







输入端
Promt定义
hard-encoding
对于比较明确、简短的任务,使用人工定义。
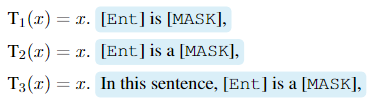
soft-encoding
使用的promt如下,其中,[P]为分隔符,[P1],...,[Pl]为随机初始化的向量。从直觉上来说,经过训练以后,[P1],...,[Pl]所表示的向量与[MASK] 相近。
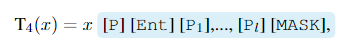
Answer映射
一个实体可能是多类别的,并且有层级关系。比如:LOCATION与CITY,对与这些实体我们把label当作词表中的对应的label words。例如:
y
=
L
O
C
A
T
I
O
N
/
C
I
T
Y
→
v
=
{
l
o
c
a
t
i
o
n
,
c
i
t
y
}
y=LOCATION/CITY \rightarrow v = \{location,city\}
y=LOCATION/CITY→v={location,city}
另外对于一个label,把这个label的相关词(通过该工具查找:https://relatedwords.org)也加入label words。例如:city的相关词为metropolis, town, municipality, urban, suburb, municipal, megalopolis, civilization, downtown, country。
所以city的label words为location, city, metropolis, town, municipality, urban, suburb, municipal, megalopolis, civilization, downtown, country。
最后,用这些label words的加权和来表示这个label的概率:
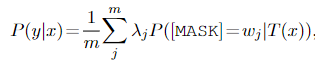
训练
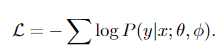
φ为模板的参数,θ为预训练模型参数,loss采用交叉熵。
针对zero-shot的自监督Prompt-learning
上面的都是有训练数据集的情况,而针对没有训练数据的zero-shot问题来说,就不适用了。
作者发现比如一句话:
Steve Jobs found Apple. In this sentence, Steve Jobs is a [MASK]中的Steve Jobs预测为person的概率要远大于location,作者认为预训练模型的知识蕴含了类别信息。
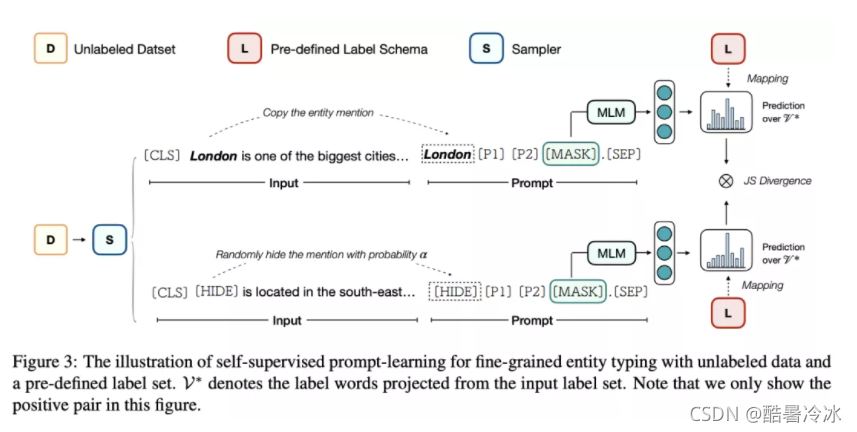
作者认为相同的实体在不同的句子中具有类似的类型,比如
Steve Jobs”在不同句子中可以为entrepreneur, designer, philanthropist
所以优化同样的实体的句子使得它们的预测具有相同的分布。这种方法在自监督学习中不仅弱化了监督性,也削弱了除了实体词外其他词的影响。
如上图所示,其中作者为了防止过拟合,也采用[HIDE]的方法来替代实体,根据实验选择0.4的概率。
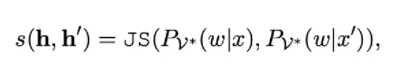
其中JS为Jensen-Shannon divergence,主要为了使两分布更加相近。
另外也找了正负样例,其中负样例来自一个大型的实体链接库(English Wikipedia)。
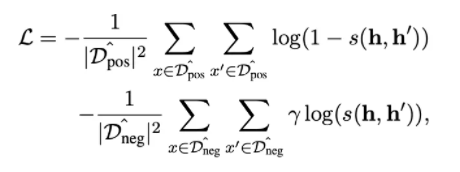
引用
Prompt-Learning for Fine-Grained Entity Typing
清华提出:用于细粒度实体分类的Prompt-Learning,并提出可训练Prompt模板


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









