







目录
一. 认识URL
1.1 URL的概念及格式
我们通常使用网址来访问一个网址,URL就是我们常说的网址。

URL的通用格式见图1.2,真正在使用URL访问网站时,不一定每个部分都出现在URL中。

1.2 URL编码和解码
我们在查询一些资源的时候,那么会用到一些和URL标准格式中固有字符相冲突的字符,这些字符如果直接使用在URL中,就可能会引发误读从而错误解析URL。
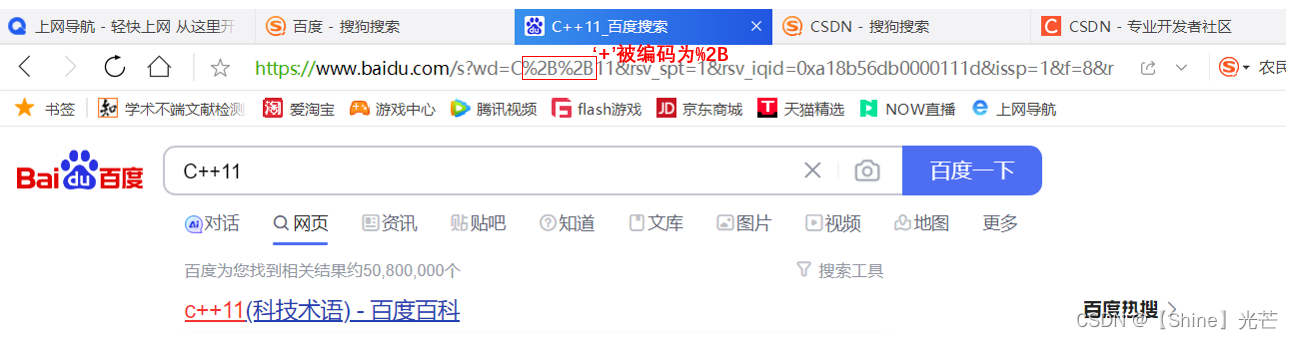
这些特殊字符,必须通过特定的编码规则,转变为不发生冲突的字符,再写入到URL中,如图1.3所示在百度搜索引擎中搜索C++11,其中字符'+'就被编码为%2B。
转义规则:将需要转义的字符对应的编码值写为16进制,从右到左取4位,每两位算做一组,前面加上%,最终转义格式为%XY。
二. http的请求和响应信息
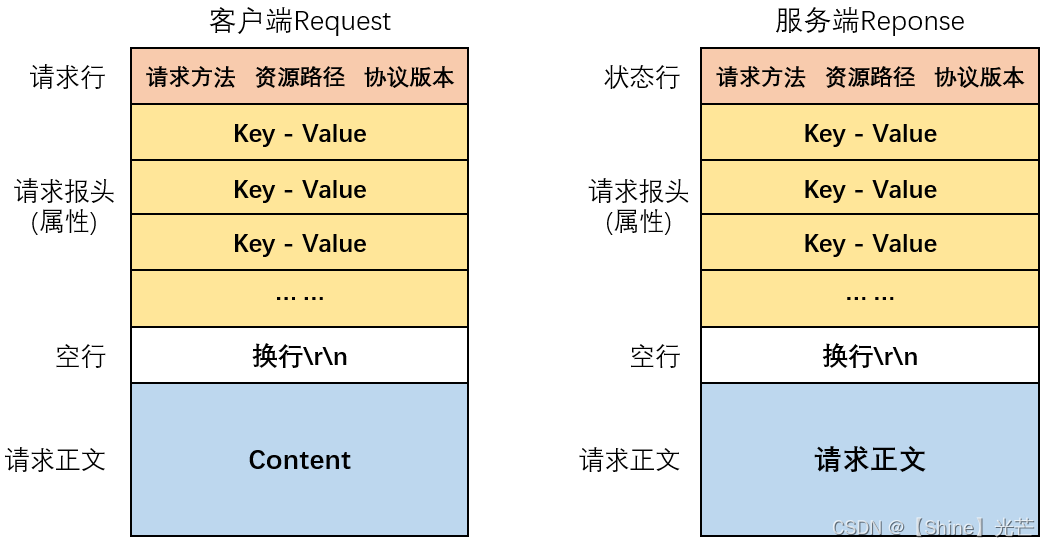
在使用HTTP协议通讯时,客户端向服务端发送的请求信息以及服务端返回客户端的信息,都遵循特定的格式,可以总结为:请求行/状态行、请求报头(属性信息)、正文。
其中客户端发送给服务端的请求包括请求方法(GET、POST等)、访问资源的路径、协议版本,服务端发回客户端的信息包括协议版本、错误码以及错误码描述信息。
需要特别强调的是访问资源的路径是相对于系统本身的路径的,并不是这台机器的根目录开始的路径。一般而言,如果在url中不显示的指出路径,那么服务端就会默认接收到"\"表示根目录,而在服务端程序中,根目录一般显示给定。
代码2.1:客户端向服务器发送的请求信息
GET / HTTP/1.1
Host: 175.178.238.165:8080
Connection: keep-alive
Cache-Control: max-age=0
Upgrade-Insecure-Requests: 1
User-Agent: Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/94.0.4606.71 Safari/537.36 Core/1.94.186.400 QQBrowser/11.3.5199.400
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9
Accept-Encoding: gzip, deflate
Accept-Language: zh-CN,zh;q=0.9
Real Content -- 正文内容三. 建立简单的http通信
Http协议通信底层是通过TCP协议来实现的,所以要依次创建套接字、绑定端口号、建立链接等操作。服务端在接收到客户端的请求信息时,截取所请求的资源,即:第一行请求行中的资源路径。服务器将客户端请求的资源作为Reponse的正文内容,并配以状态行和报头(属性信息),发回给客户端即可。
注意:如果客户端用户在url中不显示给出要访问资源在服务器中的路径,那么服务器收到的资源路径就会说"/",表示服务器的根目录。一般在服务器程序中,根目录下会存放默认的资源文件,当检测到资源路径为"/"时,就访问默认资源。
代码gitee链接:Linux Learning: Linux系统和网络编程学习文件 - Gitee.com
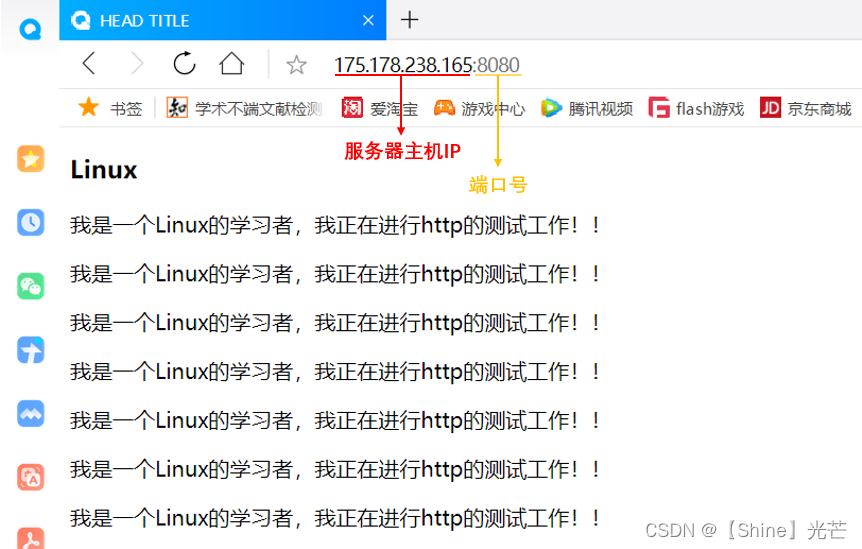
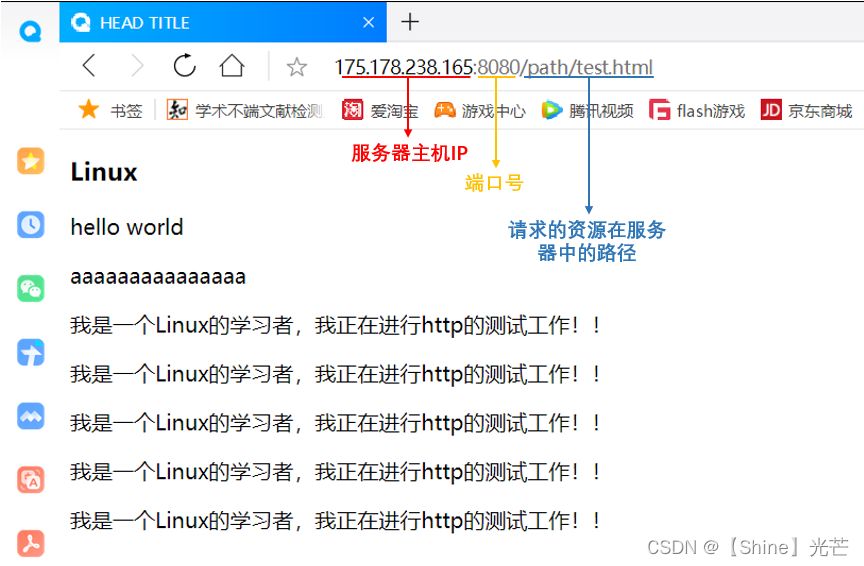
对于通信的测试,我们不需要再撰写客户端代码来进行,只需要在浏览器中,输入主机ip+端口号即可,我们还可以输入要访问的资源(文件)所在的路径,指定服务器返回给客户端正文的内容。图3.1和3.2为测试方法,图3.1没有显示给出路径,因此返回默认根目录wwwroot/index.html中的内容,显示出对应的前端界面,图3.2给出了访问文件的路径/path/test.html,显示出对应前端界面。
四. http协议内容解读
4.1 http方法
我们平常上网进行的操作分为两种:(a). 向服务器传输资源 (b).从服务器获取资源,在http中最常用的两种方法为GET和POST,可实现资源的传输和获取。其余的方法在很多服务器中会被禁止,以免恶意操作或操作失误引发不可预期的后果。而LINK和UNLINK仅支持HTTP1.0版本,已经被淘汰。
| 方法 | 意义 | 支持HTTP版本 |
|---|---|---|
| GET | 获取资源 | HTTP1.0 HTTP1.1 |
| GET、POST | 向服务器传输资源 | HTTP1.0 HTTP1.1 |
| HEAD | 获取报文首部 | HTTP1.0 HTTP1.1 |
| DELETE | 删除文件 | HTTP1.0 HTTP1.1 |
| OPTIONS | 查询支持的方法 | HTTP1.1 |
| TRACE | 路径追踪 | HTTP1.1 |
| CONNECT | 要求隧道协议链接代理 | HTTP1.1 |
| LINK | 建立和资源之间的联系 | HTTP1.0 |
| UNLINK | 断开和资源之间的链接 | HTTP1.0 |
GET和POST方法都可以实现向服务器传输资源,但是他们存在着一定的不同,通过测试来观察不同。为了进行测试,首先要对表单有一定了解。
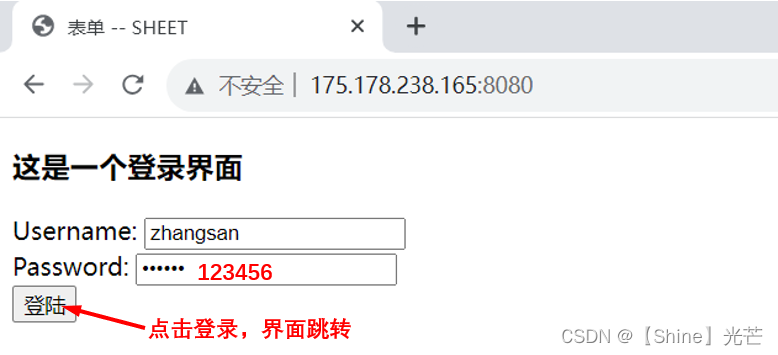
表单是用于向服务器传递数据的,文件后缀名为.html,其中可以指定方法、路径以及协议版本,还可以为前端界面添加各种组件。代码4.1为典型的表单,其中,<head></head>之间的内容我们不需要关注,而<form name="input" action="/a/b/kk.html" method="POST">中的name赋值为input表示输入数据,action表示要访问资源的地址,method表示方法。Username为用户名输入框,Password为密码输入框,<input type="submit" value="登陆">表示登录按钮。
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta http-equiv="X-UA-Compatible" content="IE=edge">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title> 表单 -- SHEET </title>
</head>
<body>
<h3>这是一个登录界面</h3>
<form name="input" action="/path1/path2/test.html" method="POST">
Username: <input type="text" name="user"> <br/>
Password: <input type="password" name="pwd"> <br/>
<input type="submit" value="登陆">
</form>
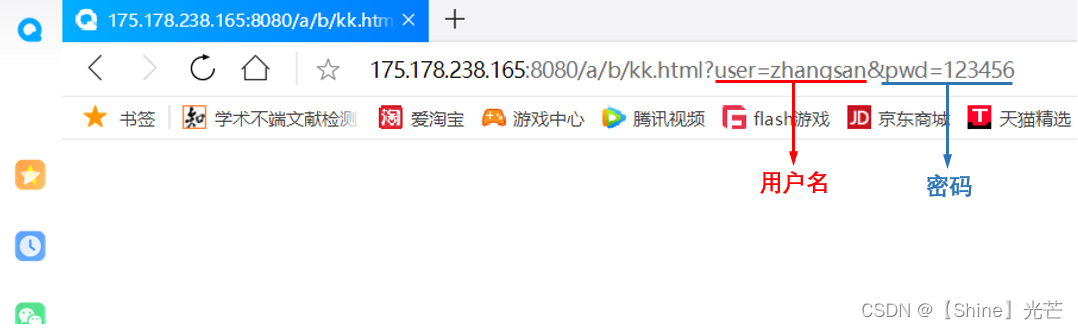
</html>采用GET方法,通过IP地址和端口号连接服务器,输入用户名和密码后,点击登录按钮,发现用户名和密码被回显到了url中,可见,GET方法是通过url传参的,安全性无法保障。
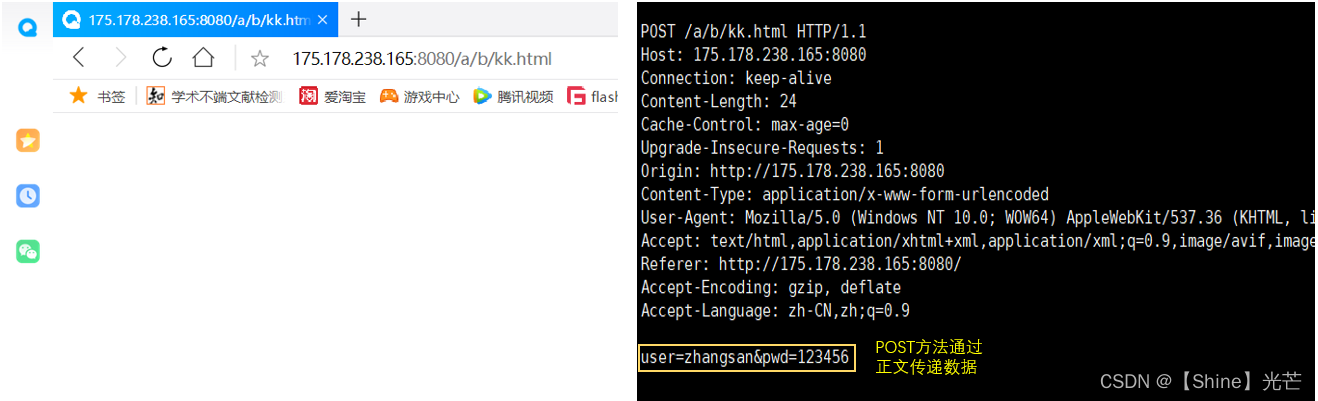
如果将方法改为POST,那么用户名和密码就不会再回显到url中,而客户端向服务端请求的正文信息中,就会包含用户名和密码信息,得出结论:POST是通过正文传参的。虽然看似用户名和密码不会显示的出现的用户界面上,但只要是通过原文发生信息,安全性就无法保证,加密发送才能够保证用户信息的安全性。
4.2 http状态码
服务器向客户端返回信息的时候,通常要配有错误码,常见的错误码及对应描述见表4.2。其中,每个状态码都对应于特定的描述信息。
| 错误码 | 所属类别 | 含义 |
|---|---|---|
| 1XX | 信息性状态码 | 服务器正在处理请求 |
| 2XX | 成功状态码 | 请求正常处理完毕 |
| 3XX | 重定向状态码 | 需要附加操作以完成请求 |
| 4XX | 客户端异常状态码 | 服务器无法处理请求 |
| 5XX | 服务器异常状态码 | 服务器处理请求出错 |
其中,常见的错误码及对应的描述信息如下:
- 200 -- OK,表示服务器成功处理用户请求。
- 302 -- 重定向,用户访问希望资源A,但服务器重定向到了资源B。
- 404 -- Not Found,未找到资源,一般用于出现于用户访问不存在资源的情况。
- 403 -- Forbidden,用户企图访问不具有访问权限的资源。
- 502 -- Bad Getway,服务器处理异常。
4.3 http常见的header
表4.3为http常见的header及其对应的信息,http请求和响应信息通常使用key-value的格式来匹配,其中header就是键值key,而其后跟的信息就是value。
| header | 含义 |
|---|---|
| Content-Type | 正文类型 |
| Content-Length | 正文长度(字节数) |
| Host | 客户端告知服务器,所请求的资源在哪个主机的哪个端口上 |
| User-Agent | 声明用户的操作系统和浏览器版本信息 |
| refer | 声明当前页面从哪个页面跳转而来 |
| Location | 配合状态码3XX,声明要跳转到哪个页面 |
| Cookie | 用于会话功能的实现 |
以Location为例,如果希望实现跳转功能,那么就需要在服务器发送给客户端的信息中添加Loaction:目标网站 这样的报头信息。
假设在接收到用户端的某一请求后,要跳转到百度的首页,那么服务器发送给客户的信息就应当包含 --"Loaction:https://www.baidu.com/index.html"。
五. 会话管理
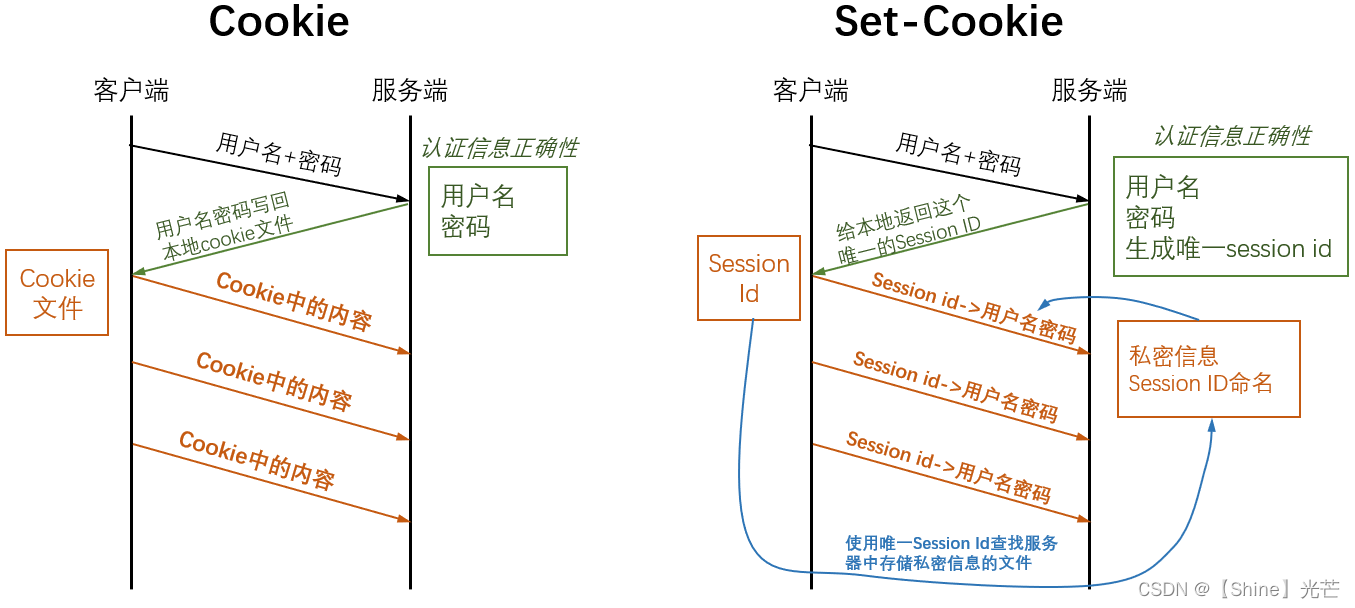
我们在登录一个网站时,第一次登录一定需要输入用户名和密码,然而之后一段时间在登录的时候,往往只需要自动进入页面,就默认处于登录状态,极大提高了便利程度,这种功能就是通过会话管理来实现的,Cookie和Set-Cookie可以用于进行会话管理。
使用Cookie进行会话管理的原理:当用户第一次登录时,输入用户名和密码,服务器检测输入正确后,会在本地浏览器建立一个内存级或文件级的cookie文件,用于存放用户的相关信息,下次用户在进入该网站时,客户端就会拿着cookie文件中的信息发送给服务器,就达到了在用户看来自动登录的效果。
但是使用Cookie进行会话管理是非常不安全的,如果黑客通过恶意程序拿到了用户的Cookie文件,用户名和密码等隐私信息就被盗走了,保密性极差,因此目前Cookie进行会话管理这种方法已经基本被淘汰。
使用Set-Cookie进行会话管理的原理:用户在第一次登录时,服务器会通过指定的算法生成唯一的一个Session Id,并将这个Session Id返回给客户端,当用户再次登录时,就可以拿着这个唯一的Session Id找到服务器中的文件,进而获取用户名和密码成功登录。
使用Set-Cookie进行会话管理也不能保证绝对的安全性,如果黑客拿到了这个Session Id照样可以以用户的身份登录去执行一下操作,但是,这样不会泄露用户私密信息,并且现代互联网厂商都会采用检测IP属地、一段时间后Session Id自动失效等方式来提高安全性。
六. 总结
- url就是平常我们所说的网址,url遵循特定的格式,发生冲突的字符需要按照特定的编码方式转变后再写入到url中。
- http客户端请求服务器和服务器发回给客户端的信息都遵循特定的格式:请求行/状态行、报头(属性信息)、空行、正文内容。
- http有多种方法,最常用的为GET和POST,GET可用于获取服务器资源,GET和POST均可用于向服务器传递资源,其中GET通过url传参,POST通过正文传参。
- Cookie和Set-Cookie两种方法可实现会话管理功能。















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









