







ElasticSearch:基本概念及操作
文章目录
1:ElasticSearch简介
一言以蔽之:ElasticSearch 是同java开发(jvm内存管理)一款基于 Lucene(全文搜索) 的实时分布式搜索和分析引擎。
ElasticSearch 的目标是让全文搜索变 得简单,开发者可以通过它简单明了的 RestFul API 轻松地实现搜索功能
es官网
1.1:ES架构
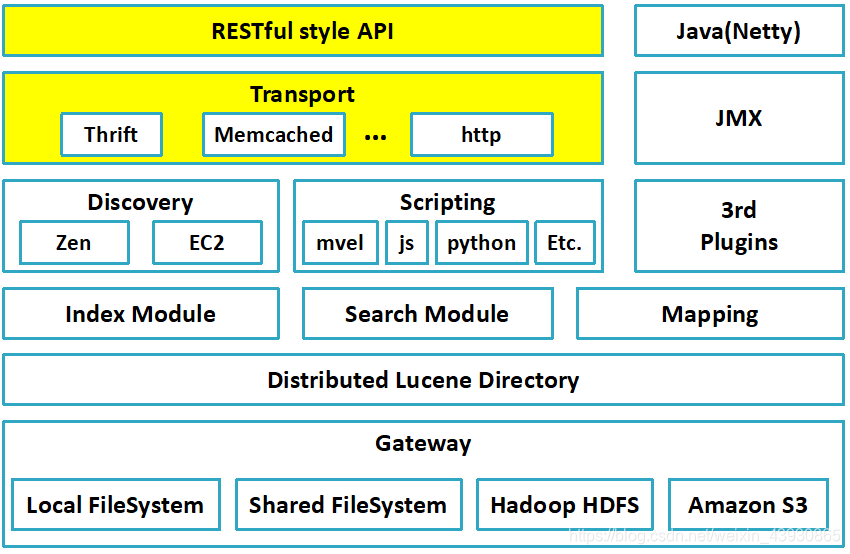
1.1:RestFul API 解释
- 1:其实说白了就是类似 HTTP 的访问,和 HTTP 非常的相似。
REST 操作:
GET:获取对象的当前状态;
PUT:改变对象的状态,插入;
POST:创建对象;
DELETE:删除对象;
HEAD:获取头信息
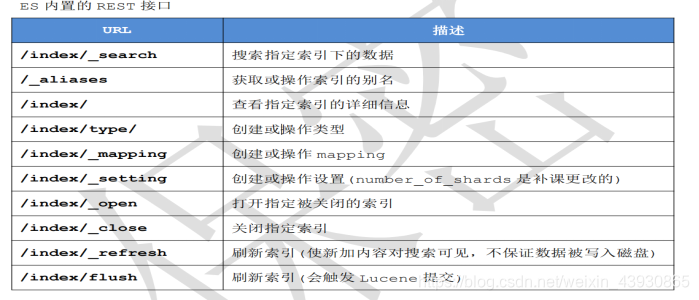
PUT 是幂等方法,POST 不是。所以 PUT 用户更新,POST 用于新增比较合适。 - 2:ES 内置的 REST 接口
1.2:gateway
- gateway 代表 ES 索引的存储方式,会存储索引,集群信息,mapping,setting等。ES 默认是先把索引存放到内存中,当内存满了时再 持久化到硬盘。当这个 ES 集群关闭在重新启动是就会从 gateway 中读取索引数据。Es 支 持多种类型的 gateway,有本地文件系统(默认),分布式文件系统,Hadoop 的 HDFS 和 amazon 的 s3 云存储服务。
1.3:Transport
- 提供Transport 客户端连接默认端口9200,用http,tcp等协议,如kibana连接。
1.4:Cluster
- Cluster 代表一个集群,集群中有多个节点,其中有一个为主节点master,其他为数据data节点,这个主节点是可以通过选举 产生的,主从节点是对于集群内部来说的。
1.1:master
- 集群中的一个节点会被选为master节点,它将负责管理集群范畴的变更,例如创建或删除索引,添加节点到集群或从集群删除节点,不负责查询和写入。根据集群规模一般会选择3-5各节点作为master节点。master无需参与文档层面的变更和搜索,这意味着仅有一个master节点并不会因流量增长而成为瓶颈。任意一个节点都可以成为 master 节点
1.2:data数据节点
- 存储数据和倒排索引,同时接受写入和搜索请求进行转发到其他分片,也可作为协调节点
1.3:协调节点ingest(client)
当主节点和数据节点配置都设置为false的时候,该节点只能处理路由请求,处理搜索(汇聚,排序,分页各节点结果),分发索引操作等,从本质上来说该客户节点表现为智能负载平衡器。
一般配置3台的服务器作为协调节点。
1.8:ZooKeeper集群
ZooKeeper为Elasticsearch集群中各进程提供心跳感应机制。
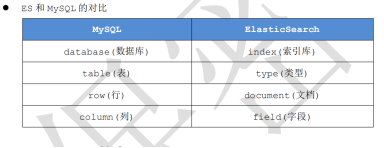
1.2:ES 和 MySQL 的对比
注意区别,es的文档就是一条json保存的数据,不要理解为文件的意思。es实际存储数据结构为json
稍后会对其中概念进行解释
2:es基本概念解释
elasticsearch存储架构设计
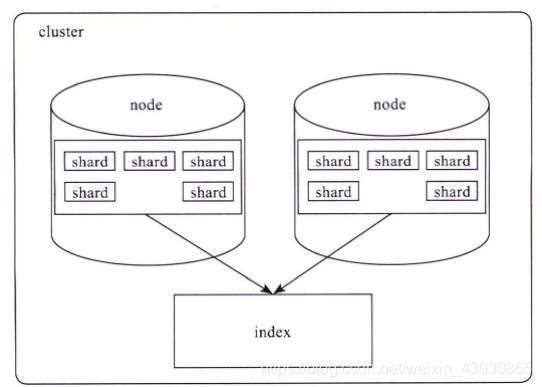
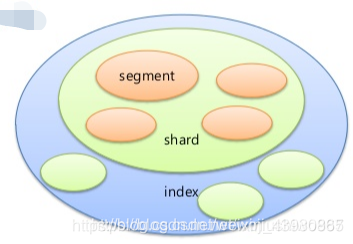
每个shard又由多个分段segment组成
索引index:一个拥有几分相似特征的文档的集合,类似于数据库的不同的库,索引库名称必须要全部小写,不能以下划线开头,也不能包含逗号,index索引都会保存在节点的内存中,所以注意索引过多引起的内存溢出现象,表现为cat/nodes的占用100%,
分片shard:一个索引被分为多个分片,每个分片本身就是一个完整的搜索块。文档存储在分片中,而分片则会被分配到集群中节点中,随着集群的扩大和缩小,es ES自动管理和组织分片,以保证集群能保持一种平衡,一个节点最大容纳分片500,每个分片最大30G,大于30G会严重影响读写速度。分片数的多少对集群性能的影响至关重要,一个索引由多个分片组成,默认创建为5个分片
分片在索引创建后便不能修改,所以一定要谨慎。每个分片本质上就是一个Lucene索引, 因此会消耗相应的文件句柄, 内存和CPU资源
replica副本:副本对搜索性能非常重要, 同时用户也可在任何时候添加或删除副本.。 额外的副本能给你带来更大的容量, 更高的呑吐能力及更强的故障恢复能力。副本分配不会和分片分到同一个节点上,这就是分布式,否则就失去了分布式的意义。
副本数可以修改
PUT /index/_settings { "number_of_replicas" : 2 }
gateway 代表 ES 索引的持久化存储方式,会存储索引,集群信息,mapping,setting等。ES 默认是先把索引存放到内存中,当内存满了时再 持久化到硬盘。当这个 ES 集群关闭在重新启动是就会从 gateway 中读取索引数据。Es 支 持多种类型的 gateway,有本地文件系统(默认),分布式文件系统,Hadoop 的 HDFS 和 amazon 的 s3 云存储服务。
类型type 每一批索引中,document有海量的,不同的document间有可能存在不同数量的相同结构的文档对象,利用type定义这批文档为同一种类型。类似于表格的一行的数据,可以自己随意定义类型,如记录网络数据,type可定义为5g/4g等,后续版本类型的定义会取消。
id 是一条数据的唯一标识符,如果没有明确指定索引数据的 ID,那么 es 会自动生成一个随机32位字母的 ID
字段域field 类似数据库的表格的字段
mapping 映射就是对索引库中索引的字段名及其数据类型进行定义。
文档document
在 Elasticsearch 中,术语 文档 有着特定的含义。它是指最顶层或者根对象, 这个根对象被序列化成 JSON 并存储到 Elasticsearch 中,指定了唯一 ID。
文档元数据:
文档元数据:一个文档不仅仅包含它的数据 ,也包含 元数据 —— 有关 文档的信息。 三个必须的元数据元素如下:
_index:文档在哪存放
_type:文档表示的对象类别
_id:文档唯一标识
segment段
每个分片包含多个“分段”,其中分段是倒排索引。
分段内的doc数量上限是2的31次方。
默认每秒都会生成一个segment文件.
在分片中搜索将依次搜索每个片段,然后将其结果合并到该分片的最终结果中。
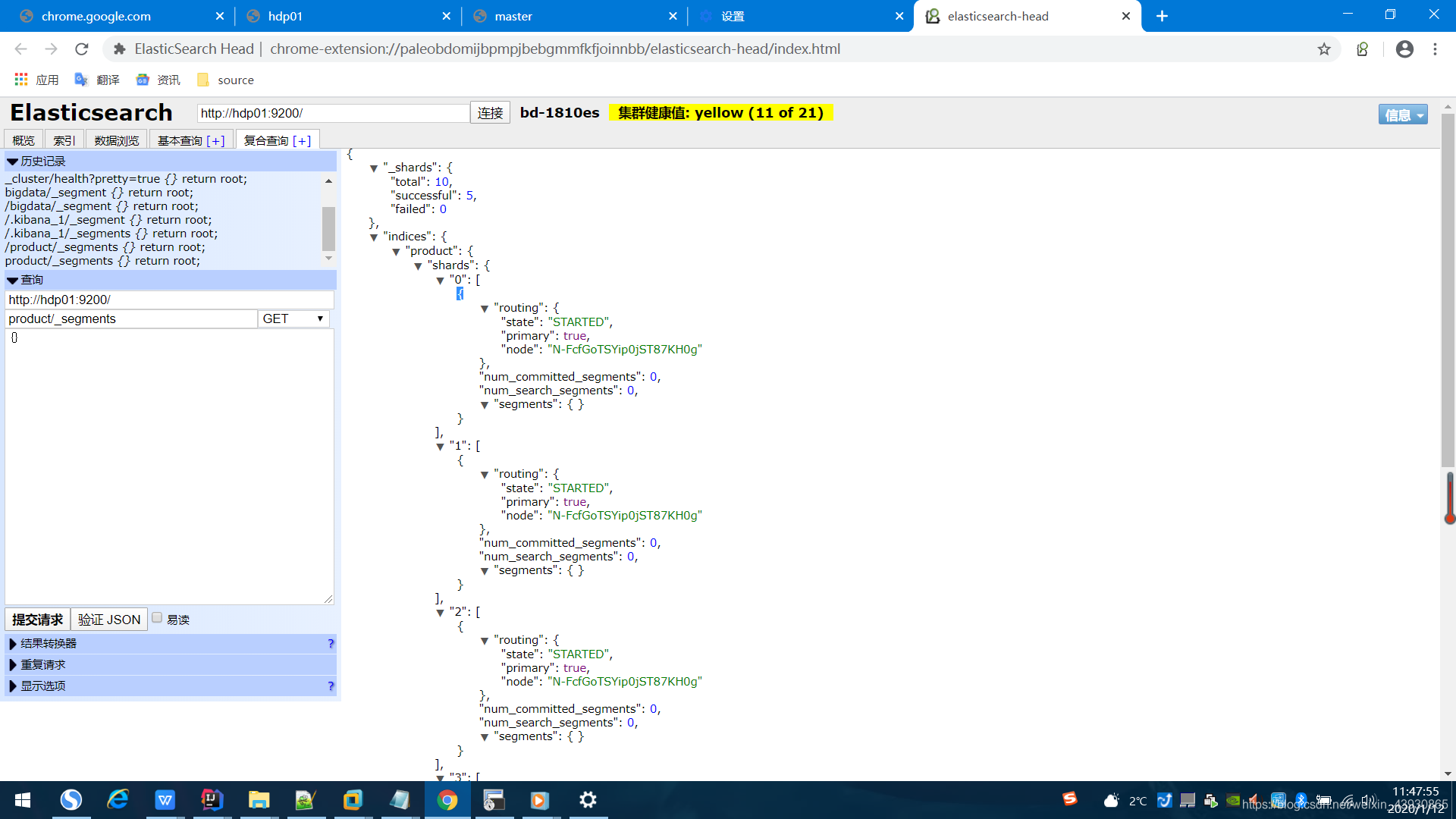
查看索引中分段信息的方法:
GET /test/_segments
该索引共5分片,查看segments
get index/_segments
3:集群安装升级
3.1:安装
1:集群规划
硬件配置:
- 硬盘以sas或者ssd固态硬盘优先;固态性能更高,可以做raid0或者raid1根据数据安全性进行设计,raid0性能更高。大小根据数据量计算。
- 内存越大越好;
- cpu2路8核以上。比如4路8核;服务器核数查看:cat /proc/cpuinfo |grep “processor”|sort -u|wc -l
节点规划:
- master:3台及以上,100台以上集群建议5个节点作为master
- data节点: = 规划数据量 * 1.5 (数据膨胀率) * 0.5(数据压缩率) * 1(1副本)/ 0.8(磁盘利用率) / 0.9 (磁盘进制转换)/ (5 (磁盘个数) * 600G (磁盘容量))
- ingest协调节点:建议3台及以上。
2:安装步骤
- 1:下载:https://www.elastic.co/cn/downloads/elasticsearch
- 2:解压到指定目录:tar -zxvf elasticsearch-6.5.2.tar.gz -C /app/
- 3:目录介绍:cd elasticsearch
home:Elasticsearch主目录或 $ES_HOME 通过解压缩存档创建的目录
bin:es的脚本存放目录,包括elasticsearch启停节点和elasticsearch-plugin安装插件脚本
conf:配置文件包括
elasticsearch.yml: 用于配置Elasticsearch
jvm.options: 用于配置Elasticsearch 的jvm
log4j2.properties 用于配置Elasticsearch日志记录
data:节点上分配的每个索引/分片的数据文件的位置。可以容纳多个位置
可以修改path.data配置项改变位置
logs:es服务的日志存放目录。可以通过path.logs修改位置
plugins:插件目录,每一个插件是一个字目录
- 4:修改配置文件
- 5:启动es:/bin/elasticsearch -d 后台运行
- 6:关闭jps查找进程号,kill -9 pid
单节点多实例模式:在同一个节点上部署多个Elasticsearch实例,根据IP和不同的端口号来区分不同的Elasticsearch实例。可以提高单节点CPU、内存和磁盘的利用率,同时提高Elasticsearch的索引和搜索能力
3:配置文件详解
3.1:elasticsearch.yml: 用于配置Elasticsearch
cluster.name: #指定一个集群名称,具有唯一性
node.name: "node1" #指定节点名,一般可以用主机名
node.master: true #指定该节点的角色是master,一般master节点不作为数据节点
node.data: true #指定该节点是否存储索引数据,默认为true。
设置node.master:false和node.data: false则该节点是协调节点
node.ingest #指定节点成为协调节点,只接受读请求进行转发,汇聚查询结果
index.number_of_shards: 5 #设置默认索引分片个数,默认为5片。
index.number_of_replicas: 1 #设置默认索引副本个数,默认为1个副本。
path.conf: /path/to/conf #设置es配置文件的存储路径,默认是es根目录下的config文件夹。
path.data: /path/to/data #设置索引数据的存储路径,默认是es根目录下的data文件夹,
可以设置多个路径,用逗号隔开如下面这种配置方式:
path.data: /path/to/data1,/path/to/data2
http.port: 9200 #指定es服务http访问的端口,默认9200
path.work: /path/to/work #设置临时文件的存储路径,默认是es根目录下的work文件夹。
path.logs: /path/to/logs #设置日志文件的存储路径,默认是es根目录下的logs文件夹
path.plugins: /path/to/plugins #设置插件的存放路径,默认是es根目录下的plugins文件夹
gateway.recover_after_nodes: 1 #设置集群中N个节点启动时进行数据恢复,默认为1。可设置-1,0,节点数间的任意值。推荐:0.8*节点数
gateway.recover_after_time: 5m #设置初始化数据恢复的等待时间,默认是5分钟,可修改为15m
gateway.expected_nodes: 2 #默认为2,一旦这N个节点启动,就会立即进行数据恢复。
bootstrap.mlockall: true #禁止内存和swap交换,降低性能
bootstrap.memory_lock: true #开启内存锁,默认true
2:jvm.options: 用于配置Elasticsearch 的jvm
两者不一致可能启动失败,其他配置基本不动,为什么最大不能超过32G,是关于jvm本身特性的(因为jvm只能对32G以下的数据自动进行压缩,保存存储空间的高效,超过32G就不启动压缩了,所以超过32G后实际存储的空间可能还没有31G多)。
-Xms1g #es服务堆内存的最小值,默认4g,根据服务器性能配置,推荐最大31G
-Xmx1g #es服务堆内存的最大值,默认4g,根据服务器性能配置,必须-Xms相等
3:log4j2.properties 用于配置Elasticsearch日志记录
设置日志文件的大小,滚动周期等的,一般不做修改
3.2:日志详解
日志存放目录是elasticsearch.yml中配置path.logs路径下
elasticsearch_cluster_deprecation.log #Elasticsearch弃用日志记录
elasticsearch_cluster_index_indexing_slowlog.log#Elasticsearch索引慢日志
elasticsearch_cluster_index_search_slowlog.log #Elasticsearch查询慢日志
elasticsearch_cluster.log #Elasticsearch集群日志
es-process-check.log #Elasticsearch健康检查日志
es-sevice-check.logq #Elasticsearch服务检查日志
es-start.log #Elasticsearch启动日志
es-stop.log #Elasticsearch停止日志
es-postinstall.log #Elasticsearch安装日志
es-gc.log #Elasticsearch实例垃圾回收日志
elasticsearch_cluster-audit.log #记录对索引级别的操作,比如迁移shard,删除索引等
3.2:集群滚动重启或停止流程
集群停止流程,停止业务后执行如下操作
- 1:停止索引写入
- :2:禁用分片分配。来避免启动时的分片重分配。
PUT _cluster/settings
{
"persistent": {
"cluster.routing.allocation.enable": "primaries"
}
}
- 3:强制刷新缓存,避免数据丢失:POST _flush/synced
- 4:停止数据节点:kill -9 pid
- 5:停止master节点
- 6:启动master后启动数据节点
- 7:开启分片重分配
PUT /_cluster/settings {
"transient" : {"cluster.routing.allocation.enable" : "all" }
}
4:端口
java开发端口:9300
http端口:9200
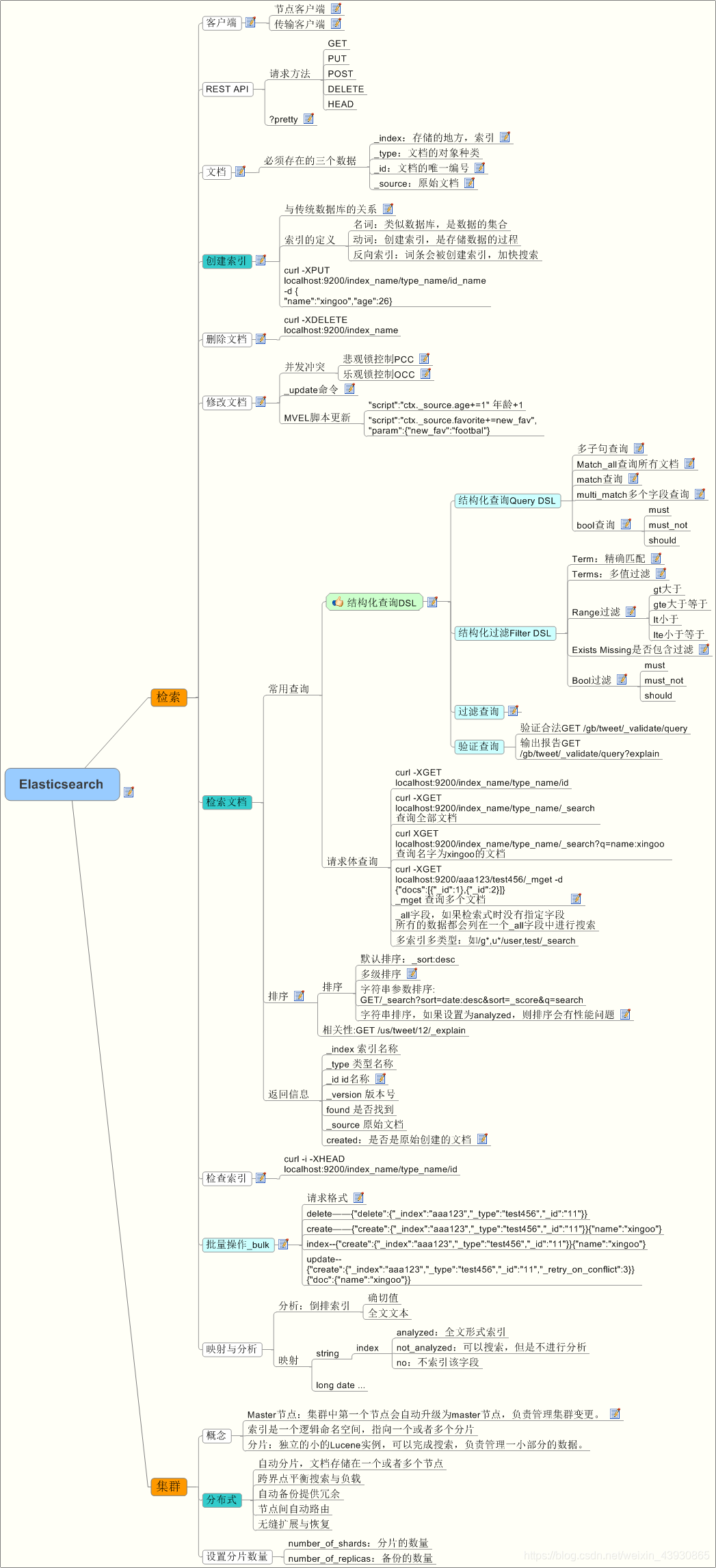
5:ES学习框架总图














 2139
2139











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









