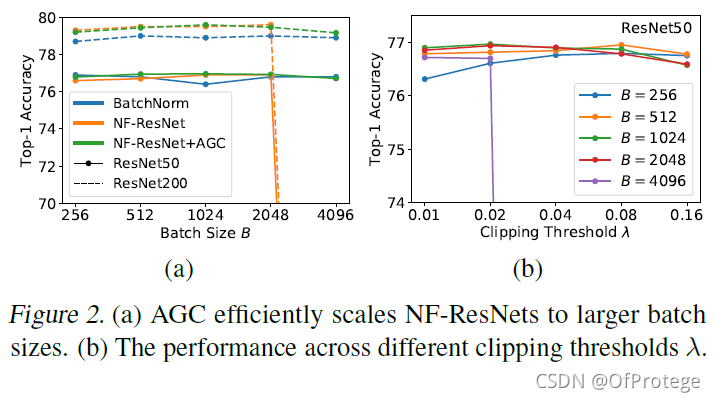
还有一组数据增强的实验
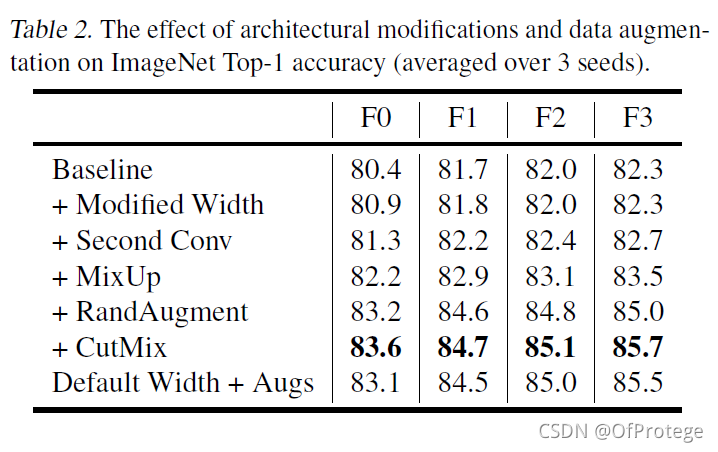
NF网络
提出了一系列NFNets,类似EfficientNets一样,深度、分辨率以及不同的Dropout。这一些列网络基于SE-ResNeXt-D,使用GELU作为激活函数,并出于对硬件性能与特点的考虑将卷积的group width设为128,并修改深度模式为[1, 2, 6, 3]的倍数,修改ResNets的通道模式[256, 512, 1024, 2048]至[256, 512, 1536, 1536], 使用了FixRes
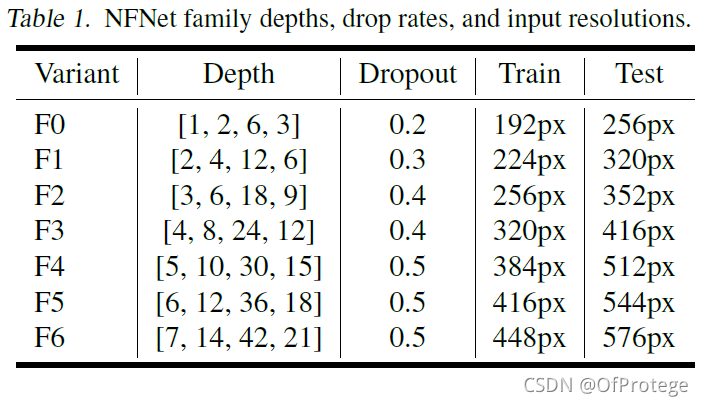
bottleneck block简要结构
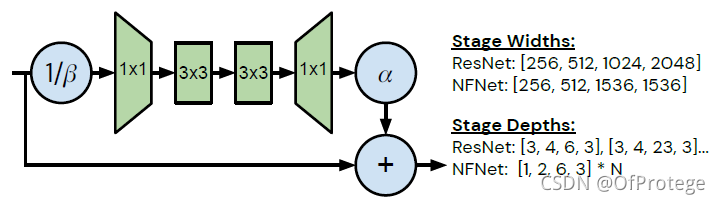
bottleneck block详细结构
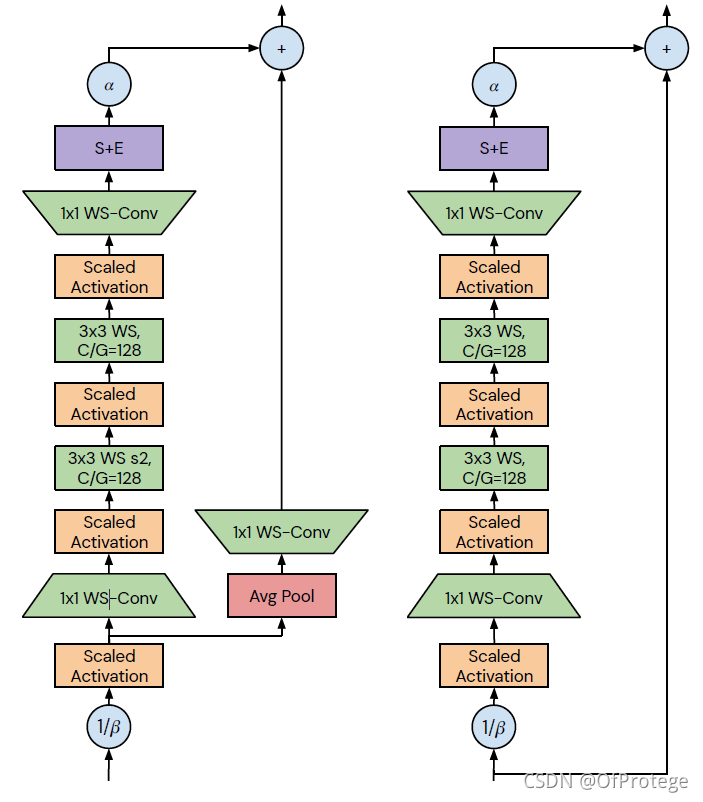
左侧为transition block,右侧为non-transition block,主要区别在于分支以及送入分支时是否被缩放
实验
从实验结果来看效果还是客观的
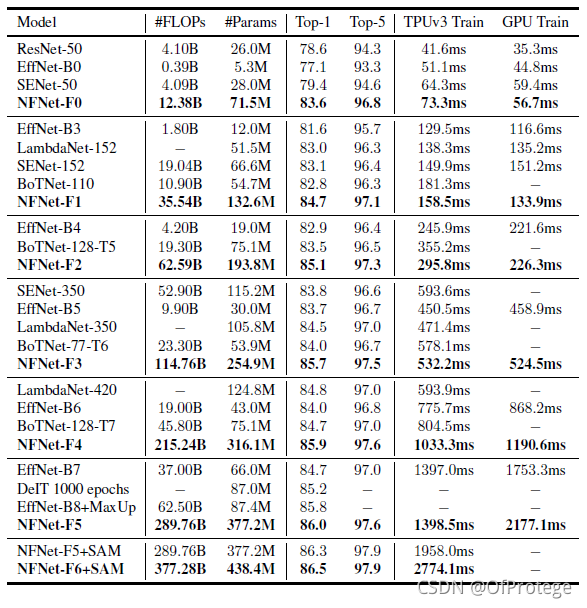
使用预训练的结果
最后谈一点个人看法,即使在Transformer当道的现在,NFNet在ImageNet上的表现也还是不错的。把大家用习惯了的BN层上做改进,是突破性的也很有意义。前段时间和NFNet打了一段时间交道因此回过头来把论文读一读,有一点不好的地方就是训练时间和占用的计算资源还是比较多的,即使用的是F2轻量化的版本。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









