







文章目录
六、堆排序
堆是采用顺序表存储的一种近似完全二叉树的结构,堆排序是指利用堆这种数据结构所设计的一种排序算法
1、算法描述
- 将初始待排序关键字序列(R1,R2….Rn)构建成大顶堆,此堆为初始的无序区;
- 将堆顶元素R[1]与最后一个元素R[n]交换,此时得到新的无序区(R1,R2,……Rn-1)和新的有序区(Rn),且满足R[1,2…n-1]<=R[n];
- 由于交换后新的堆顶R[1]可能违反堆的性质,因此需要对当前无序区(R1,R2,……Rn-1)调整为新堆,然后再次将R[1]与无序区最后一个元素交换,得到新的无序区(R1,R2….Rn-2)和新的有序区(Rn-1,Rn)。不断重复此过程直到有序区的元素个数为n-1,则整个排序过程完成。
2、动图演示

3、代码实现
def HeapSort(lst):
def heapadjust(arr,start,end): #将以start为根节点的堆调整为大顶堆
temp=arr[start]
son=2*start+1
while son<=end:
if son<end and arr[son]<arr[son+1]: #找出左右孩子节点较大的
son+=1
if temp>=arr[son]: #判断是否为大顶堆
break
arr[start]=arr[son] #子节点上移
start=son #继续向下比较
son=2*son+1
arr[start]=temp #将原堆顶插入正确位置
n=len(lst)
if n<=1:
return lst
#建立大顶堆
root=n//2-1 #最后一个非叶节点(完全二叉树中)
while(root>=0):
heapadjust(ls,root,n-1)
root-=1
#掐掉堆顶后调整堆
i=n-1
while(i>=0):
(lst[0],lst[i])=(lst[i],lst[0]) #将大顶堆堆顶数放到最后
heapadjust(lst,0,i-1) #调整剩余数组成的堆
i-=1
return lst
li = [54,26,93,17,77,31,44,55,20]
HeapSort(li)
print(li)
七、归并排序
归并排序(MERGE-SORT)是建立在归并操作上的一种有效的排序算法,该算法是采用分治法(Divide and Conquer)的一个非常典型的应用。归并排序适用于子序列有序的数据排序。间。
1、算法描述
- 步骤1:进行序列拆分,一直拆分到只有一个元素;
- 步骤2:拆分完成后,开始递归合并。
2、动图演示
3、代码实现
def MergeSort(lst):
#合并左右子序列函数
def merge(arr,left,mid,right):
temp=[] #中间数组
i=left #左段子序列起始
j=mid+1 #右段子序列起始
while i<=mid and j<=right:
if arr[i]<=arr[j]:
temp.append(arr[i])
i+=1
else:
temp.append(arr[j])
j+=1
while i<=mid:
temp.append(arr[i])
i+=1
while j<=right:
temp.append(arr[j])
j+=1
for i in range(left,right+1): # !注意这里,不能直接arr=temp,他俩大小都不一定一样
arr[i]=temp[i-left]
#递归调用归并排序
def mSort(arr,left,right):
if left>=right:
return
mid=(left+right)//2
mSort(arr,left,mid)
mSort(arr,mid+1,right)
merge(arr,left,mid,right)
n=len(lst)
if n<=1:
return lst
mSort(lst,0,n-1)
return lst
alist = [54,26,93,17,77,31,44,55,20]
MergeSort(alist)
print(alist)
八、计数排序
计数排序不是基于比较的排序算法,其核心在于将输入的数据值转化为键存储在额外开辟的数组空间中。 作为一种线性时间复杂度的排序,计数排序要求输入的数据必须是有确定范围的整数。
1、算法描述
- 找出待排序的数组中最大和最小的元素;
- 统计数组中每个值为i的元素出现的次数,存入数组C的第i项;
- 对所有的计数累加(从C中的第一个元素开始,每一项和前一项相加);
- 反向填充目标数组:将每个元素i放在新数组的第C(i)项,每放一个元素就将C(i)减去1。
2、动图演示
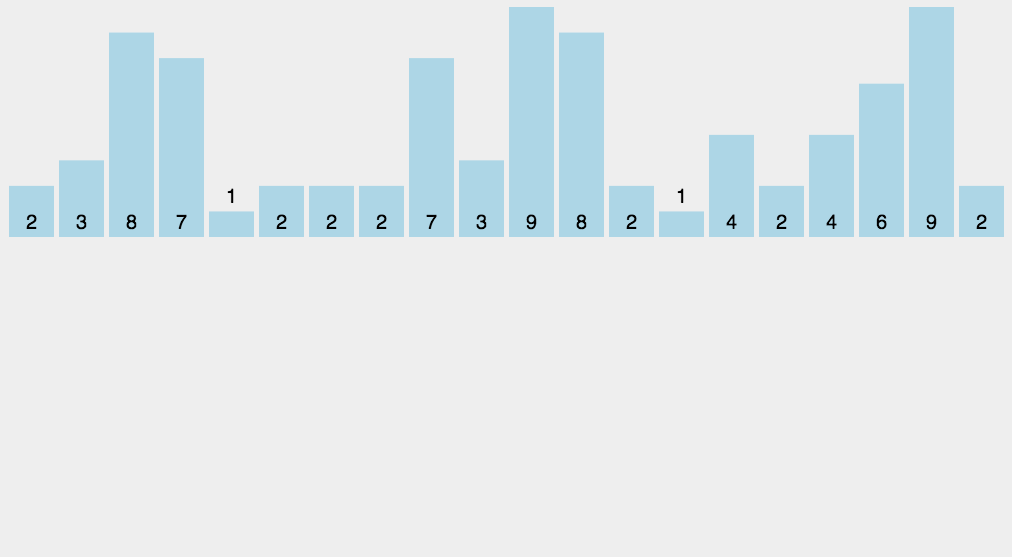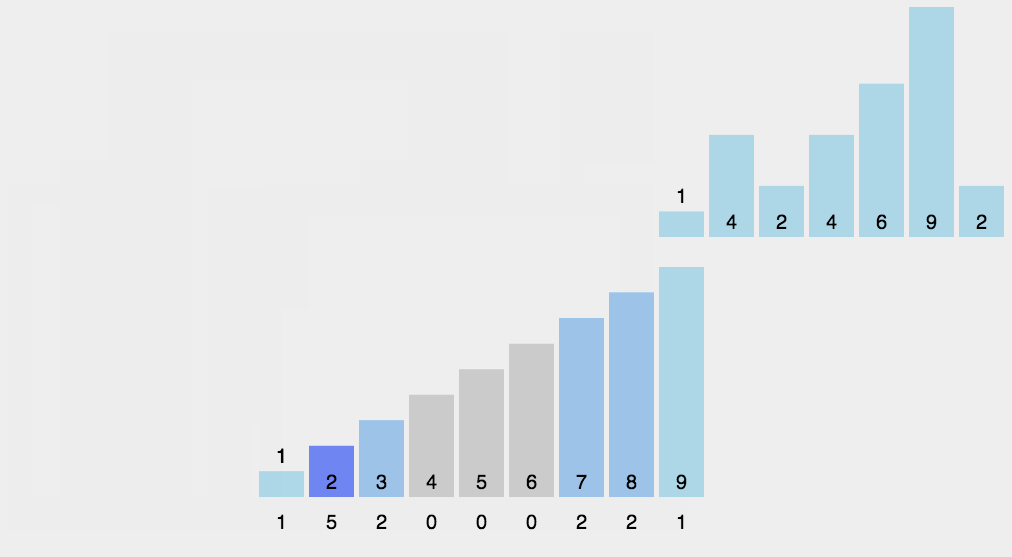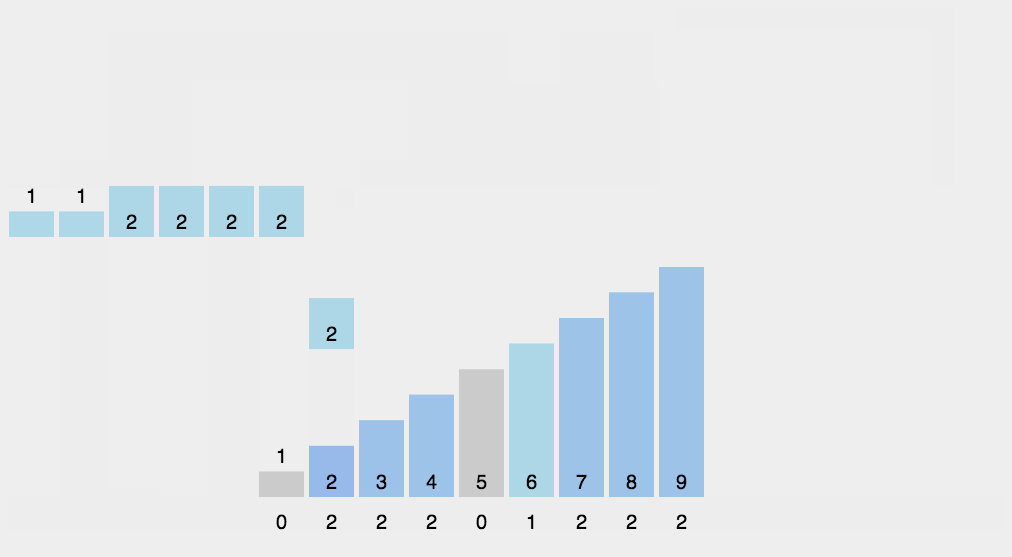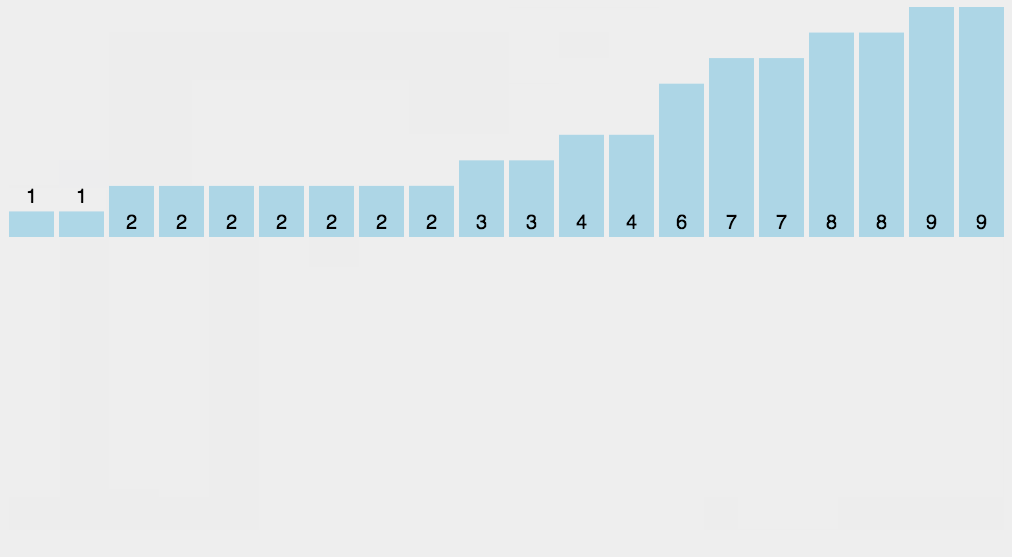
3、代码实现
def CountSort(lst):
nums_min = min(lst)
bucket = [0] * (max(lst) + 1 - nums_min)
for num in lst:
bucket[num - nums_min] += 1
i = 0
for j in range(len(bucket)):
while bucket[j] > 0:
lst[i] = j + nums_min
bucket[j] -= 1
i += 1
return lst
alist = [54,26,93,17,77,31,44,55,20]
CountSort(alist)
print(alist)
九、桶排序
桶排序是计数排序的升级版。它利用了函数的映射关系,高效与否的关键就在于这个映射函数的确定。桶排序 (Bucket sort)的工作的原理:假设输入数据服从均匀分布,将数据分到有限数量的桶里,每个桶再分别排序(有可能再使用别的排序算法或是以递归方式继续使用桶排序进行排)。
1、算法描述
- 设置一个定量的数组当作空桶;
- 遍历输入数据,并且把数据一个一个放到对应的桶里去;
- 对每个不是空的桶进行排序;
- 从不是空的桶里把排好序的数据拼接起来。
2、代码实现
def BucketSort(lst, defaultBucketSize=4):
maxVal, minVal = max(lst), min(lst)
bucketSize = defaultBucketSize
bucketCount = (maxVal - minVal) // bucketSize + 1
buckets = [[] for i in range(bucketCount)]
for num in lst:
buckets[(num - minVal) // bucketSize].append(num)
lst.clear()
for bucket in buckets:
bubble_sort(bucket)
lst.extend(bucket)
return lst
alist = [54,226,93,17,77,31,44,55,20]
BucketSort(alist)
print(alist)
十、基数排序
基数排序是按照低位先排序,然后收集;再按照高位排序,然后再收集;依次类推,直到最高位。有时候有些属性是有优先级顺序的,先按低优先级排序,再按高优先级排序。最后的次序就是高优先级高的在前,高优先级相同的低优先级高的在前。
1、算法描述
- 取得数组中的最大数,并取得位数;
- arr为原始数组,从最低位开始取每个位组成radix数组;
- 对radix进行计数排序(利用计数排序适用于小范围数的特点);
2、代码实现
def RadixSort(lst):
mod = 10
div = 1
mostBit = len(str(max(lst)))
buckets = [[] for row in range(mod)]
while mostBit:
for num in lst:
buckets[num // div % mod].append(num)
i = 0
for bucket in buckets:
while bucket:
lst[i] = bucket.pop(0)
i += 1
div *= 10
mostBit -= 1
return lst
alist = [54,226,93,17,77,31,44,55,20]
RadixSort(alist)
print(alist)
















 829
829











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











