






创建一个新闻内容类
package com.baifan.lucene.index;
/**
* @author: baifan
* @date: 2021/6/10
*/
public class News {
private int id;
private String title;
private String content;
private int reply;
public News() {
}
public News(
int id, String
title,
String content, int reply) {
super();
this.id = id;
this.title = title;
this.content = content;
this.reply = reply;
}
public int getId() {
return id;
}
public void setId(
int id) {
this.id = id;
}
public String getTitle() {
return title;
}
public void setTitle(
String title) {
this.title = title;
}
public String getContent() {
return content;
}
public void setContent(
String content) {
this.content = content;
}
public int getReply() {
return reply;
}
public void setReply(
int reply) {
this.reply = reply;
}
}
创建索引操作
package com.baifan.lucene.index;
/**
* @author: baifan
* @date: 2021/6/10
*/
import java.io.IOException;
import java.nio.file.Files;
import java.nio.file.Path;
import java.nio.file.Paths;
import java.util.Date;
import com.baifan.lucene.ik.IKAnalyzer6x;
import org.apache.lucene.analysis.Analyzer;
import org.apache.lucene.document.Document;
import org.apache.lucene.document.Field;
import org.apache.lucene.document.FieldType;
import org.apache.lucene.document.IntPoint;
import org.apache.lucene.document.SortedNumericDocValuesField;
import org.apache.lucene.document.StoredField;
import org.apache.lucene.index.IndexOptions;
import org.apache.lucene.index.IndexWriter;
import org.apache.lucene.index.IndexWriterConfig;
import org.apache.lucene.index.IndexWriterConfig.OpenMode;
import org.apache.lucene.store.Directory;
import org.apache.lucene.store.FSDirectory;
public class CreateIndex {
public static void main(
String[] args) {
// 创建3个News对象
News news1 = new News();
news1.setId(1);
news1.setTitle("");
news1.setContent("");
news1.setReply(672);
News news2 = new News();
news2.setId(2);
news2.setTitle("北大迎4380名新生 农村学生700多人近年最多");
news2.setContent("昨天,北京大学迎来4380名来自全国各地及数十个国家 的本科新生。其中,农村学生共700余名,为近年最多...");
news2.setReply(995);
News news3 = new News();
news3.setId(3);
news3.setTitle("");
news3.setContent("");
news3.setReply(1872);
// 创建IK分词器
Analyzer analyzer = new IKAnalyzer6x();
IndexWriterConfig icw = new IndexWriterConfig(analyzer);
icw.setOpenMode(OpenMode.CREATE);
Directory dir = null;
IndexWriter inWriter = null;
// 索引目录
Path indexPath = Paths.get("indexdir");
// 开始时间
Date start = new Date();
try {
if (!Files.isReadable(indexPath)) {
System.out.println("Document directory '" + indexPath.toAbsolutePath() + "' does not exist or is not readable, please check the path");
System.exit(1);
}
dir = FSDirectory.open(indexPath);
inWriter = new IndexWriter(dir, icw);
//设置新闻ID索引并存储
FieldType idType = new FieldType();
//只索引文档,词项频率和位移信息不保存。
idType.setIndexOptions(IndexOptions.DOCS);
idType.setStored(true);
//设置新闻标题索引文档、词项频率、位移信息和偏移量,存储并词条化
FieldType titleType = new FieldType();
//索引文档、词项频率、位移信息和偏移量。
titleType.setIndexOptions(IndexOptions.DOCS_AND_FREQS_AND_POSITIONS_AND_OFFSETS);
titleType.setStored(true);
titleType.setTokenized(true);
FieldType contentType = new FieldType();
contentType.setIndexOptions(IndexOptions.DOCS_AND_FREQS_AND_POSITIONS_AND_OFFSETS);
//参数默认值为false,设置为true存储字段值。
contentType.setStored(true);
//参数设置为true,会使用配置的分词器对字段值进行词条化
contentType.setTokenized(true);
//是否存储词项向量信息
contentType.setStoreTermVectors(true);
//是否存储词项位置
contentType.setStoreTermVectorPositions(true);
//是否存储词项偏移量
contentType.setStoreTermVectorOffsets(true);
//是否存储词项附加信息
contentType.setStoreTermVectorPayloads(true);
Document doc1 = new Document();
doc1.add(new Field("id", String.valueOf(news1.getId()),
idType));
doc1.add(new Field("title", news1.getTitle(),
titleType));
doc1.add(new Field("content", news1.getContent(),
contentType));
doc1.add(new IntPoint("reply", news1.getReply()));
//StoredField适合索引只需要保存字段值不进行其他操作的字段
doc1.add(new StoredField("reply_display", news1.getReply()));
Document doc2 = new Document();
doc2.add(new Field("id", String.valueOf(news2.getId()), idType));
doc2.add(new Field("title", news2.getTitle(), titleType));
doc2.add(new Field("content", news2.getContent(), contentType));
//IntPoint适合索引值为int类型的字段。IntPoint是为了快速过滤的,如果需要展示出来需要另存一个字段。
doc2.add(new IntPoint("reply", news2.getReply()));
doc2.add(new StoredField("reply_display", news2.getReply()));
Document doc3 = new Document();
doc3.add(new Field("id", String.valueOf(news3.getId()), idType));
doc3.add(new Field("title", news3.getTitle(), titleType));
doc3.add(new Field("content", news3.getContent(), contentType));
doc3.add(new IntPoint("reply", news3.getReply()));
doc3.add(new StoredField("reply_display", news3.getReply()));
inWriter.addDocument(doc1);
inWriter.addDocument(doc2);
inWriter.addDocument(doc3);
inWriter.commit();
inWriter.close();
dir.close();
} catch (IOException e) {
e.printStackTrace();
}
Date end = new Date();
System.out.println("索引文档用时:" + (end.getTime() - start.getTime()) + " milliseconds");
}
}
运行结果:
加载扩展词典:ext.dic
加载扩展停止词典:stopword.dic
加载扩展停止词典:ext_stopword.dic
索引文档用时:724 milliseconds
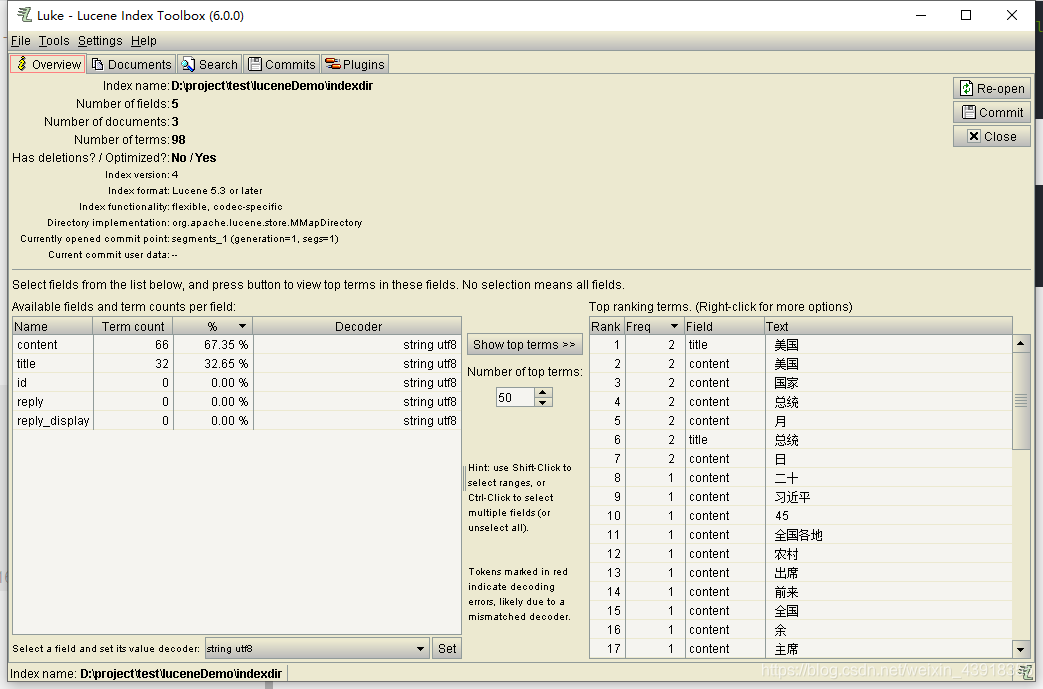
使用Luke工具查看索引内容














 1120
1120











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









