







二分类问题指的是所有数据的标签就只有两种,正面或者负面。
一,准备数据
我们使用的数据是内置于Keras的IMDB数据集。它包含50000条两极分化的电影评论,正面评论和负面评论各占一半。其中25000用于训练,25000用于测试。
rom keras.datasets import imdb
#加载imdb数据集
(train_data,train_labels),(test_data,test_labels) = \
imdb.load_data(num_words=10000)#保留前10000个最常出现的单词数据已经被预处理,单词被转换成了整数,每个整数代表了某个单词,所以我们看到的是由单词索引组成的列表:
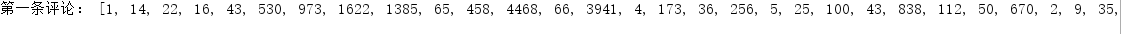 而标签则是0和1组成的列表,0代表负面,1代表正面:
而标签则是0和1组成的列表,0代表负面,1代表正面:

接下来我们要对数据进行one-hot编码,即所有数据都是10000维向量(因为数据最多也就出现一万个字,你只载入了前一万个最常出现的单词)他出现的数字的索引的值为1,其余为0,举个简单的例子,如果某个评论只有两个单词,即只有两个数字(假设为3和5),那么它就是[3,5],转为one-hot就变成10000维向量,只有索引3,5,的元素是1,其余都是0.
#将数据向量化
def vectoriza_sequences(sequences,dimension=10000):
results = np.zeros((len(sequences),dimension))
#生成一个元素全部为0,形状是数据长度*10000的二维numpy数组
for i, sequence in enumerate(sequences):
#enumerate()函数返回两个参数:元素下标,对应的元素
results[i,sequence] = 1
#这里i返回的就是0-24999,sequence返回的是一个列表。
return results
x_train = vectoriza_sequences(train_data)
x_test = vectoriza_sequences(test_data)如果对于 vectoriza_sequences不是很理解可以看一下这个简单的代码</
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









