






6.1 Shared Memory 更进一步
【思考】在使用global memory来做矩阵乘法的优化时,一共做了多少次memory的读写操作?
Shared Memory是唯二的片上存储单位,所以它也是目前最快的可以让多个线程沟通的地方。但是,就有可能会出现同时有很多线程访问Shared Memory上的数据,为了克服这个同时访问的瓶颈,Shared Memory被分成32个逻辑块(banks)。

bank的中文翻译为存储体,GPU 共享内存是基于存储体切换的架构(bank-switched-architecture),一般现在的GPU都包含32个存储体,即共享内存被分成了32个bank;根据GPU计算能力的不同(Compute Capability),每个共享内存存储体的宽可以是32位(CC2.x)或64位(CC3.x以上),即连续的32-bits(或64-bits)字被分配到连续的32个bank中。
- Shared Memory可以被设置成16Kb、32Kb…剩下的给L1缓存。
- 共享内存存储体的带宽可以使用32bit 或 64bit
- 多个bank可以同时响应更多地址申请
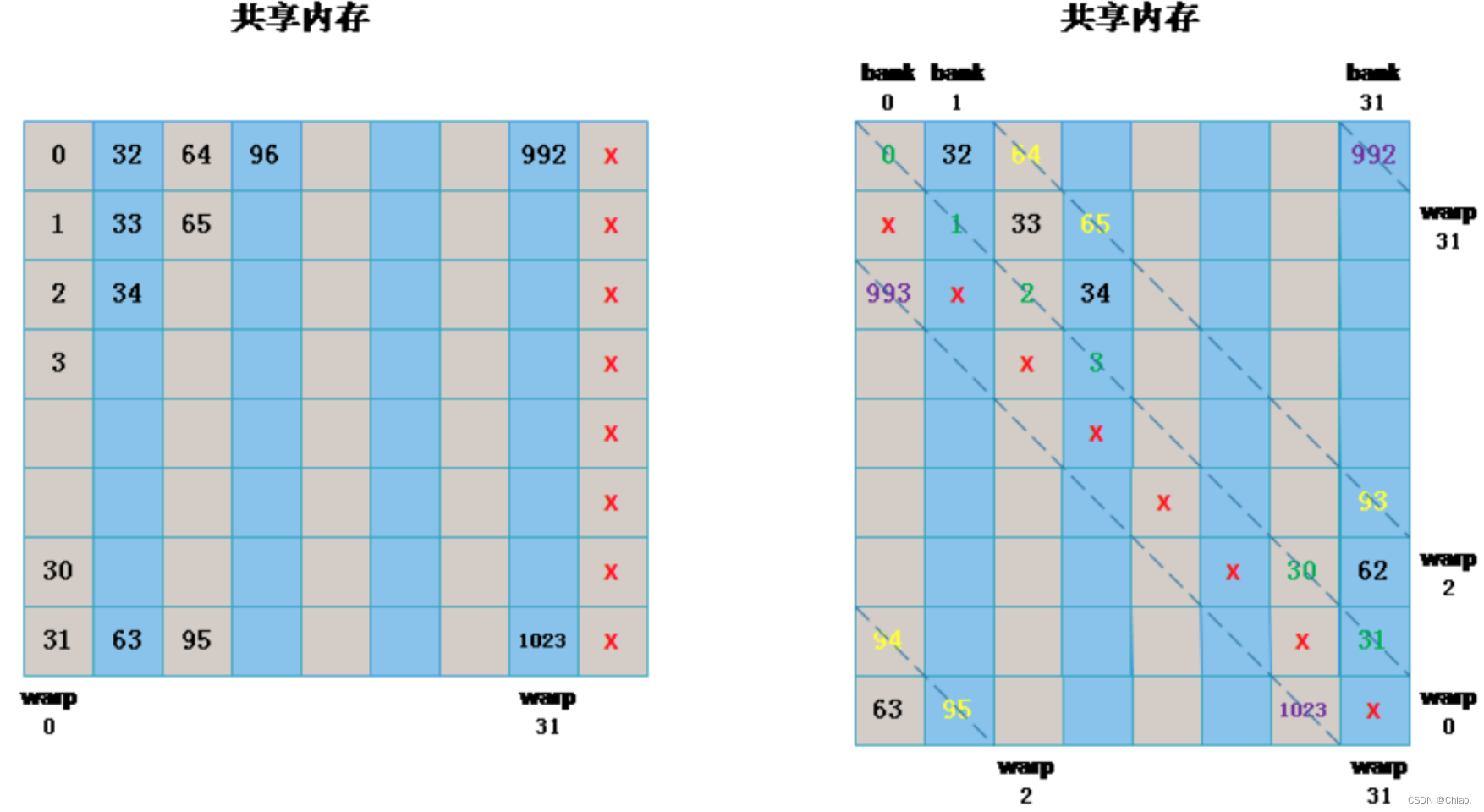
在共享内存中,连续的32-bits字被分配到连续的32个bank中,这就像电影院的座位一样:一列的座位就相当于一个bank,所以每行有32个座位,在每个座位上可以“坐”一个32-bits的数据(或者多个小于32-bits的数据,如4个char型的数据,2个short型的数据);而正常情况下,我们是按照先坐完一行再坐下一行的顺序来坐座位的,在shared memory中地址映射的方式也是这样的。下图中内存地址是按照箭头的方向依次映射的:
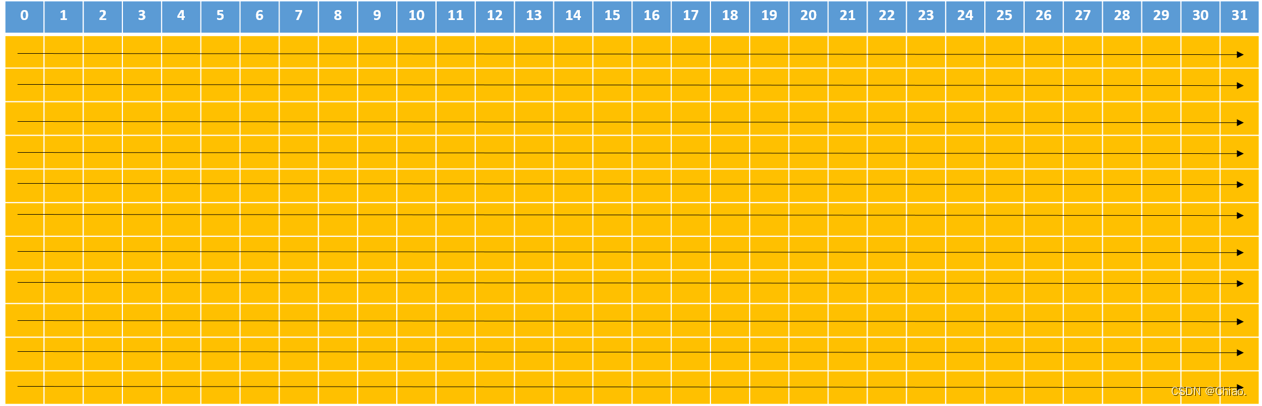
上图中数字为bank编号。这样的话,如果你将申请一个共享内存数组(假设是int类型)的话,那么你的每个元素所对应的bank编号就是地址偏移量(也就是数组下标)对32取余所得的结果,比如大小为1024的一维数组myShMem:
- myShMem[4]: 对应的bank id为#4 (相应的行偏移量为0)
- myShMem[31]: 对应的bank id为#31 (相应的行偏移量为0)
- myShMem[178]: 对应的bank id为#18 (相应的行偏移量为5)
6.2 Bank Conflict
- 同常量内存一样,当一个warp中的所有线程访问同一地址的共享内存时,会触发一个广播(broadcast)机制到warp 中所有线程,这是最高效的。
- 如果同一个 half-warp/warp 中的线程访问同一个bank 中的不同地址时将发生 bank conflict。
- 每个 bank 除了能广播(broadcast)还可以多播(mutilcast)(计算能力 ≥ \geq ≥ 2.0),也就是说,如果一个warp 中的多个线程访问同一个bank的同一个地址时(其他线程也没有访问同一个bank 的不同地址)不会发生bank conflict。
- 即使同一个 warp 中的线程 随机的访问不同的 bank,只要没有访问同一个 bank 的不同地址就不会发生bank conflict。
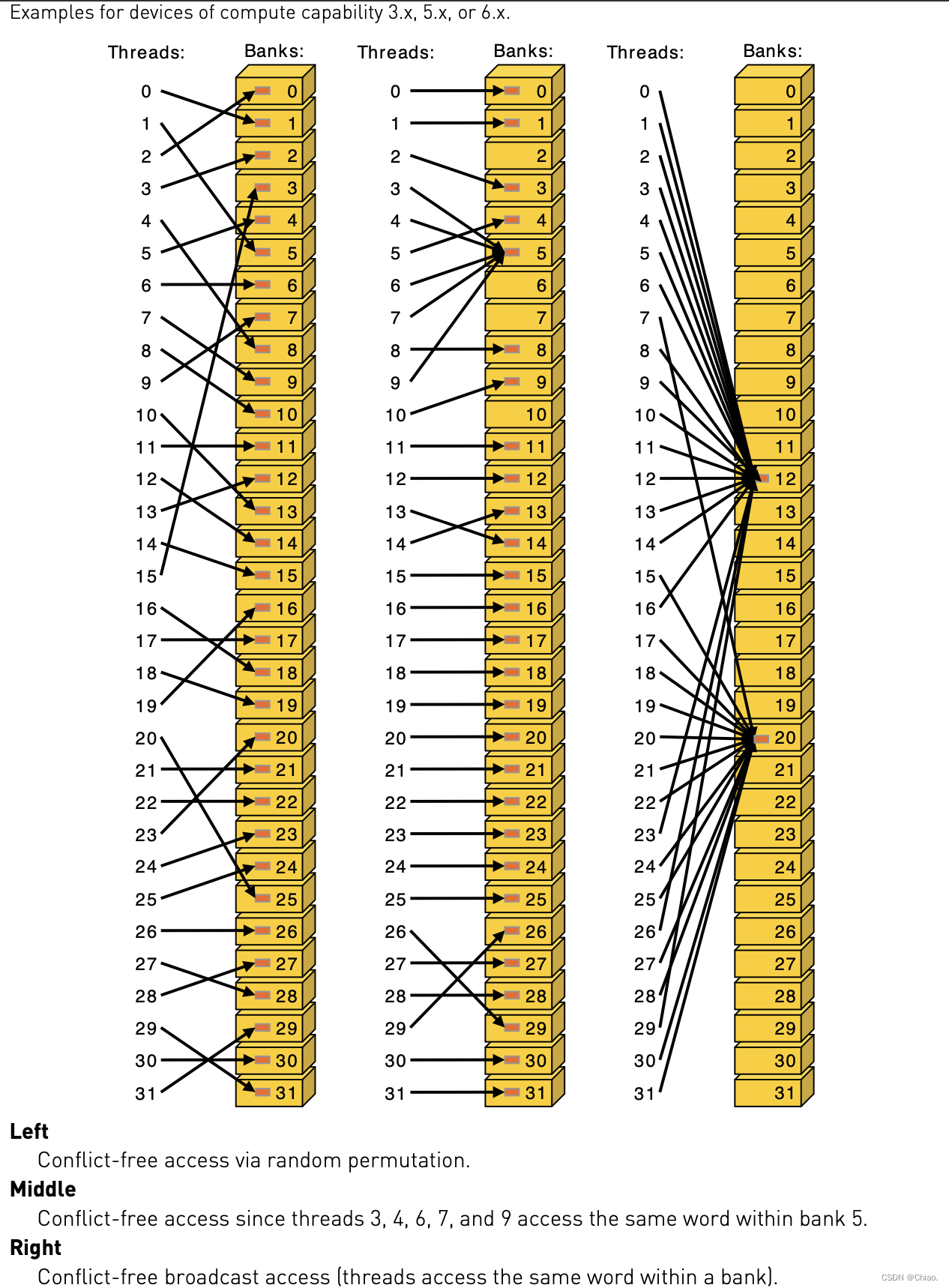
如果没有冲突的话,Shared Memory跟registers几乎一样快。
- 快速情况:
- warp内所有线程访问不同banks,没有冲突
- warp内所有线程读取同一地址,没有冲突(广播机制)。
- 慢速情况:
- Bank Conflict: 同一个warp中的不同线程访问同一个Bank就会发生Bank Conflict。总之就是,同一个Bank在同一时间周期内只能响应同一个warp的一次请求。
- 访存必须串行化
- 代价=多个线程同时访问一个bank的线程数最大值
没有发生Bank conflict的情况
一个warp中的相邻线程刚好访问shared memory中的相邻地址(访问步长为1),如下图所示。
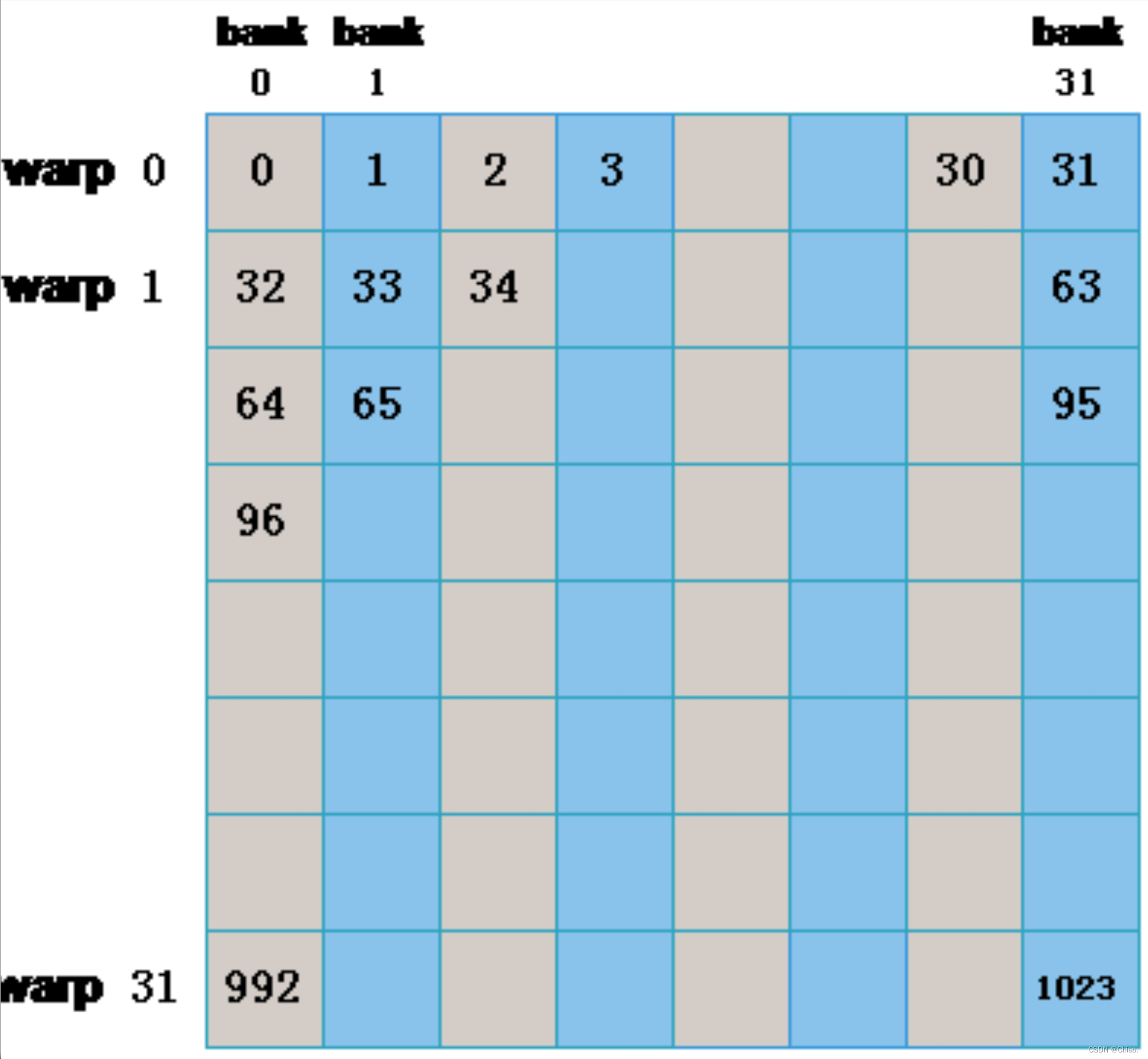
int x_id = threadIdx.x + blockDim.x * blockIdx.x;
int y_id = threadIdx.y + blockDim.y * blockIdx.y;
int index = y_id * col + x_id;
__shared__ float sData[BLOCKSIZE][BLOCKSIZE];
if(x_id < col && y_id < row){
sData[threadIdx.y][threadIdx.x] = matrix[index];
__syncthread();
matrixTest[index] = sData[threadIdx.y][threadIdx.x];
}
发生Bank conflict的情况
一个warp中的相邻线程刚好访问shared memory中一个Bank内的相邻地址(访问步长为32),如下图所示。
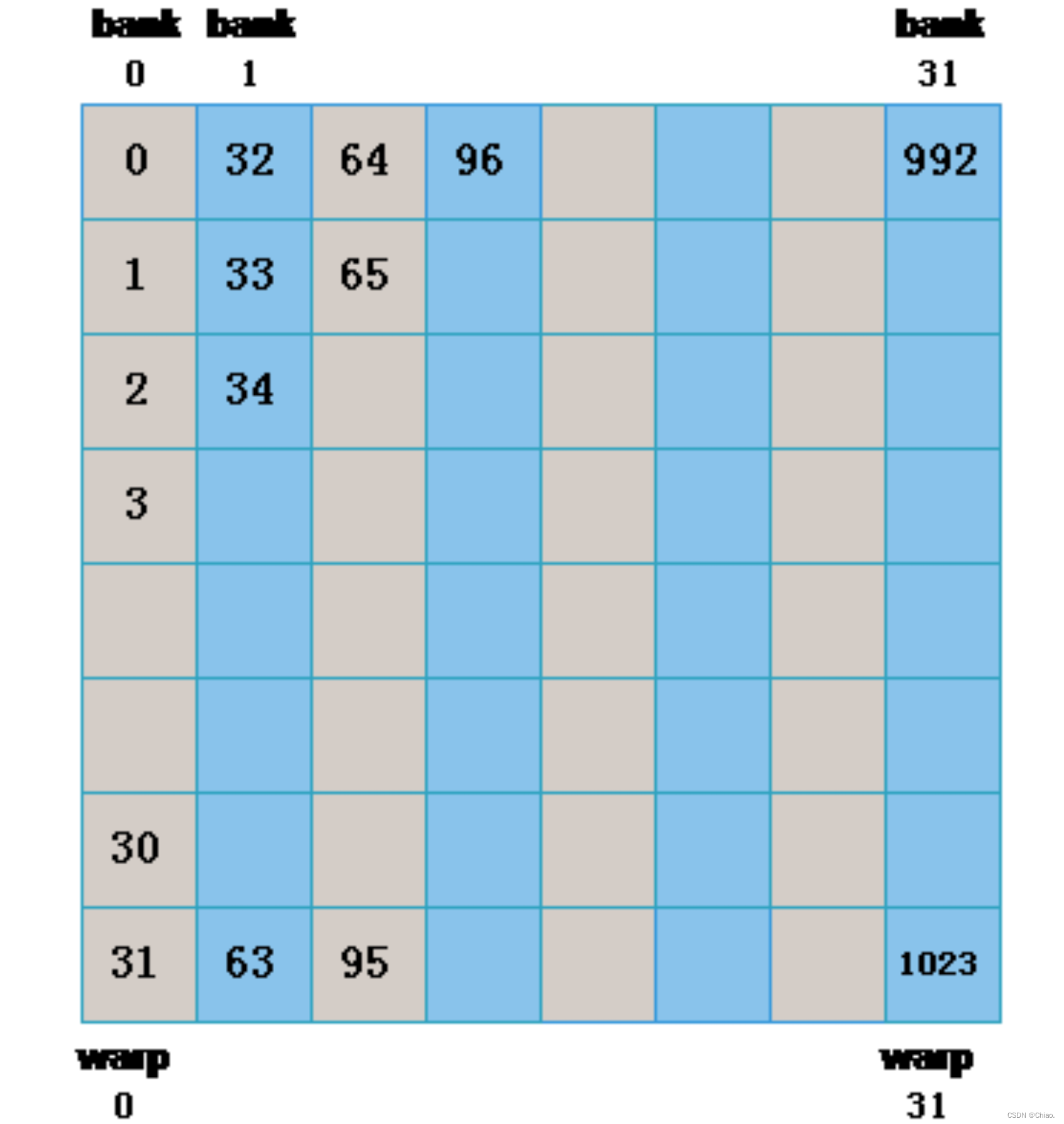
上述访问方式的代码实现:
int x_id = threadIdx.x + blockDim.x * blockIdx.x;
int y_id = threadIdx.y + blockDim.y * blockIdx.y;
int index = y_id * col + x_id;
__shared__ float sData[BLOCKSIZE][BLOCKSIZE];
if(x_id < col && y_id < row){
sData|\colorbox{OrangeRed!20}{[threadIdx.x][threadIdx.y]}| = matrix[index];
__syncthread();
matrixTest[index] = sData|\colorbox{OrangeRed!20}{[threadIdx.x][threadIdx.y]}|;
}
如何避免上述访问模式下会发生的Bank Conflict?
有一种解决方案叫Memory Padding:在申请Shared Memory时额外增加一列,因为无论如何bank只有32个,因此相当于每个bank的空间都增加了一个,并且这种增加方式刚好是错开的,这样就能有效避免bank conflict。具体如下图所示。
代码实现如下:
int x_id = threadIdx.x + blockDim.x * blockIdx.x;
int y_id = threadIdx.y + blockDim.y * blockIdx.y;
int index = y_id * col + x_id;
__shared__ float sData[BLOCKSIZE][BLOCKSIZE|\color{OrangeRed}{\large\textbf{+1}}|];
if(x_id < col && y_id < row){
sData|\colorbox{OrangeRed!20}{[threadIdx.x][threadIdx.y]}| = matrix[index];
__syncthread();
matrixTest[index] = sData|\colorbox{OrangeRed!20}{[threadIdx.x][threadIdx.y]}|;
}
访问步长与bank conflict
我们通常这样来访问数组:每个线程根据线程编号tid与s的乘积来访问数组的32-bits字(word):
extern __shared__ float shared[];
float data = shared[baseIndex + s * tid];
如果按照上面的方式,那么当 s × n s\times n s×n是bank的数量(即32)的整数倍时或者说n是 32 / d 32/d 32/d的整数倍(d是32和s的最大公约数)时,线程tid和线程tid+n会访问相同的bank。我们不难知道如果tid与tid+n位于同一个warp时,就会发生bank冲突,相反则不会。
仔细思考你会发现,只有warp的大小(即32)小于等于 32 / d 32/d 32/d时,才不会有bank冲突,而只有当d等于1时才能满足这个条件。要想让32和s的最大公约数d为1,s必须为奇数。于是,这里有一个显而易见的结论:当访问步长s为奇数时,就不会发生bank冲突。
6.3 利用共享存储单元进行矩阵相乘
回顾之前使用global memory优化矩阵相乘运算时,每一个线程读取需要矩阵A的一行以及矩阵B的一列,假设矩阵A的大小为 m × n m\times n m×n,矩阵B的大小为 n × k n\times k n×k,则矩阵A的每一行都需要被重复读取 k k k次,而矩阵B的每一列都需要被重复读取 m m m次,而这样的重复读取过程可以使用shared memory来减少global memory的带宽需求。
把矩阵A和矩阵B全都放到shared memory当中,至此,线程在读取数据时都是从shared memory当中读取,这样读取速度会得到很大的提升。然而,shared memory是有限的,倘若矩阵A和矩阵B的占用空间超过了shared memory的存储上限,那应该怎么办?
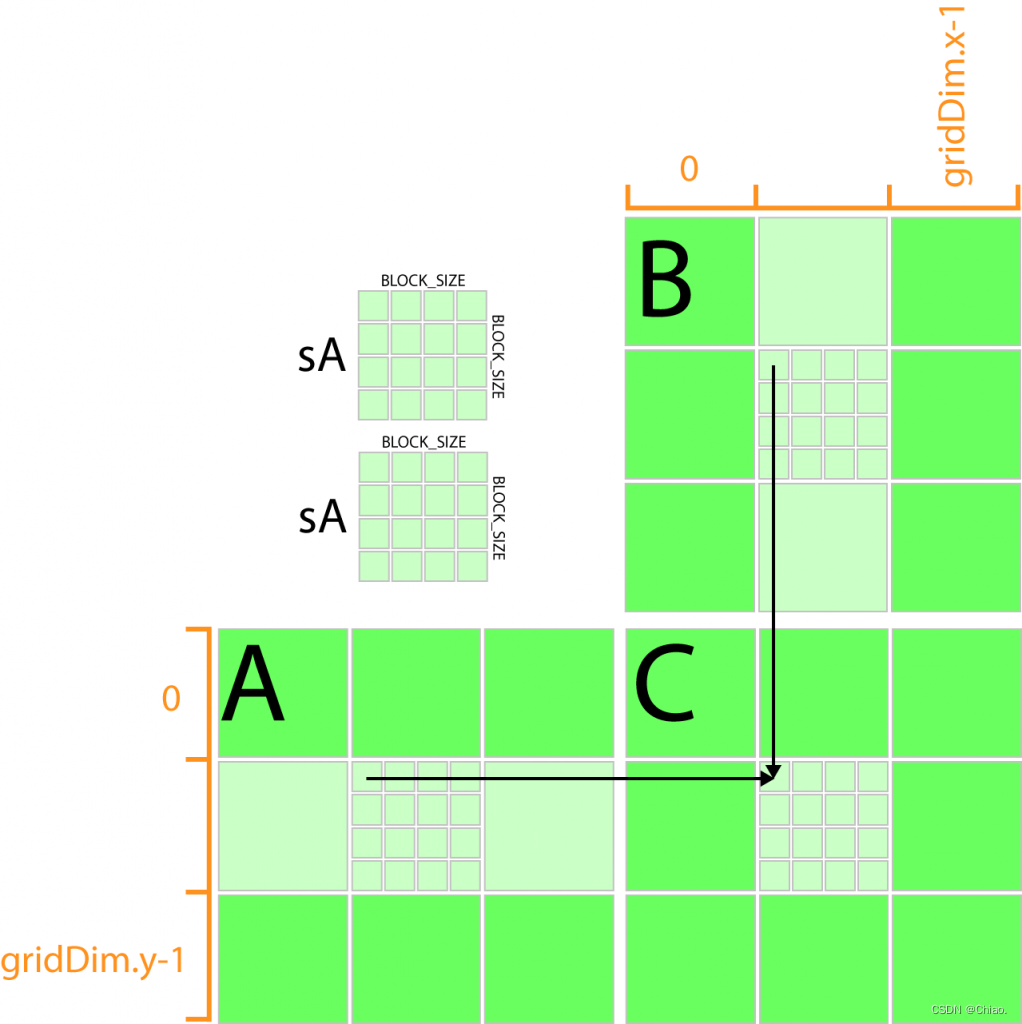
滑窗分块计算
基本思想:重复利用shared memory的空间。按照在上一篇文章Shared Memory节中提到的方法来编写Kernel函数:
- Load shared memory and
__syncthreads();
对于一个特定的滑窗,每个线程将自身在矩阵A、B上所对应元素复制到shared memory存储块的对应位置。需要执行__syncthreads()保证所有线程都完成了加载,才能执行下一步。
idx = row * n + BLOCK_SIZE * stride + threadIdx.x;
tile_a[threadIdx.y][threadIdx.x] = row < m && (BLOCK_SIZE * stride + threadIdx.x) < n ? a[idx]:0;
idx = col + (BLOCK_SIZE * stride + threadIdx.y) * k;
tile_b[threadIdx.y][threadIdx.x] = col < k && (BLOCK_SIZE * stride + threadIdx.y) < n ? b[idx]:0;
__syncthreads();
- Process shared memory and
__syncthreads();
对已经读取到的两个tile中的矩阵进行相乘,然后需要再次同步一下,等待所有线程完成操作,以便在下一步中向shared memory中写入数值时不会影响这一步的计算。
for(int i=0; i < BLOCK_SIZE; i++){
tmp += tile_a[threadIdx.y][i] * tile_b[i][threadIdx.x];
}
__syncthreads();
- Write results
完整代码贴在下面:
__global__ void gpu_matrix_mult_shared(int * a, int * b, int * c, int m, int n, int k){
int col = blockIdx.x * blockDim.x + threadIdx.x;
int row = blockIdx.y * blockDim.y + threadIdx.y;
int idx;
int tmp=0;
__shared__ int tile_a[BLOCK_SIZE][BLOCK_SIZE];
__shared__ int tile_b[BLOCK_SIZE][BLOCK_SIZE];
for(int stride=0; stride<gridDim.x; stride++){
idx = row * n + BLOCK_SIZE * stride + threadIdx.x;
tile_a[threadIdx.y][threadIdx.x] = row < m && (BLOCK_SIZE * stride + threadIdx.x) < n ? a[idx]:0;
idx = col + (BLOCK_SIZE * stride + threadIdx.y) * k;
tile_b[threadIdx.y][threadIdx.x] = col < k && (BLOCK_SIZE * stride + threadIdx.y) < n ? b[idx]:0;
__syncthreads();
for(int i=0; i < BLOCK_SIZE; i++){
tmp += tile_a[threadIdx.y][i] * tile_b[i][threadIdx.x];
}
__syncthreads();
}
if(row < m && col < k){
c[row * k + col] = tmp;
}
}














 911
911











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









