







一些面试题
-
创建对象的四种方式
- new
- 反射机制:,调用java.lang.Class 或者 java.lang.reflect.Constructor 类的newInstance()实例方法
- clone:继承Cloneable接口,Hello h2 = h1.clone();
public class Hello implements Cloneable{ public void sayWorld(){ System.out.println("Hello world!"); } public static void main(String[] args){ Hello h1 = new Hello(); try{ Hello h2 = (Hello)h1.clone(); h2.sayWorld(); } catch (CloneNotSupportedException e){ e.printStackTrace(); } } - 序列化:调用java.io.ObjectInputStream 对象的 readObject()方法.
-
深拷贝 VS 浅拷贝
- 浅拷贝:仅仅复制引用
- 深拷贝:把要复制的对象所引用的对象复制了一边,new了一个新的对象
-
数据类型
- 基本数据类型:注意
- 0.1*3 == 0.3 :false,因为小数无法精确表示
- a = a + b;与a += b;后者会进行隐式自动类型转换(转换成左边的),而前者不会
- 类型转换
- 字符串—》基本数据类型:包装类的parseXXX()或valueOf()
- 基本数据类型–》字符串:与空串连接,String类的valueOf()
- 基本数据类型:注意
-
拆箱、装箱
- 装箱:将基本数据类型转换为包装类:Integer i = 10;
- 拆箱:将包装类对象转换为基本类型
- 注意:
在Integer的valueOf(),数值在[-128,127]时返回的已存在对象的引用,超过便会创建一个新的Integer对象
如Integer i1 = 100;
Integer i2 = 100;
Integer i3 = 200;
Integer i4 = 200;
i1==i2; true
i3==i4; false
对象作为参数时,是值传递
方法重载vs方法重写
- 方法重载:同名不同参,返回值类型不要求
- 方法重写:子类重写父类方法,返回值类型相同
-
静态嵌套类vs内部类
- 静态嵌套类:有static关键字的内部类,不依赖于外部类实例而被实例化
- 内部类:只有外部类实例化才可以实例化
-
抽象方法不可以被static修饰,不可以是本地方法(本地方法需要实现),不可以被synchronized修饰(synchronized和方法细节有关,但抽象方法无实现)
-
静态方法不可以在内部调用非静态方法,只能方法静态成员。非静态方法需要被实例化才可以方法
-
对象克隆(浅拷贝)
- 实现Cloneable接口并重写clone()
- 实现Serializable接口,实现对象的序列化和反序列化
-
GC:垃圾回收机制
- 调用:System.gc();或Runtime.getRuntime().gc();
-
锁池和等待池
线程调用对象的wait()后,该线程进入等待池,当该线程调用对象的notifyAll()后,该线程进入锁池,当该线程抢到锁时,该线程处于就绪状态- 等待池:等待进入锁池的池子。wait()后进入
- 锁池:竞争对象锁的池子,抢到对象锁的线程进入就绪状态。notify()后进入
一、日期类
1.1 常见日期类
Date类
- 包:util.Date
- 构造器:
- Date():创建一个Date对象,代表的是系统当前此刻日期时间。
- Date(long date):将时间毫秒值转换为Date日期对象
- 时间的两种表示方法
- yyyy-mm-dd:Date d = new Date();
- 时间毫秒值:long time = d.getTime();或long time = System.currentTimeMillis()
- 转换:
- 常用方法:
| 名称 | 说明 |
|---|---|
| Date() | 创建一个Date对象,代表的是系统当前此刻日期时间。 |
| public long getTime() | 返回从1970年1月1日 00:00:00走到此刻的总的毫秒数 |
| public void setTime(long time) | 设置日期对象的时间为当前时间毫秒值对应的时间 |
| before(Date date) | d1在d2之前,则:d1.after(d2)为true |
| after(Date date) |
- 案例:请计算出当前时间往后走1小时121秒之后的时间是多少。
//当前时间 Date d1 = new Date(); System.out.println(d1); //当前时间的毫秒值 long time = d1.getTime();//或者long time = System.currentTimeMillis(); //1小时121秒后 time += (60*60 + 121) * 1000; Date d2 = new Date(time); System.out.println(d2);
SimpleDateFormat
- 格式化日期和时间毫秒值
public class data { public static void main(String[] args) { //1、格式化日期对象 //1.1、获取日期对象 Date d = new Date(); System.out.println(d); //1.2、格式化 SimpleDateFormat sdf = new SimpleDateFormat("yyyy年MM月dd日 HH:mm:ss EEE a"); String rs = sdf.format(d); System.out.println(rs); //2、格式化时间毫秒值 long l = System.currentTimeMillis(); String rs2 = sdf.format(l); System.out.println(rs2); } } - 解析字符串时间为日期对象
public static void main(String[] args) throws ParseException { //时间:2021年08月06日 11:11:11 String dateStr = "2021年08月06日 11:11:11"; //形式必须与被解析字符串时间完全一样 SimpleDateFormat sdf = new SimpleDateFormat("yyyy年MM月dd日 HH:mm:ss"); Date date = sdf.parse(dateStr); long time = date.getTime() + (2L*24*60*60 + 14*60*60 + 49*60 + 6) * 1000; System.out.println(sdf.format(time)); }
Calendar
- 概述
- Calendar代表了系统此刻日期对应的日历对象。
Calendar是一个抽象类,不能直接创建对象。
calendar是可变日期对象,一旦修改后其对象本身表示的时间将产生变化。
- Calendar代表了系统此刻日期对应的日历对象。
- 案例
public static void main(String[] args) { // 1、拿到系统此刻日历对象 Calendar cal = Calendar.getInstance(); System.out.println(cal); // 2、获取日历的信息:public int get(int field):取日期中的某个字段信息。 int year = cal.get(Calendar.YEAR); System.out.println(year); int mm = cal.get(Calendar.MONTH) + 1; System.out.println(mm); int days = cal.get(Calendar.DAY_OF_YEAR) ; System.out.println(days); // 3、public void set(int field,int value):修改日历的某个字段信息。不适合修改 // cal.set(Calendar.HOUR , 12); // System.out.println(cal); // 4.public void add(int field,int amount):为某个字段增加/减少指定的值 // 请问64天后是什么时间 cal.add(Calendar.DAY_OF_YEAR , 64); //59分后是什么时间 cal.add(Calendar.MINUTE , 59); // 5.public final Date getTime(): 拿到此刻日期对象。 Date d = cal.getTime(); System.out.println(d); // 6.public long getTimeInMillis(): 拿到此刻时间毫秒值 long time = cal.getTimeInMillis(); System.out.println(time); }
1.2 JDK8新增日期类
- 所在包:java.time包
- 类:(新API的类型几乎全部是不变类型(和String的使用类似))
LocalDate:年月日
LocalTime:时分秒
LocalDateTime:包含了日期及时间。
Instant:代表的是时间戳。
DateTimeFormatter 用于做时间的格式化和解析的
Duration:用于计算两个“时间”间隔
Period:用于计算两个“日期”间隔
LocalDate、LocalTime、LocalDateTime
- 概述
- 分别表示日期,时间,日期时间对象,他们的类的实例是不可变的对象
- 构建对象

- api
时间信息api
LocalDateTime的转换API

修改api(这些方法返回的是一个新的实例引用,因为LocalDateTime 、LocalDate 、LocalTime 都是不可变的)

Instant时间戳
- 概述
- 时间戳:包含日期和时间,与java.util.Date很类似,事实上Instant就是类似JDK8 以前的Date。
- 构造:Instant类由一个静态的工厂方法now()可以返回当前时间戳。

DateTimeFormatter
Duration/Period
ChronoUnit
二、包装类
- 包装类:就是8种基本数据类型对应的引用类型

- 作用:
基本数据类型对应的引用类型,实现了一切皆对象。
后期集合和泛型不支持基本类型,只能使用包装类 - 功能:
1、自动装箱:基本类型的数据和变量可以直接赋值给包装类型的变量。
2、自动拆箱:包装类型的变量可以直接赋值给基本数据类型的变量
3、包装类的变量的默认值可以是null,容错率更高:Integer i = null
4、可以把基本类型的数据转换成字符串类型(用处不大,可以使用+空字符串""转换成字符串)
5、可以把字符串类型的数值转换成真实的数据类型(⭐⭐)

2.1 泛型
- 概述
- 含义:是JDK5中引入的特性,可以在编译阶段约束操作的数据类型,并进行检查
- 格式:<数据类型>; 注意:泛型只能支持引用数据类型。
- 位置:
类后面:泛型类
方法声明后:泛型方法
接口后面:泛型接口
- 好处:
统一数据类型。
将运行时的问题提前到了编译时,避免了强转可能出现的异常 - 泛型类:
格式:public class MyArrayList<T> {}
核心思想:把出现该泛型变量的地方替换成指定真实数据类型变量
作用:指定数据类型,类似集合作用 - 泛型方法
格式:public <T> void show(T t) { };
核心思想:
作用:方法中可以接收一切实际类型的参数,方法更具备通用性 - 泛型接口
格式:public interface Data<E>{};
作用:泛型接口可以让实现类选择当前功能需要操作的数据类型 - 泛型通配符
- ?:代表一切类型
- 泛型上限:
? extends Car: ?必须是Car或者其子类 - 泛型下限:
? super Car : ?必须是Car或者其父类
2.2 正则表达式
正则表达式:用一些规定的字符来制定规则,并用来校验数据格式的合法性。
- 规则:
- 字符类
[abc] 只能是a, b, 或c
[^abc] 除了a, b, c之外的任何字符
[a-zA-Z] a到z A到Z,包括(范围)
[a-d[m-p]] a到d,或m通过p:([a-dm-p]联合)
[a-z&&[def]] d, e, 或f(交集)
[a-z&&[^bc]] a到z,除了b和c:([ad-z]减法)
[a-z&&[^m-p]] a到z,除了m到p:([a-lq-z]减法) - 预定义字符类
. 任何字符
\d 一个数字: [0-9]
\D 非数字: [^0-9]
\s 一个空白字符: [ \t\n\x0B\f\r]
\S 非空白字符: [^\s]
\w [a-zA-Z_0-9] 英文、数字、下划线
\W [^\w] 一个非单词字符 - 贪婪的量词(配合匹配多个字符)
X? ,X 出现一次或根本不
X* ,X出现零次或多次
X+ ,X出现 一次或多次
X {n} ,X出现正好n次
X {n, } ,X出现至少n次
X {n,m}, X出现至少n但不超过m次
- 字符类
- 案例:
- 校验手机号码:phone.matches(“1[3-9]\d{9}”)
第一位只能为1、第二位可以在3-9,后面随便 - 校验邮箱:email.matches(“\w{1,30}@[a-zA-Z0-9]{2,20}(\.[a-zA-Z0-9]{2,20}){1,2}”)
\w{1,30}:1-30个字符,如1787050201
[a-zA-Z0-9]{2,20}:域名,如qq
\.:表示"."
(\.[a-zA-Z0-9]{2,20}){1,2}:会出现两级,如com.cn - 校验电话号码:tel.matches(“0\d{2,6}-?\d{5,20}”)
- 校验金额
- 校验手机号码:phone.matches(“1[3-9]\d{9}”)
- 正则表达式在字符串方法的使用
- split()和replace()
public static void main(String[] args) { String names = "小路dhdfhdf342蓉儿43fdffdfbjdfaf小何"; //split String[] arrs = names.split("\\w+"); for (int i = 0; i < arrs.length; i++) { System.out.println(arrs[i]); } //replace String names2 = names.replaceAll("\\w+", " "); System.out.println(names2); }
- split()和replace()
- 爬取信息

2.3 Lambda表达式
-
作用:简化函数式接口的匿名内部类的代码写法。
函数式接口:只有一个抽象方法的接口(可为接口添加@FunctionalInterface) -
格式

-
案例:
- 案例1:

- 案例2:


- 案例1:
-
省略写法
1、参数类型可以省略不写。
2、如果只有一个参数,参数类型可以省略,同时()也可以省略。
3、如果Lambda表达式的方法体代码只有一行代码。可以省略大括号不写,同时要省略分号!
4、如果Lambda表达式的方法体代码只有一行代码。可以省略大括号不写。此时,如果这行代码是return语句,必须省略return不写,同时也必须省略";"不写
Arrays.sort(ages1, ( o1, o2) -> o2 - o1);//降序
2.4 Arrays类
数组
- 定义:String[] arr = {“hello”, “array”};
- 静态初始化数组
- 格式:数据类型[] 数组名 = new 数据类型[]{元素1, 元素2, 元素3};

- 注意:
数据类型[] 数组名 ,也可以写成:数据类型 数组名[]
数组一经创建,长度类型就固定
- 格式:数据类型[] 数组名 = new 数据类型[]{元素1, 元素2, 元素3};
- 动态初始化创建数组
- 格式:数据类型[] 数组名 = new 数据类型[长度];
- 静态初始化数组
数组工具类Arrays
- 数组操作工具类,专门用于操作数组元素的
- 常用api

案例:public static void main(String[] args) { // 目标:学会使用Arrays类的常用API ,并理解其原理 int[] arr = {10, 2, 55, 23, 24, 100}; System.out.println(arr); // 1、返回数组内容的 toString(数组) // String rs = Arrays.toString(arr); // System.out.println(rs); System.out.println(Arrays.toString(arr)); // 2、排序的API(默认自动对数组元素进行升序排序) Arrays.sort(arr); System.out.println(Arrays.toString(arr)); // 3、二分搜索技术(前提数组必须排好序才支持,否则出bug) int index = Arrays.binarySearch(arr, 55); System.out.println(index); // 返回不存在元素的规律: - (应该插入的位置索引 + 1) int index2 = Arrays.binarySearch(arr, 22); System.out.println(index2); // 注意:数组如果么有排好序,可能会找不到存在的元素,从而出现bug!! int[] arr2 = {12, 36, 34, 25 , 13, 24, 234, 100}; System.out.println(Arrays.binarySearch(arr2 , 36)); }- Comparator比较器
自定义排序规则
- Comparator比较器
2.5 字符串类
不可变字符串String
-
String:String类定义的变量可以用于存储字符串,被称为不可变字符串类型,它的对象在创建后不能被更改。
-
特点:
- 为final类,不可被继承
-
原理:
String变量每次的修改其实都是产生并指向了新的字符串对象。
原来的字符串对象都是没有改变的,所以称不可变字符串。 -
对象的创建
- 法一:String name = “传智教育”;(存在字符串常量池中,相同值只有一份)
- 法二:String name = new (“船只教育”)构造器创建
name:在栈中
对象1:new出来的对象在堆上
对象2:船只教育:字符串在方法区的常量池


-
API

- 字符串内容比较equals
- length:
数组有length属性,没有length方法
String没有length属性,有length方法
可变字符串(StringBuffer、StringBuilder)
- 区别:StringBuilder单线程,方法没有被synchronized修饰,效率高
- 使用:StringBuffer、StringBuilder的reverse方法
三、 集合

- 集合vs数组:
数组:长度固定,类型固定。可以存储基本类型和引用类型
集合:长度不固定,类型不固定,只能存储引用类型 - ArrayList和Vector、LinkedList
- ArrayList:基于数组,不安全,但是可以通过工具类Cellections的synchronizedList方法将其线程安全化
- Vector:基于数组,线程安全(sychronized),性能查
- LinkedList:基于链表,不安全,可线程安全化
- HashMap和HashTable区别
HashMap:线程不安全
HashTable:线程安全,加了synchronized锁
ConcurrentHashMap:线程安全,使用了分段锁,不对整个数据进行锁定
3.1 Collection(单列)
1. collection概述
- 存储内容:元素对象的地址
- 特点:长度可变,类型可变
- 实现:不直接实现,使用子接口实现:
Collection<String> c = new ArrayList<String>(); - API:

- 遍历:
- 迭代器iterator
-
适用范围:collection专业遍历方式
-
api:

-
使用步骤
//Iterator<E> iterator():返回此集合中元素的迭代器,通过集合的iterator()方法得到 Iterator<String> it = c.iterator(); //用while循环改进元素的判断和获取 while (it.hasNext()) { String s = it.next(); System.out.println(s); } -
foreach/增强for循环
- 适用范围:集合和数组
- 特点:不会影响集合中的元素
- 使用

-
lambda表达式


-
- 迭代器iterator
2. List接口
-
介绍
- list:序列(有序集合)
- 特点:有序 可重复 有索引
-
特有api
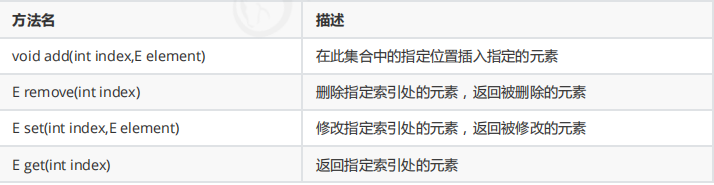
-
底层:ArrayList是数组,LinkList是双向链表
-
遍历方式:a、迭代器 b、foreach c、lambda d、for循环(因为list有索引)
ArrayList实现类
底层:数组 超过大小会扩容
特点:查询快、增删慢
特有API
LinkedList实现类
底层:双向链表
特点:查询慢、增删快
特有api:

3. Set接口
- 特点:无序(存取顺序无序) 不重复 无索引
- 遍历方式:迭代器、增强for循环
- 基本使用:
Set<String> set = new HashSet<String>(); - Set实现类:
HashSet : 无序、不重复、无索引。
LinkedHashSet:有序、不重复、无索引。
TreeSet:排序、不重复、无索引。
哈希表
- 底层:哈希表(数组+链表)
- 哈希值: 根据对象的地址以某种算法得到的数值
特点:同一对象的哈希值是相同的;默认情况下,不同对象的哈希值是不同的。 - 哈希表:
JDK8之前的,哈希表:底层使用数组+链表组成
JDK8开始后,哈希表:底层采用数组+链表+红黑树组成。
- 哈希值: 根据对象的地址以某种算法得到的数值
- 哈希表的创建流程
a、创建一个默认长度16的数组名为table
b、 根据哈希算法hashCode(元素哈希值与数组长度求余)得到位置
c、判断当前位置是否为null,如果是null直接存入,如果位置不为null,表示有元素, 则调用equals方法比较属性值,如果一样,则不存,如果不一样,则存入数组,即挂在老元素下面。
d、当数组存满到16*0.75=12时,就自动扩容,每次扩容原先的两倍
e、注意:jdk1.8后,当数组的链表长度超过8后,会自动转换成红黑树(优化) - 哈希表的去重:
- 默认去重:先判断地址的哈希值,再判断内容的equals方法
- 要想实现Set集合去除重复内容的Student对象,就必须重写Student类的hashCode()和equals方法(可以自动重写)
HashSet
- HashSet
3. 案例//可以去重完全相同的Student对象 public class StudentDemo { public static void main(String[] args) { Set<Student> students = new HashSet<>(); Student student1 = new Student("小米", 20, "女"); Student student2 = new Student("小米", 20, "女"); Student student3 = new Student("小麦", 20, "女"); students.add(student1); students.add(student2); students.add(student3); System.out.println(students); } } public class Student { private String name; private int age; private String sex; @Override public String toString() { return "Student{" + "name='" + name + '\'' + ", age=" + age + ", sex='" + sex + '\'' + '}'; } //重写方法 @Override public boolean equals(Object o) { if (this == o) return true; if (o == null || getClass() != o.getClass()) return false; Student student = (Student) o; return age == student.age && Objects.equals(name, student.name) && Objects.equals(sex, student.sex); } //重写方法 @Override public int hashCode() { return Objects.hash(name, age, sex); } }
LinkedHashSet:有序
特点:有序(存储和取出顺序一致)、不重复、无索引
底层:哈希表加双向链表。底层是哈希表,每个元素额外多了双向链表记录添加顺序
TreeSet实现类:有序
- 特点:不重复、有序(默认升序)、无索引
重写hashCode和equals后相同的Student对象还会重复 - 底层:红黑树的数据结构
- 默认排序规则(默认升序):
对于数值类型:Integer , Double,官方默认按照大小进行升序排序。
对于字符串类型:默认按照首字符的编号升序排序。
对于自定义类型如Student对象,需要制定排序规则,否则程序出错 - 自定义排序规则
- 方式一
让自定义的类(如学生类)实现Comparable接口重写里面的compareTo方法来定制比较规则。 - 方式二(两种方式,方式二优先级大一点)
TreeSet集合有参数构造器,可以设置Comparator接口对应的比较器对象,来定制比较规则 - 比较规则:
a、如果TreeSet集合存储的对象有实现比较规则,集合也自带比较器,默认使用集合自带的比较器排序
b、如果认为第一个元素等于第二个元素返回0即可,此时Treeset集合只会保留一个元素,认为两者重复;
- 方式一
- 自定义比较规则案例(根据Student类的age排序,也可设置其他类型)
- 实现比较器接口,重写比较方法
public class StudentDemo { public static void main(String[] args) { TreeSet<Student> students = new TreeSet<>(); Student student1 = new Student("小米", 23, "女"); Student student2 = new Student("小米", 21, "女"); Student student3 = new Student("小麦", 23, "女"); students.add(student1); students.add(student2); students.add(student3); System.out.println(students); } } class Student implements Comparable<Student>{ private String name; private int age; private String sex; @Override public String toString() { return "Student{" + "name='" + name + '\'' + ", age=" + age + ", sex='" + sex + '\'' + '}'; } public Student(String name, int age, String sex) { this.name = name; this.age = age; this.sex = sex; } //自定义比较规则 @Override public int compareTo(Student o) { //按照年龄比较 //return this.age - o.age;//去重年龄一样的 return this.age - o.age >= 0?1:-1;//保留年龄一样的 } } - 方式二,集合自带比较器规则
public class StudentDemo { public static void main(String[] args) { Student student1 = new Student("小米", 23, "女"); Student student2 = new Student("小米", 23, "女"); Student student3 = new Student("小麦", 13, "女"); //简写:Set<Student> students2 = new TreeSet<>((o1, o2) -> o2.getAge() - o1.getAge()); Set<Student> students2 = new TreeSet<>(new Comparator<Student>() { @Override public int compare(Student o1, Student o2) { //return o1.getAge() - o2.getAge();//升序 return o2.getAge() - o1.getAge();//降序 } }); students2.add(student1); students2.add(student2); students2.add(student3); System.out.println(students2); } }
- 实现比较器接口,重写比较方法

4. Collections集合工具类
- 可变参数
- 含义:形参可接收多个数据
- 格式:数据类型…参数名称,如:int…nums
- 作用:传参灵活,可多可无也可数组
- 条件:a、一个形参列表中,只能有一个可变形参;b、且位置在形参列表最后
- 实例:
public static void main(String[] args) { int[] arr = {4,5,6,7}; sum(); sum(1); sum(2,3); sum(arr); } public static void sum(int...nums) { //nums在方法内部为数组 System.out.println(Arrays.toString(nums)); }
- 包:java.utils.Collections,集合工具类
重构键:shift+f6 - 作用:Collections并不属于集合,是用来操作集合的工具类。
- api:
方法 说明 public static boolean addAll(Collection<? super T> c, T… elements) 给集合对象批量添加元素 public static void shuffle(List<?> list) 打乱List集合元素的顺序 public static void sort(List list) 将集合中元素按照默认规则排序(不可以直接对自定义类型的List集合排序,除非自定义类型实现了比较规则Comparable接口) public static void sort(List list,Comparator<? super T> c) 将集合中元素按照指定规则排序 - sort()排序:
使用默认排序规则。自定义类型需要继承Comparable接口,没有则需要添加Comparator比较器 - 线程安全化:
- sort()排序:
- 案例:
public static void main(String[] args) { List<String> people = new ArrayList<>(); //1、addAll() Collections.addAll(people,"小红", "小黄", "校长"); System.out.println("addAll------>" + people); //2、shuffer Collections.shuffle(people); System.out.println("shuffer----->" + people); //3、sort(自定义类型需要继承Comparable接口重写比较方法,否则报错) Collections.sort(people); System.out.println("sort----->" + people); List<Student> students = new ArrayList<>(); Student student1 = new Student("abc", 20, "女"); Student student2 = new Student("abc", 10, "女"); Student student3 = new Student("abc", 100, "女"); Collections.addAll(students, student1, student2, student3); //4、sort方式2 Collections.sort(students, new Comparator<Student>() { @Override public int compare(Student o1, Student o2) { return o1.getAge() - o2.getAge(); } }); System.out.println("students---sort2-->" + students); }
5. 并发修改异常问题
迭代器:遍历集合但是用迭代器自己的删除方法操作可以解决
for循环遍历:有索引、当删除值后,将索引减1即可恢复
3.2 map(键值对)
1. 概述
-
Map :双列集合,每个元素包含两个数据,key=value形式
-
底层:哈希表
-
完整格式:{key1=value1 , key2=value2 , key3=value3 , …}
collection集合:[元素1, 元素2, 元素3…] -
特点
由键决定的
无序,不重复的,无索引的,值不做要求(可以重复)
重复的键对应的值会覆盖前面重复键的值。
键值对都可以为null -
实现类
a、HashMap:元素按照键是无序,不重复,无索引,值不做要求。(与Map体系一致)
b、LinkedHashMap:元素按照键是有序,不重复,无索引,值不做要求。
c、TreeMap:元素按照建是排序,不重复,无索引的,值不做要求。 -
声明:
Map<String, Integer> maps = new HashMap<>(); -
Map接口的api

案例:public static void main(String[] args) { //1、声明 HashMap<String, Integer> map = new HashMap<>(); //2、添加数据 map.put("小红", 10); map.put("小米", 18); map.put("小方", 38); map.put("小狗", 1); //3、清空 //map.clear(); //4、判空 System.out.println("map为空:" + map.isEmpty()); //5、 根据key删除元素,返回值为key对应的value System.out.println("小狗的年龄" + map.remove("小狗")); //6、判断是否含有key System.out.println("是否含有‘小米’:" + map.containsKey("小米")); //7、判断是否含有value System.out.println("是否含有18岁的:" + map.containsValue(18)); //8、根据key获取对应的value System.out.println("小方的年龄" + map.get("小方")); //8、获取全部的key集合:返回值是set是因为key无序不重复无索引 Set<String> keys = map.keySet(); System.out.println("所有的key:" + keys); //9.获取全部的value集合:返回值是collection是因为collection可重复 Collection<Integer> values = map.values(); System.out.println("所有的value:" + values); //10、获取map的大小 System.out.println("map的大小为:" + map.size()); //11、合并其他的map,map1.putAll(map2):将map2拷贝到map1中 System.out.println(map); } -
遍历方式
方式一:键找值的方式遍历:先获取Map集合全部的键,再根据遍历键找值。
方式二:键值对的方式遍历,把“键值对“看成一个整体,难度较大。
方式三:JDK 1.8开始之后的新技术:Lambda表达式。
2. 遍历方式
键找值
- 步骤:键找值的方式遍历:先获取Map集合全部的键,再根据遍历键找值。
- 代码
HashMap<String, Integer> map = new HashMap<>(); map.put("小红", 10); map.put("小米", 18); map.put("小方", 38); map.put("小狗", 1); //1、获取全部的key Set<String> keys = map.keySet(); //2、根据key,依次获取value for (String key:keys) { System.out.println(map.get(key)); }
键值对
- 步骤:把“键值对“看成一个整体。a、先把Map集合转换成Set集合,Set集合中每个元素都是键值对实体类型了。b、遍历Set集合,然后提取键以及提取值。
- 代码
public static void main(String[] args) { HashMap<String, Integer> map = new HashMap<>(); map.put("小红", 10); map.put("小米", 18); map.put("小方", 38); map.put("小狗", 1); //1、将map集合转换为set集合 Set<Map.Entry<String, Integer>> entries = map.entrySet(); //2、根据key,依次获取value for (Map.Entry<String, Integer> entry:entries) { System.out.println("key:" + entry.getKey()); System.out.println("value:" + entry.getValue()); System.out.println("key=value:" + entry); } }
lambda
- 代码:
map.forEach(new BiConsumer<String, Integer>() { @Override public void accept(String s, Integer integer) { System.out.println(s + "=" + integer); } }); //简写:map.forEach((s, integer) -> System.out.println(s + "=" + integer));
3. 实现类
HashMap⭐
特点:无序、不重复(依赖hashCode和equals)、无所引
底层:哈希表
存储:当key是自定义对象时需要重写hashCode和equals
linkedHashMap
特点:有序(双链表)、不重复、无索引
底层:哈希表,增加了双链表记录顺序
HashTable
特点:有序
TreeMap
原理:和TreeSet一样
特点:有序、不重复、无所引
底层:哈希表+红黑树(它是treeSet的底层)
要求:必须为key实现排序方法,可以默认排序,也可以自定义排序
排序规则:1、类实现Comparable接口,2、TreeMap集合有参数构造器,可以new一个Comparator接口对应的比较器对象,来定制比较规则
4. 嵌套综合案例

代码
public static void main(String[] args) {
//1 利用map集合记录学生选择情况(姓名:选择)
Map<String, List<String>> maps = new HashMap<>();
List<String> selects1 = new ArrayList<>();
Collections.addAll( selects1, "B","A");
maps.put("小红", selects1);
List<String> selects2 = new ArrayList<>();
Collections.addAll( selects2, "C","A");
maps.put("小黑", selects2);
List<String> selects3 = new ArrayList<>();
Collections.addAll( selects3, "D","A","B");
maps.put("小白", selects3);
//2 利用map集合记录不同地点被选择的次数
Map<String, Integer> counts = new HashMap<>();
//3 插入数据
//3.1 提取所有的value,values = [[B,A], [C, A],[D,A,B]]
Collection<List<String>> values = maps.values();
//3.2 遍历values,为counts添加数据
for (List<String> value : values) {
//value = [B,A]
for (String s : value) {
//counts中是否有s,有则存入s=get(s)+1,没有则存s=1
if (counts.containsKey(s))
counts.put(s,counts.get(s)+1);
else
counts.put(s,1);
}
}
System.out.println(counts);
}
四、多线程
线程安全:vector、stack、hashtable
4.1 线程Thread
1 概述
- 线程(thread):一个程序内部的一条执行路径
包:java.lang.Thread 类
name属性:默认为线程1、线程2… - 分类
1. 单线程程序:单独的执行路径,如main()
2. 多线程:从软硬件上实现多条执行流程的技术,如消息通信、淘宝 - 构造器
public Thread(String name) 可以为当前线程指定名称 public Thread(Runnable target) 把Runnable对象交给线程对象 public Thread(Runnable target ,String name ) 把Runnable对象交给线程对象,并指定线程名 - 使用:
Thread t1 = new MyThread("线程1"); // Runnable target = new MyRunnable(); Thread t2 = new MyThread(target, "线程1");
2. 线程Thread的API
| 方法 | 作用 |
|---|---|
| run | 线程任务方法 |
| start | 启动线程方法 |
| getName | 获取线程名 |
| setName | 设置线程名 |
| currentThread | 获取当前线程对象 |
- run VS start
线程启动时,不可以直接调用run(),因为这是普通调用。start才是真正启动线程的方法 - setName/getName
-
方法一:t.setName();
Thread t1 = new MyThread(); //设置线程名 t1.setName("线程1"); t1.start(); //获取当前线程名 prtintf(Thread.currentThread().getName()): -
方法二:构造器设置
//为MyThread添加一个含参构造器 //声明并复制 Thread t2 = new MyThread("线程2");
-
- currentThread
哪个线程执行中调用的,就会得到哪个线程对象。
3. 线程创建
方法一:直接使用线程类继承Thread类
-
步骤:
1、定义一个子类MyThread继承线程类java.lang.Thread,重写run()方法
2、创建MyThread类的对象
3、调用线程对象的start()方法启动线程(启动后还是执行run方法的) -
优缺
优点:简单
缺点:线程类已经继承Thread,无法继承其他类,不利于扩展。 -
注意
- 为什么不直接调用run,而是start启动线程?
因为直接调用run方法会当成普通方法执行,此时相当于还是单线程执行。只有调用start方法才是启动一个新的线程执行 - 把主线程任务放在子线程之前
这样主线程一直是先跑完的,相当于是一个单线程的效果了 - 把主线程任务放在子线程之后
start后,t线程和主线程同时启动。主子线程随机顺序执行
- 为什么不直接调用run,而是start启动线程?
-
实现:
public class ThreadPoolDemo1 { public static void main(String[] args) throws ExecutionException, InterruptedException { //3、获取Thread对象 Thread t = new MyThread(); //4、启动线程 t.start(); //主线程 for (int i = 0; i < 5; i++) { System.out.println("主线程执行:" + i); } } } //1、定义线程类 class MyThread extends Thread{ //2、重写run方法,run方法为该线程要干什么事 @Override public void run(){ for (int i = 0; i < 5; i++) { System.out.println("子线程执行:" + i); } } }
方式二:使用任务类实现Runnable接口
-
步骤
1、定义一个任务类MyRunnable实现Runnable接口,重写run()方法
2、创建MyRunnable任务对象
3、创建Thread线程对象,将MyRunnable任务对象交给Thread处理。
4、调用线程对象的start()方法启动线程 -
优缺:
优点:线程任务类只是实现接口,可以继续继承类和实现接口,扩展性强。
缺点:编程多一层对象包装,如果线程有执行结果是不可以直接返回的。 -
实现
public class Demo1 { public static void main(String[] args) throws ExecutionException, InterruptedException { //3、获取任务对象 Runnable target = new MyRunnable(); //4、将任务对象交给线程 Thread t = new Thread(target); //5、启动线程 t.start(); //主线程 for (int i = 0; i < 10; i++) { System.out.println("主线程执行:" + i); } } } //1、定义一个线程任务类,实现Runnable接口 class MyRunnable implements Runnable{ //2、重写run方法,即所执行任务 @Override public void run() { for (int i = 0;i < 10; i++){ //Thread.currentThread().getName():获取当前线程的名字,默认为数字 System.out.println(Thread.currentThread().getName() + "输出了" + i); } } } -
简化
可以创建Runnable的匿名内部类对象。
交给Thread处理。
调用线程对象的start()启动线程。//简化1: Thread t = new Thread(new Runnable() { @Override public void run() { for (int i = 0; i < 100; i++) { System.out.println("儿子线程执行:" + i); } } }); t.start(); //简化2 new Thread(new Runnable() { @Override public void run() { for (int i = 0; i < 100; i++) { System.out.println("儿子线程执行:" + i); } } }).start(); //简化3 new Thread(() -> { for (int i = 0; i < 100; i++) { System.out.println("儿子线程执行:" + i); } }).start();
方式三:任务类实现Callable接口(jdk5)
- 前两种弊端
run()无法直接返回结果,只适合不需要返回结果的业务场景 - 优点:可以得到线程执行的结果,扩展性强
- 步骤
- 得到任务对象
- 定义Callable任务类
实现Callable接口(添加返回值的泛型)、重写call方法(call方法即以前没有返回值的run(),区别是call有返回值) - 用FutureTask把Callable对象封装成线程任务对象。
FutureTask<String> f1 = new FutureTask<>(call);
FutureTask的get()可得到任务(线程)返回结果
- 定义Callable任务类
- 把线程任务对象交给Thread处理。
- 调用Thread的start方法启动线程,执行任务
- 线程执行完毕后、通过FutureTask的get方法去获取任务执行的结果。
- 得到任务对象
- 实现
public class ThreadPoolDemo1 { public static void main(String[] args) throws ExecutionException, InterruptedException { //1、获取Callable对象 Callable call = new MyCallable(10); //2、将Callable任务交给线程Thread //2.1、先将Callable任务交给FutureTask(底层是Runnable),FutureTask的get()可得到任务结果 FutureTask<String> f1 = new FutureTask<>(call); //2.2、将FutureTask交给线程Thread Thread thread = new Thread(f1); //3、启动线程 thread.start(); Callable call2 = new MyCallable(20); FutureTask<String> f2 = new FutureTask<>(call2); Thread thread2 = new Thread(f2); thread2.start(); //4、获得线程结果 try{ //如果f1没有执行完毕,这里的代码会等待,直到线程1跑完才执行f1.get() System.out.println(f1.get()); }catch (Exception e){ } try{ //如果f1没有执行完毕,这里的代码会等待,直到线程2跑完才执行f2.get() System.out.println(f2.get()); }catch (Exception e){ } //主线程 for (int i = 0; i < 10; i++) { System.out.println("主线程执行:" + i); } } } //定义一个Callable任务类,实现接口,声明任务执行完毕后返回结果的数据类型,重写call方法, class MyCallable implements Callable<String> { private int n; public MyCallable(int n) { this.n = n; } @Override public String call() throws Exception { int sum = 0; for (int i = 1; i <= n; i++) { sum += i; } return Thread.currentThread().getName() + "执行1-" + n + "结果是:" + sum; } }
4. 线程优先级
- 线程调度
- 分类:
- 分时调度模型:所有线程轮流使用 CPU 的使用权,平均分配每个线程占用 CPU 的时间片
- 抢占式调度模型:优先让优先级高的线程使用 CPU,如果线程的优先级相同,那么会随机选择一个,优先级高的线程获取的 CPU 时间片相对多一些
- Java的机制:抢占式。(随机性)
CPU某一时刻只能执行一条指令,某个线程得到CPU时间片即使用权才可以执行指令。线程抢到使用权是随机的,所以多线程程序具有随机性
- 分类:
- 线程优先级
-
优先级范围:1-10
最高优先级:Thread.MAX_PRIORITY //10
最低优先级:Thread.MIN_PRIORITY //1
默认优先级:Thread.NORM_PRIORITY //5 -
api
方法 说明 final int getPriority() 返回此线程的优先级 final void setPriority(int newPriority) 更改此线程的优先级
-
5. 线程控制
- api
- 线程操作对象的API
方法 作用 wait() 使线程阻塞,使线程释放所持有对象的锁 notify() 唤醒处于等待的线程,jvm决定唤醒哪个线程,与优先级无关 notifyAll() 唤醒所有处于等待的线程,然后让他们竞争,最终获得锁的线程进入就绪 - 线程本身状态的API
方法 作用 名称 static void sleep(long millis) 使线程睡眠,调用此方法需要处理异常 休眠 public static void yield() 当前线程主动放弃时间片,返回就绪 放弃(让渡) void join() 等待这个线程死亡 合并(插队) void setDaemon(boolean on) 将此线程标记为守护线程,当运行的线程都是守护线程时,Java虚拟机将退出 守护线程 stop(不推荐) 强制线程终止,相当于电脑断电 interrupt() 打断线程 - 实现线程停止:
- 法一:stop()(不推荐)
- 法二:interrupt:系统对现场定义的标识,通过改变该标识的值实现线程停止
注:当线程正在休眠,通过interrupt终止线程会异常
使用:主线程 停用 线程1类
线程1需要添加
主线程//当该线程被interrupt时,该线程执行break if(Thread.interrupted()){ break; }//停用线程 t1.interrupt; - 法三:添加自定义标识
private
- 线程操作对象的API
- 代码:
//sleep @Override public void run() { for (int i = 0; i < 100; i++) { System.out.println(getName() + ":" + i); try { Thread.sleep(1000); } catch (InterruptedException e) { e.printStackTrace(); } } } //join:当康熙这个线程执行结束后,四阿哥和八阿哥才会开始执行 t1.setName("康熙"); t2.setName("四阿哥"); t3.setName("八阿哥"); t1.start(); try { t1.join(); } catch (InterruptedException e) { e.printStackTrace(); } t2.start(); t3.start(); //setDaemon:当刘备执行结束后,关羽和张飞会立马结束(有一点延迟) //关羽张飞执行输出0-99 t1.setName("关羽"); t2.setName("张飞"); //设置主线程为刘备,刘备输出0-9 Thread.currentThread().setName("刘备"); //设置守护线程 t1.setDaemon(true); t2.setDaemon(true); t1.start(); t2.start(); for(int i=0; i<10; i++) { System.out.println(Thread.currentThread().getName()+":"+i); } - sleep VS wait
- sleep:休眠,Thread的静态方法,调用会将CPU让给其他线程,但是对象锁依然保持,结束后恢复就绪
- wait:Object类的方法,线程A调用了某个对象的wait()方法,线程A就会释放该对象的锁,进入对象等待池。只有调用对象的notify()或notifyAll()才能唤醒等待池中的线程进入锁池,准备重新竞争资源,当线程重新获得对象的锁后就进入就绪。
- yield() vs sleep()
- yeild给其他线程运行机会时考虑优先级,只会给同等优先级或更高优先级线程机会。yeild后就绪。不抛异常
- sleep不考虑优先级。sleep后阻塞。会抛异常。可移植性高
6. 线程生命周期

- 阻塞:
调用wait()进入等待池
同步代码块被其他线程执行进入等锁池
调用sleep()或join()等待休眠或其他线程结束
io终端
7. 线程死锁
- 死锁:
当一个线程持有锁A,等待锁B,另一个线程持有锁B,等待锁A。两个线程都不会释放锁,也无法获取锁,则产生死锁。
8. 线程通信
- 线程通信:线程间相互发送数据,线程间共享一个资源即可实现线程通信
- 常见形式:
1、通过共享一个数据的方式实现。
2、根据共享数据的情况决定自己该怎么做,以及通知其他线程怎么做。
4.2 线程同步
问题:线程安全
-
线程安全:多个线程同时操作同一个共享资源的时候可能会出现业务安全问题,称为线程安全问题。
-
原因:存在多线程并发、同时访问共享资源、存在修改共享资源
-
情景
- 需求:小明和小红是一对夫妻,他们有一个共同的账户,余额是10万元,模拟2人同时去取钱10万。
- 分析:
①:需要提供一个账户类,创建一个账户对象代表2个人的共享账户。Account类
②:需要定义一个线程类,线程类可以处理账户对象。public class Account { private String cardId; //卡号 private double money; // 余额 关键信息 //getset构造器 //取钱 public void drawMoney(double money) { // 1、判断是谁来取钱 String name = Thread.currentThread().getName(); // 2、判断余额是否足够 if(this.money >= money){ // 2.1 钱够了 System.out.println(name+"来取钱,吐出:" + money); // 更新余额 this.money -= money; System.out.println(name+"取钱后,余额剩余:" + this.money); }else{ // 2.2 余额不足 System.out.println(name+"来取钱,余额不足!"); } } }
③:创建测试类public class DrawThread extends Thread{ private Account acc; public DrawThread(Account acc, String name){ //Thread类有name属性,即该线程的名字,将本次线程命名为name super(name); this.acc = acc; } @Override public void run() { acc.drawMoney(100000); } }
创建2个线程对象,传入同一个账户对象。
启动2个线程,去同一个账户对象中取钱10万public class TestSafeDemp { public static void main(String[] args) { //取钱问题 //1 创建一个共享的账户对象 Account acc = new Account(); //2 创建2个线程对象,操作同一个账户对象 new DrawThread(acc,"小明"); new DrawThread(acc,"小红"); } } - 问题:

-
解决:线程同步,即让多个线程实现先后依次访问共享数据,
方法一:同步代码块加锁
- 思想:让多个线程实现先后依次访问共享资源,这样就解决了安全问题。
- 实现方式:把共享资源进行上锁,每次只能一个线程进入访问完毕以后解锁,然后其他线程才能进来
synchronized(同步锁对象) { 操作共享资源的代码(核心代码) } - 注意:
- 当一个线程进入一个对象的synchronized的方法A之后,其他线程无法进入此对象的synchronized方法B
原因:当有一个进程进入A方法,说明对象锁已被取走,那么其他线程想进入B,需要在等锁池等待对象锁。
- 当一个线程进入一个对象的synchronized的方法A之后,其他线程无法进入此对象的synchronized方法B
- 锁对象(即括号内部的)要求:
1. 规范上:建议使用共享资源作为锁对象。
*对于实例方法,共享资源建议使用this作为锁对象。
*对于静态方法,共享资源建议使用字节码(类名.class)对象作为锁对象
2. 不可以为任意对象:会影响到其他无关线程
-
案例:
- 代码:
为Account的取钱方法的关键代码块添加synchronized锁:选择所选代码,按ctrl+alt+t,//取钱 public void drawMoney(double money) { // 1、判断是谁来取钱 String name = Thread.currentThread().getName(); //同步代码块加锁,()里为唯一对象,"person" synchronized (this) { // 2、判断余额是否足够 if(this.money >= money){ // 2.1 钱够了 System.out.println(name+"来取钱,吐出:" + money); // 更新余额 this.money -= money; System.out.println(name+"取钱后,余额剩余:" + this.money); }else{ // 2.2 余额不足 System.out.println(name+"来取钱,余额不足!"); } } }
- 代码:
方法二:同步方法加锁
- 作用:把出现线程安全问题的核心方法给上锁。
- 原理:每次只能一个线程进入,执行完毕以后自动解锁,其他线程才可以进来执行。
a、对于实例方法默认使用this作为锁对象。
b、对于静态方法默认使用类名.class对象作为锁对象。 - 格式
修饰符 synchronized 返回值类型 方法名称(形参列表) { 操作共享资源的代码 } - 底层
同步方法其实底层也是有隐式锁对象的,只是锁的范围是整个方法代码。
如果核心方法为实例方法,默认使用this作为锁对象
如果核心方法是静态方法,默认使用类名.class作为锁对象 - 代码
//取钱 public synchronized void drawMoney(double money) { // 0、先获取是谁来取钱,线程的名字就是人名 String name = Thread.currentThread().getName(); // 1、判断账户是否够钱 if(this.money >= money){ // 2、取钱 System.out.println(name + "来取钱成功,吐出:" + money); // 3、更新余额 this.money -= money; System.out.println(name + "取钱后剩余:" + this.money); }else { // 4、余额不足 System.out.println(name +"来取钱,余额不足!"); } }
方法三:lock锁(jdk5)
- lock:lock是接口,不可实例化,采用它的实现类ReentrantLock来构建Lock锁对象。
- 使用步骤
- 为账户类添加一个私有锁:
private final Lock lock = new ReentrantLock();唯一不可替换 - 在核心代码块之前上锁:
lock.lock(); - 核心代码块结束时解锁:
lock.unlock(); - 优化:当核心代码异常时,无法执行到解锁步骤,则程序崩溃。故需要加核心代码块放在try catch中
- 为账户类添加一个私有锁:
- 代码:Account类
private String cardId; //卡号 private double money; // 余额 关键信息 private final Lock lock = new ReentrantLock(); //取钱 public void drawMoney(double money) { // 1、判断是谁来取钱 String name = Thread.currentThread().getName(); //上锁 lock.lock(); try { // 2、判断余额是否足够 if(this.money >= money){ // 2.1 钱够了 System.out.println(name+"来取钱,吐出:" + money); // 更新余额 this.money -= money; System.out.println(name+"取钱后,余额剩余:" + this.money); }else{ // 2.2 余额不足 System.out.println(name+"来取钱,余额不足!"); } } finally { //解锁 lock.unlock(); } }
sychronized VS lock
- sychronized:只能特定情况下(程序正常执行或异常情况jvm自动释放锁)放锁、无法知道进程是否成功获得锁
- lock:可以自由放锁(要求程序员手动在finally块中释放锁)、可以知道进程有没有成功获得锁
是同步代码块好还是同步方法好一点?
同步代码块锁的范围更小(性能更好),同步方法锁的范围更大(使用较多)
4.3 线程池ExecutorService
1. 概述
- 含义:可以复用线程的技术。
线程池接口:ExecutorService - 场景:如果用户每发起一个请求,后台就创建一个新线程来处理,下次新任务来了又要创建新线程,而创建新线程的开销是很大的,这样会严重影响系统的性能。
- 原理:

-
获取线程池对象:
方法一:⭐使用ExecutorService的实现类ThreadPoolExecutor自创建一个线程池对象
方法二:使用Executors(线程池的工具类)调用方法返回不同特点的线程池对象 -
线程池面试题:
- 临时线程创建时机:新任务提交时发现核心线程都在忙,任务队列也满了,并且还可以创建临时线程,此时才会创建临时线程
- 拒绝任务时机:核心线程和临时线程都在忙,任务队列也满了,新的任务过来的时候才会开始任务拒绝
2. TreadPoolExecutor创建线程池
TreadPoolExecutor介绍
-
TreadPoolExecutor构造器

-
线程池api
方法 说明 void execute(Runnable command) 执行任务/命令,没有返回值,一般用来执行 Runnable 任务 Future submit(Callable task) 执行任务,返回未来任务对象获取线程结果,一般拿来执行 Callable 任务 void shutdown() 等全部任务执行完毕后关闭线程池 List shutdownNow() 立刻关闭,停止正在执行的任务,并返回队列中未执行的任务。即使任务未完成,会丢失任务 -
使用方法
- 创建线程池对象
ExecutorService pools = new ThreadPoolExecutor(3, 5 , 8 , TimeUnit.SECONDS, new ArrayBlockingQueue<>(5), Executors.defaultThreadFactory() , new ThreadPoolExecutor.AbortPolicy()); - 为线程池添加任务
- 运行程序
- 创建线程池对象
-
任务增多时
- 进入任务队列
当为任务设置很长的休眠时间时,前三个任务正在执行,再加入第4-8个任务都会进入任务队列等待执行 - 临时线程
当加入第9个任务时,由于任务队列已满,就会开始创建临时线程(最多两个临时线程) - 任务拒绝
当加入第11个任务时,就会出现任务忙,拒绝任务,即出错
- 进入任务队列
-
新任务拒绝策略

处理Runnable任务(execute方法)
- 定义Runnable任务,MyRunnable.class
public class MyRunnable implements Runnable{ @Override public void run() { for (int i = 0;i < 5; i++){ //Thread.currentThread().getName():获取当前任务的名字,默认为数字 System.out.println(Thread.currentThread().getName() + "输出了" + i); try { //当前三个任务在休眠时,后两个任务不会执行,会进入任务队列 System.out.println("正在休眠"); Thread.sleep(1000000); } catch (InterruptedException e) { e.printStackTrace(); } } } } - 定义线程池
public class ThreadPoolDemo1 { public static void main(String[] args) { //1、获取线程池 ThreadPoolExecutor pools = new ThreadPoolExecutor(3, 5, 8, TimeUnit.SECONDS, new ArrayBlockingQueue<>(5), Executors.defaultThreadFactory(), new ThreadPoolExecutor.AbortPolicy()); //2、为线程池添加5个Runnable任务 Runnable target = new MyRunnable(); pools.execute(target); pools.execute(target); pools.execute(target); pools.execute(target); pools.execute(target); } } - 结果

处理Callable任务(submit方法)
- 编写Callable类
/定义一个Callable任务类,实现接口,声明任务执行完毕后返回结果的数据类型,重写call方法, public class MyCallable implements Callable<String> { private int n; public MyCallable(int n) { this.n = n;} @Override public String call() throws Exception { int sum = 0; for (int i = 1; i <= n; i++) { sum += i; } return Thread.currentThread().getName() + "执行1-" + n + "结果是:" + sum; } } - 编写测试类
public class ThreadPoolDemo1 { public static void main(String[] args) throws ExecutionException, InterruptedException { //1、声明线程池 ThreadPoolExecutor pools = new ThreadPoolExecutor(3, 5, 8, TimeUnit.SECONDS, new ArrayBlockingQueue<>(6), Executors.defaultThreadFactory(), new ThreadPoolExecutor.AbortPolicy()); //2、把Callable任务交给线程池 Future<String> f1 = pools.submit(new MyCallable(100)); Future<String> f2 = pools.submit(new MyCallable(200)); Future<String> f3 = pools.submit(new MyCallable(300)); Future<String> f4 = pools.submit(new MyCallable(400)); //3、f1.get():获取任务1的结果 System.out.println(f1.get()); System.out.println(f2.get()); System.out.println(f3.get()); System.out.println(f4.get()); } }
3. Executors工具类创建线程池(不建议)
- Executors:线程池的工具类通过调用方法返回不同类型的线程池对象
Executors的底层:也是基于线程池的实现类ThreadPoolExecutor创建线程池对象的
缺点:队列可以无限添加任务,但是不会报错,因此在大型并发系统环境中使用Executors如果不注意可能会出现系统风险 - api
方法 说明 public static ExecutorService newCachedThreadPool() 线程数量随着任务增加而增加,如果线程任务执行完毕且空闲了一段时间则会被回收掉。 public static ExecutorService newFixedThreadPool(int nThreads) 创建固定线程数量的线程池,如果某个线程因为执行异常而结束,那么线程池会补充一个新线程替代它。 public static ExecutorService newSingleThreadExecutor () 创建只有一个线程的线程池对象,如果该线程出现异常而结束,那么线程池会补充一个新线程。 public static ScheduledExecutorService newScheduledThreadPool(int corePoolSize) 创建一个线程池,可以实现在给定的延迟后运行任务,或者定期执行任务。 - 实例
-
newFixedThreadPool
public class ThreadPoolDemo1 { public static void main(String[] args) throws ExecutionException, InterruptedException { //1、声明只有3个线程的线程池 ExecutorService pools = Executors.newFixedThreadPool(3); //2、添加任务(只有前3个执行完毕后,第四个才可以执行) pools.execute(new MyRunnable()); pools.execute(new MyRunnable()); pools.execute(new MyRunnable()); pools.execute(new MyRunnable()); } }
-
4.4 补充
1. 定时器
- 定时器是一种控制任务延时调用,或者周期调用的技术。
- 作用:闹钟、定时邮件发送。
- 定时器的实现方式
方式一:Timer
方式二: ScheduledExecutorService
Timer创建定时器
-
Timer定时器
-
api
方法 说明 public Timer() 创建Timer定时器对象 public void schedule(TimerTask task, long delay, long period 开启一个定时器,按照计划处理TimerTask任务 TimerTask:底层是Runnable,即任务
delay:启动后过多长时间开始执行
period:执行周期时间 -
使用:
public class ThreadPoolDemo1 { public static void main(String[] args) throws ExecutionException, InterruptedException { //1、创建Timer对象 Timer timer = new Timer(); //2、为Timer添加任务 timer.schedule(new TimerTask() { @Override public void run() { System.out.println(Thread.currentThread().getName() + "执行AAA" + new Date()); } }, 0, 2000); } } -
缺点:
1、Timer是单线程,处理多个任务按照顺序执行,存在延时与设置定时器的时间有出入。
2、可能因为其中的某个任务的异常使Timer线程死掉,从而影响后续任务执行。
ScheduledExecutorService创建定时器
-
ScheduledExecutorService是:jdk1.5中引入了并发包,目的是为了弥补Timer的缺陷, ScheduledExecutorService内部为线程池。
-
底层:基于线程池ExecutorService,某个任务的执行情况不会影响其他定时任务的执行。
-
api:

-
使用:
public static void main(String[] args) throws ExecutionException, InterruptedException { //1、获取ScheduledExecutorService对象(获取ScheduledExecutorService对象基于ExecutorService,故可以使用Executors工具类) ScheduledExecutorService pool = Executors.newScheduledThreadPool(3); //2、开启定时任务A pool.scheduleAtFixedRate(new TimerTask() { @Override public void run() { System.out.println(Thread.currentThread().getName() + "执行AAA ==>" + new Date()); try { Thread.sleep(100000); } catch (InterruptedException e) { e.printStackTrace(); } } },0,2,TimeUnit.SECONDS); //3、开启定时任务B pool.scheduleAtFixedRate(new TimerTask() { @Override public void run() { System.out.println(Thread.currentThread().getName() + "执行BBB ==>" + new Date()); } },0,2,TimeUnit.SECONDS); }
2. 并发与并行
- 条件:正在运行的程序(软件)就是一个独立的进程, 线程是属于进程的,多个线程其实是并发与并行同时进行的
- 并发:CPU轮询为系统的每个线程服务。一位老师用一个手掌依次打学生
- 并行:CPU同时服务多个线程。一位老师用两个手掌同时多个学生
3. 线程的生命周期
- 线程Tread类中定义了6种状态

- 状态转换:

五、包、权限修饰符、关键字、抽象类、接口
5.1 包
- 语法格式:package 公司域名倒写.技术名称。报名建议全部英文小写,且具备意义
- 权限:
1、相同包下的类可以直接访问,不同包下的类必须导包,才可以使用
2、假如一个类中需要用到不同类,而这个两个类的名称是一样的,那么默认只能导入一个类,另一个类要带包名访问:com.itheima.demo2.Cat c2 = new com.itheima.demo2.Cat(); - 导包:import 包名.类名;
5.2 权限修饰符
- 权限修饰符:是用来控制一个成员能够被访问的范围的
- 修饰范围:成员变量,方法,构造器,内部类
- 分类:作用范围由小到大(private -> 缺省 -> protected - > public )

- 使用习惯
1、成员变量一般私有。
2、方法一般公开。
3、如果该成员只希望本类访问,使用private修饰。
4、如果该成员只希望本类,同一个包下的其他类和子类访问,使用protected修饰。
5.3 抽象类和接口
1. 抽象类和抽象方法
- 抽象类
- 含义:某个父类知道其所有子类要完成某个功能,但是不同子类完成情况不一样。父类只定义该功能的基本要求,具体实现交给子类。这个类就是抽象类。abstract修饰
- 声明:
修饰符 abstract class 类名{ } - 成员:
构造器:被继承后,子类必须调用抽象类的构造器。
成员变量
方法:抽象方法,实例方法 - 作用:被子类继承,提高代码重复利用
- 注意
- 抽象类不可被实例化
原因:抽象类的抽象方法无法执行 - 一个类如果继承了抽象类,那么这个类必须重写完抽象类的全部抽象方法,否则这个类也必须定义成抽象类。
- 抽象类中不一定有抽象方法,有抽象方法的类一定是抽象类
- 抽象类不可被实例化
- 抽象方法
- 含义:没有方法体,只有方法声明。abstract修饰
- 格式:
修饰符 abstract 返回值类型 方法名称(形参列表); - 作用:被子类重写
- 抽象类的应用:模板方法模式
- 使用场景:当系统中出现同一个功能多处在开发,而该功能中大部分代码是一样的,只有其中部分可能不同的时候
- 步骤:
- 1、把功能定义成一个所谓的模板方法,放在抽象类中,模板方法中只定义通用且能确定的代码。
- 2、模板方法中不能决定的功能定义成抽象方法让具体子类去实现。
- 注意:模板方法我们是建议使用final修饰的,因为模板方法是给子类直接使用的,不是让子类重写的,
一旦子类重写了模板方法就失效了 - 案例:不同银行账户有不同的登录后计算利息方法,
- 解决:
1、可以将账户定义成为统一的模板类型即抽象类
2、将登陆定义为模板方法(final修饰,子类可直接调用),计算利息方法为抽象方法(子类重写)。登陆方法中会调用计算利息方法。
3、定义具体类型账户继承抽象类,重写计算利息方法
- 解决:
2. 接口
-
概念:是一种规范,用抽象方法定义的一组行为规范
-
声明
//接口用关键字interface来定义 public interface 接口名 { // 常量 // 抽象方法 } -
成员:
抽象方法:public abstract修饰的,可省略
常量: -
用法:用来被类实现(implements)的,实现接口的类称为实现类。实现类可以理解成所谓的子类
//实现的关键字:implements 修饰符 class 实现类 implements 接口1, 接口2, 接口3 , ... { } -
特点:
- 1、不可被实例化
- 2、接口可被多实现。
多个接口中有同样的静态方法:只能接口自己调用,实现类不可调用
同名的默认方法不冲突,需要重写 - 3、接口可多继承
如果多个接口中存在规范冲突则不能多继承。如返回值不同方法名相同 - 4、类即可实现接口,又可继承父类
接口和父类中有同样的静态方法,父类方法优先
-
jdk8新特性
- 情况:当接口需要新增10个抽象方法时,此时所有实现该接口的类都需要重写该方法。jdk8后可以允许接口直接定义带有方法体的方法
- 解决
- 默认方法:用default修饰的普通实例方法,默认会public修饰
- 静态方法:用static修饰的静态方法,默认会public修饰
- 私有方法(jdk9):用private修饰的私有的实例方法,只能在本类中被其他的默认方法或者私有方法访问
5.4 关键字
final和finally、finalize
-
final
- 含义:最终
- 修饰范围:
- 1、修饰方法:表明该方法是最终方法,不能被重写。
- 2、修饰变量:表示该变量第一次赋值后,不能再次被赋值(有且仅能被赋值一次)。
变量是基本类型:那么变量存储的数据值不能发生改变。
变量是引用类型:那么变量存储的地址值不能发生改变,但是地址指向的对象内容是可以发生变化的 - 3、修饰类:表明该类是最终类,不能被继承。
abstract:抽象类的抽象方法,不可修饰变量、代码块、构造器
final 和 abstract:互斥关系,final不可被继承,abstract用来被继承
-
finally:try catch后,无论是否有异常都要执行
-
finalize:Object类的方法,整理系统资源或执行清理工作
throw和throws
throw和throws的区别:
throw:在方法内部直接创建一个异常对象并抛出
throws:在方法声明上,抛出内部的异常
volatile和transient
- volatile修饰的变量:程序快速运行时,读取该变量不会从缓存中读取,而是直接读取该变量最新值,但是降低了性能。
- 程序访问变量机制:当程序有执行其他慢操作(如打印或休眠)时,就不会直接读取缓存,这时候可以不加关键字
- volatile vs synchronized:
volatile:仅仅保证可见性,无法保证互斥性,所以不安全
synchronized:不仅有可见性,还有保正了互斥性
- transient
static、instanceof
- 用法:
- 静态变量、静态方法:为类共享的资源
- 静态代码块:用于初始化操作
public class PreCache{ static{ //操作 } } - 静态内部类
- 静态导包:import.static 包名:导入该包中所有的静态资源
- instanceof关键字
- 作用:测试一个对象是否为一个类的实例
- 格式:boolean result = obj instanceof ClassName
obj: 必须为引用类型,null也不行
boolean result = s1 instanceof Student;
六、异常Throwable
throw和throws的区别: throw在方法内部直接创建一个异常对象并抛出;throws在方法声明上,抛出内部的异常
6.1 异常体系
不处理异常:程序退出jvm暂停运行
- 错误Error:系统级别错误,编译时不检查。如jvm退出,代码无法控制,内存溢出
- 异常类Exception
- 运行时异常RuntimeException
- 特点:编译阶段不报错,即写代码时不会报红。
程序员业务没有考虑好,逻辑不严谨的错误 - 例如:空指针异常,数组下标越界,数字操作异常。类型转换异常,数字转换异常
- 特点:编译阶段不报错,即写代码时不会报红。
- 编译时异常
- 特点:无法通过编译阶段,即写代码时会报红
程序员抛出异常才能解决报红。throws - 例如:简单日期格式化类、IO异常、文件不存在异常,SQL语句异常
- 特点:无法通过编译阶段,即写代码时会报红
- 运行时异常RuntimeException
6.2 异常处理机制
- 默认处理机制
- 缺点:一旦真的出现异常,程序立即死亡!
- 步骤:
- 默认会在出现异常的代码那里自动的创建一个异常对象:ArithmeticException。
- 异常会从方法中出现的点这里抛出给调用者,调用者最终抛出给JVM虚拟机。
- 虚拟机接收到异常对象后,先在控制台直接输出异常栈信息数据。
- 直接从当前执行的异常点干掉当前程序。
- 后续代码没有机会执行了,因为程序已经死亡。

- 编译时异常处理机制:
-
形式一:throws
- 使用:用在方法上,可以将方法内部出现的异常抛出去给本方法的调用者处理
- 特点:发生异常的方法自己不处理异常,如果异常最终抛出去给虚拟机将引起程序死亡。后续程序无法执行
- 格式:

-
形式二:try…catch…
- 使用:监视捕获异常,用在方法内部,可以将方法内部出现的异常直接捕获处理
- 特点:发生异常的方法自己独立完成异常的处理,程序可以继续往下执行
- 格式:

-
形式三:两者结合(推荐)
- 使用:
方法直接将异通过throws抛出去给调用者
调用者收到异常后直接捕获处理。
- 使用:
-
- 运行时异常的处理机制
- 运行时异常:运行时异常编译阶段不会出错,是运行时才可能出错的,所以编译阶段不处理也可以。
- 解决:建议在最外层调用处集中捕获处理即可。
6.3 自定义异常
- 必要性:
Java无法为这个世界上全部的问题提供异常类。
如果企业想通过异常的方式来管理自己的某个业务问题,就需要自定义异常类了。 - 好处:
a、可以使用异常的机制管理业务问题,如提醒程序员注意。
b、同时一旦出现bug,可以用异常的形式清晰的指出出错的地方。 - 步骤:
- 自定义编译时异常
- 1、定义一个异常类继承Exception.
- 2、重写构造器。(无参构造和含message构造)
public class MyIllegalException extends Exception{ public MyIllegalException() { } public MyIllegalException(String message) { super(message); } } - 3、在出现异常的地方用throw new 自定义对象抛出
public class MyTest { public static void main(String[] args) throws MyIllegalException { //两者结合 try{ checkAge(1111); }catch(Exception e){ e.printStackTrace(); } System.out.println("程序结束"); } public static void checkAge(int age) throws MyIllegalException { if (age < 0 || age > 200){ throw new MyIllegalException(age + "不合法。。。。。"); }else { System.out.println(age + "合法"); } } } - 作用:编译时异常是编译阶段就报错,提醒更加强烈,一定需要处理!!
- 自定义运行时异常
- a、定义一个异常类继承RuntimeException.
- b、重写构造器。
- c、在出现异常的地方用throw new 自定义对象抛出!
- 作用:提醒不强烈,编译阶段不报错!!运行时才可能出现!!
- 自定义编译时异常















 983
983











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









