







 本文深入探讨Elasticsearch中的Mapping配置,包括Setting和Mapping两大部分,重点介绍了字段属性、字段类型、分词器等内容,并给出了模板动态配置的具体示例。
本文深入探讨Elasticsearch中的Mapping配置,包括Setting和Mapping两大部分,重点介绍了字段属性、字段类型、分词器等内容,并给出了模板动态配置的具体示例。
文章目录
1:mapping详解
es官网mapping详解
一个索引的设置包括setting和mapping两部分,es的索引只存储需要检索排序聚合的字段,避免存储大量无效的字段及字段的mapping配置(index,doc_value,source,all)避免占用大量的存储空间,同时内存空间又比较小,导致内存segment缓存数据较少响应查询的速度
1:setting部分
是对索引的设置信息,更多参数信息看官网,示例如下
"settings": {
"number_of_shards": "1", 该索引的所有分片数,每个节点每GB堆空间的分片数量应该少于20个
"number_of_replicas": "0", 该索引的副本个数
"refresh_interval": "30s" 索引的段的刷新间隔
index.max_rescore_window:100000 默认为10000。搜索请求的一次最多返回的结果数
}
1.1:慢日志
官方慢日志文档
默认配置位置:es/config/log4j.properties中
日志输出日志:es_home/logs
慢日志默认是不开启的,通过定义具体动作(query,fetch 还是 index)和日志等级( WARN 、 DEBUG 等),以及时间阈值来开启。输出专用日志文件中,查询,插入的分片分配等详细过程查看,多用于问题定位等。
PUT /twitter/_settings
{
"index.search.slowlog.threshold.query.warn": "10s",
"index.search.slowlog.threshold.query.info": "5s",
"index.search.slowlog.threshold.query.debug": "2s",
"index.search.slowlog.threshold.query.trace": "500ms",
"index.search.slowlog.threshold.fetch.warn": "1s",
"index.search.slowlog.threshold.fetch.info": "800ms",
"index.search.slowlog.threshold.fetch.debug": "500ms",
"index.search.slowlog.threshold.fetch.trace": "200ms",
"index.search.slowlog.level": "info"
}
2:mappings部分
"mappings": {
"type_one": { 类型
"_all": { "enabled": false },
"properties": { 类型的字段定义
"uuid": {
"type": "string",
"index": "not_analyzed"
}
}
},
"type_two": { ... any mappings ... },
...
}
mapping架构分析:
每个索引包含多个类型,每个类型单独定义
2.1:字段的公共属性
_all字段和_source都是根据文档自动生成的,会占据存储空间,不过我们可以进行手动配置。
1:_all属性
ElasticSearch使用_all字段来综合存储其他多个字段的数据为一个整体以便于搜索,当然也可以设置只存储某几个字段到_all属性里面或者排除某些字段。如果不需要,请禁用该字段。
解释:控制全局搜索
它可以非常方便,特别是对于搜索请求,我们想对文档内容执行搜索查询,而不知道要搜索哪些字段。这是以牺牲CPU周期和索引大小为代价的。
可配合单个字段配置include_in_all使用,query_string和simple_query_string默认就是查询_all字段
2:_source
写入时:true开启mapping中的source会占用io和存储空间,get时默认会显示字段值。设置为false不支持reindexd重索引的API,查询时也不会显示字段值。不需要重索引和不查看字段值时可以禁用。
查询时:_source用于控制显示的,get搜索时为true显示的就是source中保存的内容。可以通过禁用source,此时不会去扫描索引,只返回id,提高查询速度。
true:get搜索时显示的就是source中保存的内容,会占用存储空间
flase:get时返回并不会显示原始数据,只返回id用于去habse查询的rowkey,提高查询速度,用于es+hbase架构。
如果仅仅需要考虑磁盘空间,请增加压缩级别而不是禁用source。
查询:
也可以查询时禁用source。
{
"_source": false,
"query": { }
}
2.2:写入或者读取时只配置某些字段
"_source":{
"includes":["field1","field2"] 只存储某些字段
"excludes":["field1","field2"] 可以通过excludes参数排除某些字段
},
2.2:properties:字段属性及类型定义
索引的类型的字段详细定义,类型等
示例:
"properties": {
"fields": { 字段名
"type": "string", 字段类型
"index": "not_analyzed"
}
}
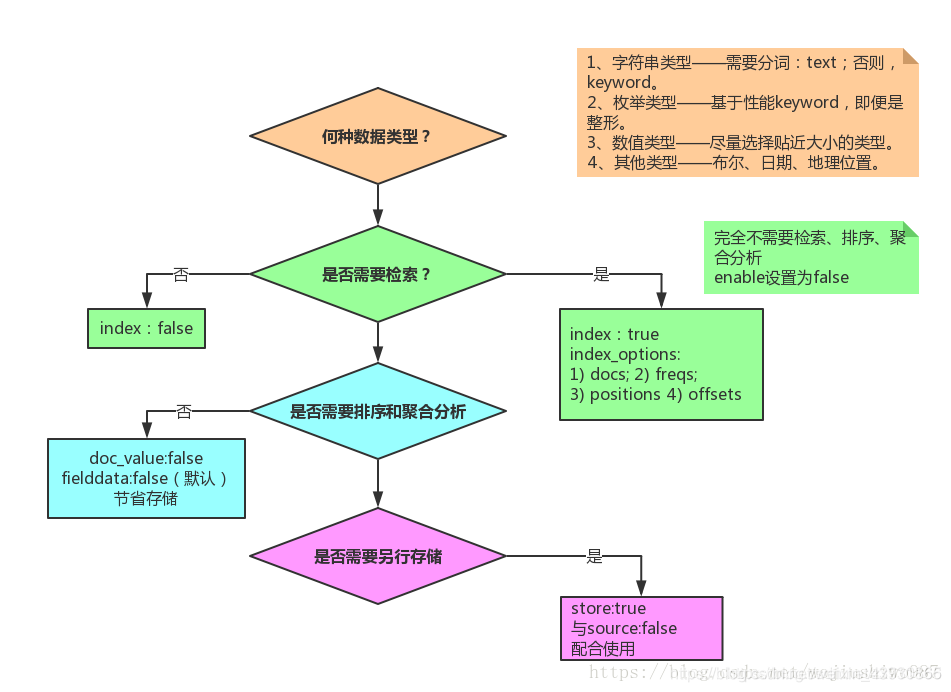
1:映射参数index,store,source的总结
store:决定是否该字段于source之外单独存储一份,可作为查询
index:决定构建倒排索引,是否可以作为请求体的搜索条件。
source:决定搜索请求时返回的原始数据是否会显示,并不会索引。
doc-value排序或聚合
1:字段属性详解
"fields name": {
"type": "text", //文本类型
"index": "analyzed"// 决定倒排索引的构建,控制在get/search请求时可不可用该字段作为请求体条件。分词器使用的是指定的字段或者索引的分词器。
analyzed:字段被索引,会做分词,可搜索。反过来,如果需要根据某个字段进搜索,index属性就应该设置为analyzed。
not_analyzed:字段值不分词,会被原样写入索引。反过来,如果某些字段需要完全匹配,比如人名、地名,index属性设置为not_analyzed为佳。
no:字段不写入索引,当然也就不能搜索。以该字段作为请求体时会报错。
"enabled" : true, #是否会被索引,但都会存储;可以针对一整个_doc
分词器是对text类型配置的,keyword不支持分词器
"analyzer" : "ik_max_word", #指定写入分词器,比如默认的空格分词器等
"search_analyzer" : "ik_max_word" , #查询时分词器;一般情况和analyzer对应
copy_to:将多个字段连接到一个字段中存储方便查询,他是复制字段中的值。查询时可以指定该字段查询
"copy_to" : "field_name", #自定义_all字段,
index_option:存储倒排索引的哪些信息
4个可选参数:
docs:索引文档号
freqs:文档号+词频
positions:文档号+词频+位置,通常用来距离查询
offsets:文档号+词频+位置+偏移量,通常被使用在高亮字段
分词字段默认是positions,其他默认时docs
"index_options": "docs"
"store":false//是否单独设置此字段的是否存储,于_source字段之外单独再存储一份,设置true时查询该字段从store获取值而不是source属性,查询更快
"boost":1/2/3 //字段级别的分数加权
"doc_values":false//对not_analyzed字段,默认都是开启,analyzed字段不能使用,排序聚合必须开启
对排序和聚合能提升较大性能,数据存储在磁盘中,不占用内存空间,不会oom。如果不需要对字段进行排序或聚合,或者从script访问字段值,
则可以禁用doc值以节省磁盘空间:如果需要排序,比如range查询则必须开启
"fielddata":{"loading" : "eager" }//es加载内存 fielddata 的默认行为是延迟加载 ,查询一次既被存储。占用内存的缓存空间,不存在磁盘中。
当 Elasticsearch 第一次查询某个字段时,它将会完整加载这个字段所有 Segment 中的倒排索引到内存中,
以便于以后的查询能够获取更好的性能。
"fields":{"keyword": {"type": "keyword","ignore_above": 256}} //可以对一个字段提供多种索引模式,同一个字段的值,一个分词,一个不分词
"ignore_above":100 //超过100个字符的文本,将会被忽略,不被索引
"include_in_all":ture//设置是否此字段包含在_all字段中,默认是true,除非index设置成no选项
"norms":{"enable":true,"loading":"lazy"}//分词字段默认配置,不分词字段:默认{"enable":false},
存储长度因子和索引时boost,建议对需要参与评分字段使用 ,会额外增加内存消耗量
"null_value":"NULL"//设置一些缺失字段的初始化值,只有string可以使用,分词字段的null值也会被分词
"position_increament_gap":0//影响距离查询或近似查询,可以设置在多值字段的数据上火分词字段上,查询时可指定slop间隔,默认值是100
"search_analyzer":"ik"//设置搜索时的分词器,默认跟ananlyzer是一致的,比如index时用standard+ngram,搜索时用standard用来完成自动提示功能
"similarity":"BM25"//默认是TF/IDF算法,指定一个字段评分策略,仅仅对字符串型和分词类型有效
"term_vector":"no"//默认不存储向量信息,支持参数yes(term存储),with_positions(term+位置),with_offsets(term+偏移量),
with_positions_offsets(term+位置+偏移量) 对快速高亮fast vector highlighter能提升性能,
但开启又会加大索引体积,不适合大数据量用
}
2:字段类型type
字符串类型 string,text,keyword,建议keyword。
text类型不支持排序,不用于聚合,结果不准确(默认fielddata=false,
聚合需要配合fielddata=true使用),支持字段分词器,将值分词再进行查找
keyword支持排序,但是结果不符合预期。查询不分词,将整个值进行查找
整数类型 integer,long,short,byte integer,long支持排序
浮点类型 double,float,half_float,scaled_float 注意浮点数进行range范围时的精度
逻辑类型 boolean
日期类型 date 支持排序
范围类型 range
二进制类型 binary
特殊类型 IP类型 ip,存储iPv4,ipv6地址
其他一些特殊类型:
复合类型 数组类型array,可存储多个值
对象类型 object
嵌套类型 nested
地理类型 地理坐标类型geo_point
地理地图 geo_shape
范围类型 completion
4:store
store属性用于指定是否将原始字段写入索引,于 _source 之外在独立(另外)存储一份,只用于搜索不支持查询。source和store的字段支持一个的才支持高亮显示。
如果一个字段的mapping中含有store属性为true,那么有一个单独的存储空间为这个字段做存储,
而且这个存储是独立于_source的存储的。它具有更快的查询。存储该字段会占用磁盘空间。
你可以指定一些字段store为true,这意味着这个field的数据将会被单独存储,搜索时单独从存储搜索,而不是source中,更快返回结果。
5:copy_to
copy_to的使用
1:使用示例
PUT myindex
{
"mappings": {
"mytype": {
"properties": {
"first_name": {
"type": "text",
"copy_to": "full_name"
},
"full_name": {
"type": "text"
}
}
}
}
}
#查询
GET myindex/_search
{
"query": {
"match": {
"full_name": "John Smith"
}
}
}
3:分词器
分词器包括字段级别以及更高层的类型(type)、索引(index)或节点(node)的配置,分词器决定了我们了查询时对语句的分割方式,影响我们查找的相关度和结果。
查询级别:es查询时优先级:先字段没有定义时再索引
常见分词器:not_analyzed 精准分析或者默认standard或者english 或者ik中文分词器或者icu分词器等等语种分词器
使用方式:一般为索引指定默认分词器,再为个别字段指定分析器去更好的搜索
指定字段分词器
"properties": {
"field-Name": {
"type": "string",
"analyzer": "english"
}
}
2:查看mapping
查看所有索引的mapping:
GET _mapping
指定索引查看mapping:
get index/_mapping
3:更新mapping
已创建的索引mapping不支持新增字段
2:template动态模板
咱们通常在elasticsearch中 post mapping信息,每重新创建索引便到设置mapping,分片,副本信息。非常繁琐。强烈建议大家通过设置template方式设置索引信息。
2.1:template解释
template大致分成setting和mappings两部分:
索引可使用预定义的模板进行创建,这个模板称作Index templates。
1. settings主要作用于index的一些相关配置信息,如分片数、副本数,tranlog同步条件、refresh等。
2. mappings主要是一些说明信息,大致又分为_all、_source、prpperties这三部分:
(1) _all:主要指的是AllField字段,我们可以将一个或多个都包含进来,在进行检索时无需指定字段的情况下检索多个字段。设置“_all" : {"enabled" : true}
(2) _source:主要指的是SourceField字段,Source可以理解为ES除了将数据保存在索引文件中,另外还有一份源数据。_source字段在我们进行检索时相当重要,如果在{"enabled" : false}情况下默认检索只会返回ID, 你需要通过Fields字段去到索引中去取数据,效率不是很高。但是enabled设置为true时,索引会比较大,这时可以通过Compress进行压缩和inclueds、excludes来在字段级别上进行一些限制,自定义哪些字段允许存储。
(3) properties:这是最重要的步骤,主要针对索引结构和字段级别上的一些设置。
3.设置索引名,通过正则匹配的方式匹配到相应的模板。
ps:直接修改mapping的优先级>索引template。索引匹配了多个template,当属性等配置出现不一致的,以order的最大值为准,order默认值为0
2.2:操作
查看模板 GET /_template/ttype_1
删除模板: DELETE /_template/type_1
创建模板: PUT _template
2.3:demo示例
PUT _template/a
{
"order": 0,
"index_patterns": [ //该模板的索引,支持正则匹配
"name1",
"name2*"
],
//1: settings
"settings": {
"index": {
"routing": {
"allocation": {
"total_shards_per_node": "4"
}
},
"mapping": {
"total_fields": {
"limit": "1000"
}
},
"refresh_interval": "30",
"translog": {
"flush_threshold_size": "5GB",
"sync_interval": "120s",
"durability": "async"
},
"max_result_window": "100000",
"max_slices_per_scroll": "5000",
"unassigned": {
"node_left": {
"delayed_timeout": "30m"
}
}
}
},
//2:mappings
"mappings": {
"mytype": {
"properties": {
"first_name": {
"type": "text",
"copy_to": "full_name"
},
"full_name": {
"type": "text"
}
}
}
},
"aliases": {}
}
3:字段属性总结
1:排序聚合
需要字段进行排序聚合必须开启"doc_values": true 而且字段类型应该是keyword类型,text类型聚合结果一般不正确
2:高亮显示
高亮显示store和source属性至少开启一个

















 734
734

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









