







目录
一. 命名空间
在C/C++中,会涉及到许多的变量、函数以及类,如果全部存放在全局域中,则可能会引起命名冲突。使用命名空间的目的是对标识符进行本地化处理,将程序员定义的标识符单独放在一个与内,与全局域相隔离,从而避免命名冲突问题。
命名冲突的问题主要存在于以下两种场合:
- 程序员定义的函数和变量可能与库里面的重名。
- 在一个项目组中,不同的程序员定义的变量可能存在命名冲突。
由于C语言没有很好的办法解决命名冲突的问题,因此C++引入了一个新的语法概念:命名空间。
1.1 命名冲突问题
演示代码1.1中定义了一个int型的全局变量rand,希望在main中打印rand的值。但是运行程序编译器会报错rand重定义,因为在头文件stdlib中包含了函数rand,两个rand会发生冲突。在全局域中,编译器无法区分rand是函数还是int型变量,故报错。
演示代码1.1:
#include<stdio.h>
#include<stdlib.h>
int rand = 1; //定义全局变量rand
int main()
{
printf("%d\n", rand);
return 0;
}
1.2 命名空间的定义
使用命名空间关键字namespace,后面跟命名空间的名称,然后再后接一对括号,在括号内定义命名空间里的各种类型变量、函数或者类。
定义命名空间的本质是定义一个域,这个域与全局域分离,从而避免命名冲突。
1. 命名空间的常规定义
演示代码1.2在定义了一个名为N0的命名空间,其内部定义了整型变量rand = 1、结构体类型struct stu以及字符串类型数据ch[20]。在主函数中通过语句printf("%d\n", N0::rand)打印rand的值,没有报错命名冲突。
::是作用域限定符,N0::rand的意思是在作用域N0中查找rand变量,这样就忽略了全局域中的rand函数。
演示代码1.2:
#include<stdio.h>
#include<stdlib.h>
//定义命名空间N0
namespace N0
{
int rand = 1;
struct stu
{
char name[20];
int age;
};
char ch[20] = "abcde";
}
int main()
{
printf("%d\n", N0::rand); //打印命名空间N0中的rand
return 0;
}2. 命名空间的嵌套定义
命名空间的嵌套定义,就是在一个命名空间中,定义另一个命名空间。演示代码1.3中定义了一个命名空间N1,并在命名空间N1中嵌套定义命名空间N2,N2中还定义了一个函数Add。
演示代码1.3:
//定义命名空间N0
namespace N1
{
int rand = 1;
//命名空间N1中嵌套定义N2
namespace N2
{
int Add(int x, int y)
{
return x + y;
}
}
}3.同一工程中定义多个名称相同的命名空间
如果一个工程中定义了多个名称相同的命名空间,则两个相同名称的命名空间会被合并为一个。
在演示代码1.4中,定义了两个名称相同的命名空间N0,在两个命名空间中分别定义int型变量x=1和y=2,在主函数中调用语句printf("x = %d\ny = %d\n", N1::x, N1::y),运行程序,不会报错。
演示代码1.4:
//定义命名空间N1
namespace N1
{
int x = 1;
}
//再次定义命名空间N1
namespace N1
{
int y = 2;
}
int main()
{
printf("x = %d\ny = %d\n", N1::x, N1::y);
return 0;
}1.3 命名空间的使用
命名空间中的成员的使用方法有三种:使用作用域限定操作符、使用using吸入命名空间中的成员变量、使用using吸入整个命名空间。
使用作用域限定操作符
作用域限定操作符::的功能是让编译器去某个指定的域中寻找成员变量。如N1::x = 0的意思就是将命名空间N1里的变量x赋值为0。
对于在某个命名空间内嵌套定义的命名空间中的成语也可以使用作用域限定操作符来使用,如N1::N2::y = 1,就是将命名空间N1中嵌套定义的命名空间N2中的成员y赋值为1。
演示代码1.5:
namespace N1
{
int x;
namespace N2
{
int y;
}
}
int main()
{
N1::x = 0;
N1::N2::y = 1;
printf("x = %d\ny = %d\n", N1::x, N1::N2::y);
return 0;
}使用using将命名空间中的某个成员引入
使用using关键字,可以将某个命名空间域中的变量引入到全局域。如语句using N0::x的功能是将命名空间N0中的变量x引入全局域。这样在主函数中使用x时,就不需要再添加作用域限定操作符,提高了便捷度。
一般对于在命名空间中定义的,经常会被使用到的成员,可以考虑使用using将其引入到全局域。演示代码1.6中使用using N0::x将命名空间中的x引入,在主函数中使用printf("x=%d\n", x)就可以直接打印出x的值。
演示代码1.6:
namespace N0
{
int x = 1;
}
using N0::x; //将x引入全局域
int main()
{
printf("x = %d\n", x); //成功输入x = 1
return 0;
}使用using将整个命名空间引入
演示代码1.7中使用using namespace N0将整个命名空间N0引入到全局域,这样N0中的所有变量也就被引入到了全局域。
对于使用using将整个命名空间引入到全局域的做法要慎用,因为这会使命名空间失去隔离作用,容易造成命名冲突问题。
演示代码1.7:
namespace N0
{
int x = 1;
int y = 2;
}
using namespace N0; //将命名空间N0引入全局域
int main()
{
printf("x = %d\n", x); //输出x = 1
printf("y = %d\n", y); //输出y = 2
return 0;
}二. C++中的输入和输出
2.1 C++输入输出相关操作符和语法
cout << "hello word" << endl 的功能:会在屏幕上输出字符串"hello word"加换行。
cin >> x >> y 的功能:从标准输入流(键盘)中读取两个值,分别赋给变量x和变量y。
- cout为标准输出对象(一般为屏幕),cin为标准输入对象(一般为键盘)。使用cout和cin时,必须包含头文件<iostream>。
- endl为C++中的换行符,相当于C语言中的'\n'。
- <<为流插入操作符,>>为流提取操作符。
因此,cout << "hello word" << endl的执行逻辑为:先将endl插入到字符串"hello world"中,然后再在"hello world\n"插入到标准输出对象cout。
演示代码2.1中展示定义了一个双精度浮点型数据x和一个整型数据y,先通过cin >> x >> y读取x和y的值,然后再使用语句cin >> x >> y输入。代码中有语句using namespace std的原因是:std是C++标准库中的命名空间,而C++将标准库的定义和实现均放在std这个命名空间中。
演示代码2.1:
#include<iostream>
using namespace std; //将C++标准库所在的命名空间std引入到全局域
int main()
{
double x;
int y;
cin >> x >> y; //从键盘上读取x和y
cout << x << endl << y << endl; //分行输出x和y的值
return 0;
}std命名空间的使用惯例:
- 在平常练习时,可以直接使用using namespace std将整个std命名空间引入全局域以方便使用。
- 在工程项目中,建议采用std::cout这样的语句来使用std中的成员。因为一旦将std展开,std就失去了其隔离的作用,程序员定义的类型/函数/对象与库中的重名,就很容易造成命名冲突。
2.2 C++和C语言输入输出的对比
C++输入输出主要采用cin和cout,C语言输入输出主要采用scanf和printf。在一个C++项目中,使用C++的cin、cout实现输入输入和采用C语言的scanf、printf实现输入输出均可。两者的不同主要在于:
- C语言输入输出需要指定格式,而C++不需要,cout和cin可自动识别变量类型。
- 采用printf输出相比于cout更容易控制输出长度、小数点后面的位数等输出格式,虽然cout也可以实现对输出格式的控制,但却十分麻烦,这是C语言的语法相对于C++就有明显的优势。
注意:C++本质上是C语言的升级版,因此C++兼容C语言几乎全部的语法格式。
演示代码2.2中定义了结构体类型struct stu,其中包含两个成员char name[20]和int age。在主函数中,采用C++和C语言的语法换行打印两个结构体成员值,并添加前缀name和age。如果要一行输出两个成员值,C++的语句为:cout<< "姓名:"<<s.name<<endl<< "年龄:"<<s.age<<endl,而C语言的语句为:printf("姓名:%s\n年龄:%d\n", s.name, s.age),此时使用C语言的语法明显优于使用C++的语法。
演示代码2.2:
#include<iostream>
using namespace std; //将C++标准库所在的命名空间std引入到全局域
struct stu
{
char name[20];
int age;
};
int main()
{
struct stu s = { "zhangsan", 20 };
//C++输入输出
cout << "姓名:" << s.name << endl << "年龄:" << s.age << endl;
//C语言输入输出
printf("name:%s\nage:%d\n", s.name, s.age);
return 0;
}
三. 缺省参数
3.1 缺省参数的定义
缺省参数是声明或定义函数时为函数的参数指定一个缺省值。在调用该函数时,如果没有指定实参则采用该形参的缺省值,否则使用指定的实参。
注意:C语言不支持缺省参数。
演示代码3.1定义函数void fun(int a = 0),在主函数中,通过fun(10)和fun()调用函数fun,fun(10)相对于将10作为参数传给fun,fun()省略了参数,故默认将0传给函数fun。
演示代码3.1:
void fun(int a = 0)
{
cout << a << endl;
}
int main()
{
fun(10); //输出10
fun(); //输出0
return 0;
}3.2 缺省参数的分类
全缺省参数
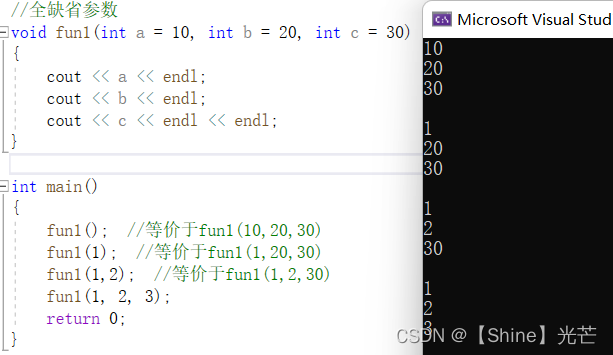
全缺省参数,即所有的参数都给与缺省定义,如:func1(int a = 10, int b = 20, int c = 30),调用函数时若不给定参数值,a、b、c三个参数的默认值分别为10、20、30。
演示代码3.2:
//全缺省参数
void fun1(int a = 10, int b = 20, int c = 30)
{
cout << a << endl;
cout << b << endl;
cout << c << endl << endl;
}
int main()
{
fun1(); //等价于fun1(10,20,30)
fun1(1); //等价于fun1(1,20,30)
fun1(1,2); //等价于fun1(1,2,30)
fun1(1, 2, 3);
return 0;
}
半缺省(部分缺省)参数
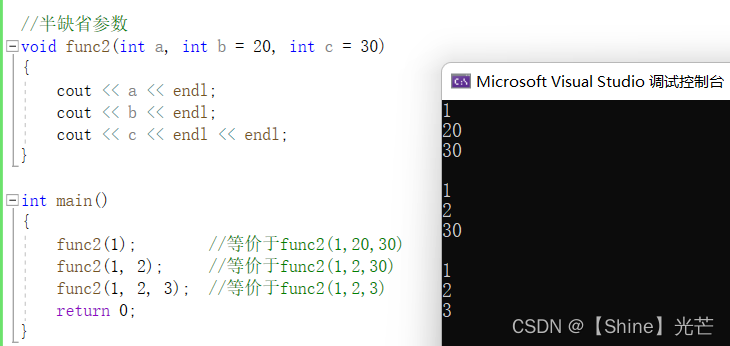
半缺省参数,即在定义一个有多个参数的函数时,一部分参数给定缺省值,一部分不给缺省值。如fun2(int a, int b = 20, int c = 30)就是典型的半缺省,参数a没有给定缺省值,参数b和c分别给定缺省值20和30。
演示代码3.3:
//半缺省参数
void func2(int a, int b = 20, int c = 30)
{
cout << a << endl;
cout << b << endl;
cout << c << endl << endl;
}
int main()
{
func2(1); //等价于func2(1,20,30)
func2(1, 2); //等价于func2(1,2,30)
func2(1, 2, 3); //等价于func2(1,2,3)
return 0;
}
注意:
- 缺省参数必须从右往左给定,不能从左往右或间隔给定。如:func2(int a,int b=20,int c=30)及fun2c(int a, int b, int c=30)是合法的,而func2(int a = 10, int b, int c)和func2(int a = 10, int b, int c = 30)是不合法的。
- 不能在函数的声明和定义中同时出现缺省参数。缺省参数应当出现在函数的定义和声明其中之一,但一般推荐缺省参数出现在声明中。
- 缺省值必须为常量或全局变量。
- 一定要在.cpp编译环境下才能使用缺省参数,C语言不支持缺省参数。
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









