







中文信息处理复习提纲
第二章 自动分词(传统方法)
2.1基本问题
中文分词
自动分词:将中文文本字串转为词串的过程
2.2分词规范
常用分词规范
——切分规范
现代汉语语料库加工规范 ——切分和标注相结合的规范
——标注规范
切分单位:沿用“分词单位”,主要是词
**人名:**名人名字
地名:后面有省市不切分
**数量词:**数词和量词分开
重叠:AA,AAB,AABB等
附加:e.g 阿花 老张
复合:e.g 前院 左肩
2.3方法概述
分词方法分类
| 非语料库 | 语料库 | |
|---|---|---|
| 词典 | 机械分词 | 混合分词 |
| 非词典 | 自分割分词 | 统计分词(基于统计/机器学习) |
分词词典
·基本结构
索引表
·构建词典考虑
查询速度
存储利用率
维护效能
2.4 机械分词
·正向最大匹配

·逆向最大匹配
与正向类似,只不过从尾部开始取MAXL
·正向最小匹配

·逆向最小匹配
与正向类似,只不过从尾部开始取
·邻近匹配

·最短路径匹配

第二章 自动分词(歧义消解)
1.基本问题
影响分词准确率的主要是未登陆词和歧义
2.基本概念
歧义种类
1.切词中的歧义
固有歧义——根据不同语境所出现的分词歧义
组合歧义——指某个字串本身不组成一个词,而在不同的语境条件下,产生不同的组合切分
2.词的歧义
词性歧义——e.g 学习
词义歧义——e.g 红花 红军
3.结构歧义
指由词组成词组或句子时,由于其组成的词或词组间可能存在不同语法或语义关系而出现的歧义
4.指代和省略中的歧义
指代词和代词词组所指的事件可能存在歧义
省略造成的歧义
e.g 他说不清楚
歧义字段类型
交叉歧义字段(交集型)
组合歧义字段
歧义字段发现的方法
采用双向扫描,对同一字段,分别采用正向匹配和逆向匹配,若结果相同,认为切分正确,否则被判别为歧义字段
歧义字段的处理方法
采用1.规则知识和2.统计信息相结合的方法
3.基于规则的分词消歧
分词预处理中的规则
借助标记
借助特殊标记,包括标点符号、数字等
固定表达
处理特殊短语,数字短语、时间短语、货币单位等
固定短语的识别方法
在预处理阶段增加一次独立的扫描过程,根据系统中的特征词表,在扫描到数字后调用数字识别模块,确定由标点符号和连接词连接起来的数词的左右边界,然后在左右边界附近寻找前缀词、概数词和特征词,最后将语句完整地切分开,并根据特征词确定短语类型
分词规则
专用规则
针对某一特定的歧义字段
通用规则
构词规则
前缀词构词规则
后缀词构词规则
重叠字构词规则
排歧规则
(1)成词切分优先
(2)单子方位词不足词
(3)量词优先
(4)单子动词尽可能单独切分
(5)链长为2的交集字段自然成词
4.基于统计的分词消歧
基于词频
词频相乘

缺点:只考虑了词频而未考虑词性以及词义,错误率较高
基于互信息和t-测试差
处理对象:交叉型歧义划分字段
统计来源:未经加工的生语料
最大特点:值获取(统计)过程完全自动化
互信息
>> 0 ,xy有很强结合
== 0 ,xy结合还行,关系不明确
< 0 ,xy结合不好
t-测试
t-测试差
第二章 自动分词(新方法)
1.方法概述
分词方法分类
·根据使用资源不同
| 非语料库 | 语料库 | |
|---|---|---|
| 词典 | 机械分词 | 混合分词 |
| 非词典 | 自分割分词 | 统计分词(基于统计/机器学习) |
2.语料库
概念:指为语言研究收集的、以电子形式保存的语言材料
基本特征:
·语料库中存放的语言材料是真实存在的;
· 语料库以计算机为载体来承载语言材料;
· 语料库需要经过加工才能成为有用资源
生语料&熟语料
熟语料是指加了“标注”的语料,通过“标注”(分类代码)可以了解文件的结构或格式信息
3.自分割分词
定义:一种无词典分词方法,除了待处理的文本之外无需外部的词典或语料库
分词步骤:输入待切分字串S;输出切分后的字串S’

总结:非常适合处理名词短语分词,但是它不是对所有的文本都能得到有效的结果。
4.机器学习分词
序列标注问题
字分为4类:
S表示单字
B表示词首
M表示词中
E表示词尾
分词问题转换为分类问题

序列标注模型
传统:
正向最大匹配
隐马尔科夫模型HMM
基于机器学习的:
最大熵模型MEM
最大熵隐马尔科夫模型MEMM
条件随机场CRF
深度神经网络,如RNN,LSTM
最大熵模型
按照模型熵最大的原则来选择模型,n在包含已知信息的情况下,不做任何未知假设,把未知事件当成等概率事件处理

例题:

5.分词总结
待续
第六章 自动标注
基本概念
定义:标注过程,根据给定文本中词的上下文信息,确定文本中词在给定分类标准下的正确标记的过程
v:动词
q:量词
r:代词
n:名词
歧义来源
对于只属于一个固定词类的词,仅简单地将该词标上相应的词类;
对于有多个可能的标记的词,所有这些不同的标记,组成了该词标注过程中的歧义。
歧义消除
信息源:
词本身的信息:如一个词不同词性的使用频率
上下文信息:语境、歧义间的统计差异、文本的领域特征

标注的一般模型
两步模型:当前考察词wi的正确标记ti仅依赖于直接前趋词wi-i和其标记ti-1
三步模型:
当前词的前趋词wi-1 、wi-2及其标记ti-1、ti-2
词典
重要性
自动标注过程用到的最重要的知识库之一,一个强有力的词典是保证标注成功的重要保证。

*马尔科夫模型
如果一个系统有N个状态S1,S2,…,SN,随时间的推移,该系统从某一状态转移到另一状态。系统在时间t的状态记为qt。系统在时间t处于状态Sj(1≤j≤N)的概率取决于其在时间1,2,…,t-1的状态,该概率为:
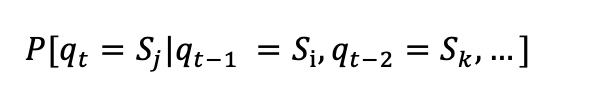
无后效性假设
时间t的状态只与t-1的状态相关

离散的马尔可夫模型
不动性假设
状态与时间无关
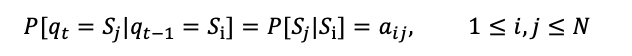
齐次的马尔可夫过程
aij为转移概率,即状态Si转移到Sj的概率
*形式描述
转移概率矩阵A:
A={aij},
初始概率分布π :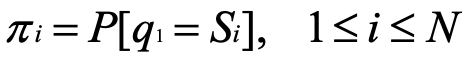
状态序列概率:
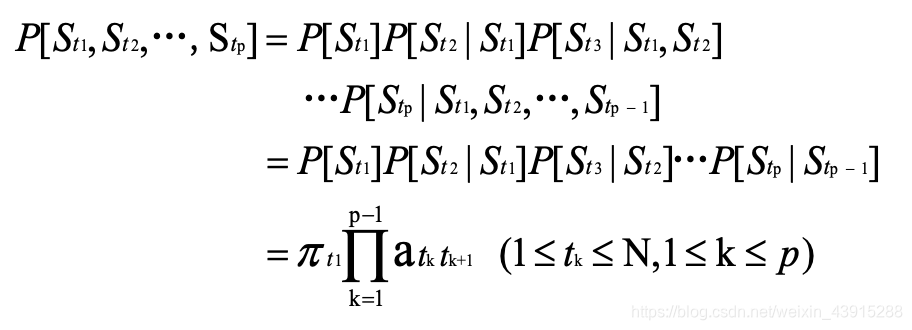
例题:


隐马尔可夫模型
模型描述
HMM(Hidden Markov Model)由马尔可夫过程扩充而来的一种随机模型
HMM状态本身不可观察,可观察的是状态的一个概率函数
HMM包含了双重随机过程,一个是系统状态变化的过程,即马尔可夫过程,另一个是由状态决定观察的随机过程。
*形式描述
状态集合S={S1,S2,…,SN},N为模型的状态数
输出值集合V={V1,V2,…,VM},M为不同观察值的数量
状态转移矩阵A={aij},aij表示状态Si转移到Sj的概率
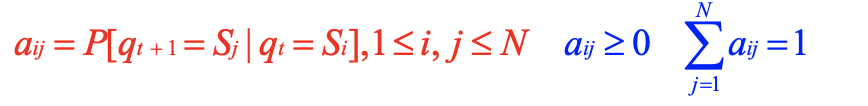
初始状态概率分布π**=(**πi ) ,πi 表示在初始时刻取状态Si的概率;
输出概率分布 B={bj(k)},表示在状态Sj时观察到Vk(第k种)种颜色的概率
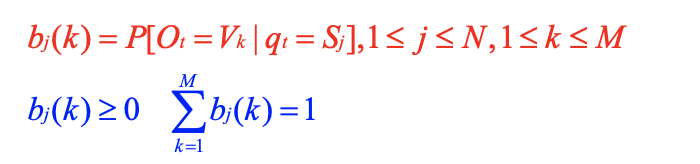
自动词性标注方法
方法分类
基于规则的方法
上下文框架规则
转换规则
约束语法
基于统计的方法
频度
N元模型
HMM
CRF
LSTM
混合方法
CLAWS
基于HMM的词性标注



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









