







1:消费者
消费者分为高级和简单两种消费者
高级:消费者组形式消费,更加简单高效
1:多线程消费者demo
可以使用shell命名消费topic
可以使用消费者组命令查看,监控工具也可以使用
./kafka-consumer-groups.sh --zookeeper hdp01:2181,hdp02:2181,hdp03:2181 --list
/kafka-consumer-groups.sh --zookeeper hdp01:2181,hdp02:2181,hdp03:2181 --group cons --describe
使用客户端消费
public class consumer {
private final ConsumerConnector consumer;
priate final String topic="spark01";
public consumer(){
Properties props = new Properties();
//zookeeper 配置,通过zk 可以负载均衡的获取broker
props.put("group.id", "cons");
props.put("enable.auto.commit", "true");
props.put("zookeeper.connect","hdp01:2181,hdp02:2181,hdp03:2181");
props.put("auto.commit.interval.ms", "1000");
props.put("partition.assignment.strategy", "Range");
props.put("auto.offset.reset", "smallest");
// props.put("zookeeper.connect","hdp01:2181,hdp02:2181,hdp03:2181");
/**指定键的反序列化方式*/
props.put("key.deserializer",
"org.apache.kafka.common.serialization.StringDeserializer");
/**指定值得反序列化方式*/
props.put("value.deserializer",
"org.apache.kafka.common.serialization.StringDeserializer");
//构建consumer connection 对象
consumer = Consumer.createJavaConsumerConnector(new ConsumerConfig(props));
}
public void consume(){
//指定需要订阅的topic
Map<String ,Integer> topicCountMap = new HashMap<String, Integer>();
//value值建议和partititon个数一样。指定featch消息的线程数,从而实现多线程获取消息,若此处value!=1,但是没有多线程featch,会造成正常运行但是消费不到消息的现象。具体看源码分析,会并行获取分区的消息
topicCountMap.put(topic, new Integer(numThreads));
//指定key的编码格式
Decoder<String> keyDecoder = new kafka.serializer.StringDecoder(new VerifiableProperties());
//指定value的编码格式
Decoder<String> valueDecoder = new kafka.serializer.StringDecoder(new VerifiableProperties());
//获取topic 和 接受到的stream 集合,针对每一个消费者线程创建一个BlockingQueue队列,队列中存储的
//是FetchedDataChunk数据块,每一个数据块中包括多条记录。
Map<String, List<KafkaStream<String, String>>> map = consumer.createMessageStreams(topicCountMap, keyDecoder, valueDecoder);
//根据指定的topic 获取 stream 集合
List<KafkaStream<String, String>> kafkaStreams = map.get(topic);
//创建多线程消费者kafkaStream,线程数和topicCountMap 中的value值必须保持一致。若value为1,则没有必要运行线程池创建多线程
ExecutorService executor = Executors.newFixedThreadPool(numThreads);
//因为是多个 message组成 message set , 所以要对stream 进行拆解遍历
for(final KafkaStream<String, String> kafkaStream : kafkaStreams){
//是否需要多线程根据topicCountMap 中的value值是否>1
executor.submit(new Runnable() {
@Override
public void run() {
//拆解每个的 stream,一般根据消费获取某几个分区的数据。
ConsumerIterator<String, String> iterator = kafkaStream.iterator();
while (iterator.hasNext()) {
//messageAndMetadata 包括了 message , topic , partition等metadata信息
MessageAndMetadata<String, String> messageAndMetadata = iterator.next();
System.out.println("message : " + messageAndMetadata.message() + " partition : " + messageAndMetadata.partition());
//偏移量管理:提交由此连接器连接的所有代理分区的偏移量。
consumer.commitOffsets();
}
}
});
}
}
public static void main(String[] args) {
new consumer().consume();
}
}
2:源码解析
先上汇总的流程图
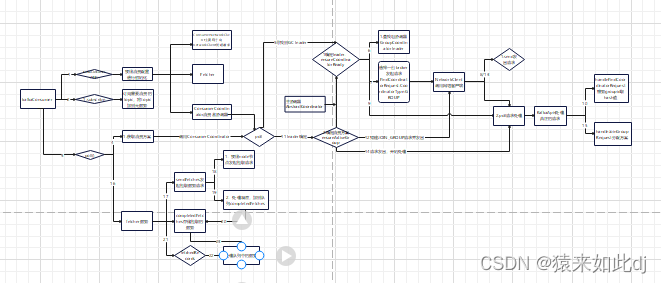
主要类介绍
KafkaConsumer 提供消费的客户端,提供topic订阅,消息拉取等功能
Fetcher 类的主要功能是发送Fetcher请求,获取指定消息集合,处理FetchResponse,更新消息位置。
ConsumerCoordinator 此类管理消费者与消费者协调器的协调过程,consumer消费分区的分配方案和自动提交偏移量的管理
1:消费数据时最终调用consumer.poll();发起消费的请求。
@Override
public ConsumerRecords<K, V> poll(long timeout) {
acquireAndEnsureOpen();// 获取锁,并确保消费者没有被关闭
try {
if (timeout < 0)
throw new IllegalArgumentException("Timeout must not be negative");
if (this.subscriptions.hasNoSubscriptionOrUserAssignment())
throw new IllegalStateException("Consumer is not subscribed to any topics or assigned any partitions");
//轮询拉取数据,直到超时
long start = time.milliseconds();
long remaining = timeout;
do {
// 实际执行抓取到数据,下面详细介绍 pollOnce 方法
Map<TopicPartition, List<ConsumerRecord<K, V>>> records = pollOnce(remaining);
if (!records.isEmpty()) {//已经拿到数据
// 有获取数据的请求或者 消费客户端有未完成的请求(这包括已经传输的请求(即飞行中的请求)和正在等待传输的请求。)
if (fetcher.sendFetches() > 0 || client.hasPendingRequests())
// 在返回获取的数据记录之前,我们可以发送下一轮获取请求,并避免在用户处理获取的记录时阻塞等待它们的响应以启用管道。
client.pollNoWakeup();
// 返回消费的数据记录,不过需要先由拦截器加工一下
return this.interceptors.onConsume(new ConsumerRecords<>(records));
}
long elapsed = time.milliseconds() - start;
remaining = timeout - elapsed;
} while (remaining > 0);// 只要没有超时,就一直循环消费数据
return ConsumerRecords.empty();
} finally {
release();
}
}
2:下面进入pollOnce(remaining);分析
private Map<TopicPartition, List<ConsumerRecord<K, V>>> pollOnce(long timeout) {
client.maybeTriggerWakeup();
long startMs = time.milliseconds();
//执行消费者的consumer和partition分区分配以及偏移量的自动提交(如果自动提交开启)
//选出consumer coordinator 的leader
1: coordinator.poll(startMs, timeout);
// Lookup positions of assigned partitions更新偏移量位置
boolean hasAllFetchPositions = updateFetchPositions();
// if data is available already, return it immediately
// 先从completedFetches获取一次数据,有数据直接返回,没有继续构造拉取数据的请求,首次肯定是空的
3: Map<TopicPartition, List<ConsumerRecord<K, V>>> records = fetcher.fetchedRecords();
if (!records.isEmpty())//如果数据不为空,则直接返回,为空的话开始拉取数据
return records;
// 发送新的读取请求(不会重新发送挂起的读取请求)
2: fetcher.sendFetches();
long nowMs = time.milliseconds();
long remainingTimeMs = Math.max(0, timeout - (nowMs - startMs));
long pollTimeout = Math.min(coordinator.timeToNextPoll(nowMs), remainingTimeMs);
// We do not want to be stuck blocking in poll if we are missing some positions
// 要避免重复扫描poll()中的订阅,判断是否在元数据更新期间缓存结果
if (!hasAllFetchPositions && pollTimeout > retryBackoffMs)
pollTimeout = retryBackoffMs;
// 调用客户端发起
client.poll(pollTimeout, nowMs, new PollCondition() {
@Override
public boolean shouldBlock() {
// since a fetch might be completed by the background thread, we need this poll condition
// to ensure that we do not block unnecessarily in poll()
return !fetcher.hasCompletedFetches();
}
});
// 在长时间的获取数据之后,我们应该在返回数据之前检查一下这个群体是否需要重新平衡,以便这个群体能够更快地稳定下来
//判断什么时候执行relance
if (coordinator.needRejoin())
return Collections.emptyMap();
return fetcher.fetchedRecords();
}
2.1:消费者和分区的消费订阅关系在① coordinator.poll(startMs, timeout);处实现。
此处源码分析详见:(5.4)kafka消费者源码——ConsumerCoordinator类和GroupCoordinator类
2.2:订阅关系确定后开始拉取数据消费:fetcher.sendFetches();
public int sendFetches() {
// 定义一个节点和请求数据的map集合,存储节点和节点的连接会话
// 所有节点创建获取请求,我们为这些节点分配了分区,这些分区没有正在运行的现有请求。
Map<Node, FetchSessionHandler.FetchRequestData> fetchRequestMap = prepareFetchRequests();
for (Map.Entry<Node, FetchSessionHandler.FetchRequestData> entry : fetchRequestMap.entrySet()) {
//获取节点
final Node fetchTarget = entry.getKey();
// 获取和节点的连接会话
final FetchSessionHandler.FetchRequestData data = entry.getValue();
// 根据连接会话创建一个获取数据的请求
final FetchRequest.Builder request = FetchRequest.Builder
.forConsumer(this.maxWaitMs, this.minBytes, data.toSend())
.isolationLevel(isolationLevel)
.setMaxBytes(this.maxBytes) //一次拉取的最大字节数50M
.metadata(data.metadata())
.toForget(data.toForget());
if (log.isDebugEnabled()) {
log.debug("Sending {} {} to broker {}", isolationLevel, data.toString(), fetchTarget);
}
//把发往每个Node的FetchRequest都缓存到unsent队列上
client.send(fetchTarget, request) //添加Listener监听,这也是处理FetchResponse的入口
.addListener(new RequestFutureListener<ClientResponse>() {
@Override
public void onSuccess(ClientResponse resp) { //请求成功了,处理返回的响应
FetchResponse response = (FetchResponse) resp.responseBody();
FetchSessionHandler handler = sessionHandlers.get(fetchTarget.id());
if (handler == null) {
log.error("Unable to find FetchSessionHandler for node {}. Ignoring fetch response.",
fetchTarget.id());
return;
}
if (!handler.handleResponse(response)) {
return;
}
// 获取响应数据的主题分区对象,放入set集合中
Set<TopicPartition> partitions = new HashSet<>(response.responseData().keySet());
// 这是静态内部类
FetchResponseMetricAggregator metricAggregator = new FetchResponseMetricAggregator(sensors, partitions);
//遍历响应中的数据
for (Map.Entry<TopicPartition, FetchResponse.PartitionData> entry : response.responseData().entrySet()) {
//获取分区
TopicPartition partition = entry.getKey();
// 获取偏移量
long fetchOffset = data.sessionPartitions().get(partition).fetchOffset;
// 获取分区数据,里面包括消费的数据
FetchResponse.PartitionData fetchData = entry.getValue();
log.debug("Fetch {} at offset {} for partition {} returned fetch data {}",
isolationLevel, fetchOffset, partition, fetchData);
//创建completedFetch,把拉取完成数据缓存到completedFetch队列中
completedFetches.add(new CompletedFetch(partition, fetchOffset, fetchData, metricAggregator,
resp.requestHeader().apiVersion()));
}
sensors.fetchLatency.record(resp.requestLatencyMs());
}
@Override
public void onFailure(RuntimeException e) {
FetchSessionHandler handler = sessionHandlers.get(fetchTarget.id());
if (handler != null) {
handler.handleError(e); /*异常处理*/
}
}
});
}
return fetchRequestMap.size();
}
2.3:拉取到消息放到队列中开始处理② Map<TopicPartition, List<ConsumerRecord<K, V>>> records = fetcher.fetchedRecords();
public Map<TopicPartition, List<ConsumerRecord<K, V>>> fetchedRecords() {
// 定义一个消费的主题分区和数据map集合
Map<TopicPartition, List<ConsumerRecord<K, V>>> fetched = new HashMap<>();
int recordsRemaining = maxPollRecords; //记录剩余可拉取的记录条数,每拉取一次被更新一次
try {
while (recordsRemaining > 0) {// 只要记录数大于0,就继续拉取
if (nextInLineRecords == null || nextInLineRecords.isFetched) {// 判断分区记录是否为空或者它是否被获取过
// 获取但不删除队列的头元素,判断是否有过拉取,
CompletedFetch completedFetch = completedFetches.peek();
if (completedFetch == null) break;
//解析一个completedFetches得到一个PartitionRecords对象。记录那个分区,获取了多少记录,偏移量是多少
nextInLineRecords = parseCompletedFetch(completedFetch);
completedFetches.poll();//poll是从队列取出元素并且删除该元素
} else {// 获取消费数据集
List<ConsumerRecord<K, V>> records = fetchRecords(nextInLineRecords, recordsRemaining);
TopicPartition partition = nextInLineRecords.partition;// 获取主题分区
if (!records.isEmpty()) {
List<ConsumerRecord<K, V>> currentRecords = fetched.get(partition);
if (currentRecords == null) {
fetched.put(partition, records);
} else {
// this case shouldn't usually happen because we only send one fetch at a time per partition,
// but it might conceivably happen in some rare cases (such as partition leader changes).
// we have to copy to a new list because the old one may be immutable
List<ConsumerRecord<K, V>> newRecords = new ArrayList<>(records.size() + currentRecords.size());
newRecords.addAll(currentRecords);
newRecords.addAll(records);
fetched.put(partition, newRecords);
}
// 可消费的剩下数据条数减去刚才消费到的数据集的大小
recordsRemaining -= records.size();
}
}
}
} catch (KafkaException e) {
if (fetched.isEmpty())
throw e;
}
return fetched;
}
2:消费者相关参数配置
- group.id 标识消费唯一的字符串
- max.poll.records 单次poll请求的最大条数,默认500
- max.poll.interval.ms 两次poll请求的最大时间间隔,,若在该实际内消费处理不完会触发reblance,默认
- session.timeout.ms 请求发出后等待响应的最大会话时长,和heartbeat.interval.ms参数相关。
- heartbeat.interval.ms 消费者多久发送一次心跳给groupcCoordinator,
心跳次数=session.timeout.ms/heartbeat.interval.ms - fetch.max.bytes向一个node发起一次fetch请求时最大可拉取的字节数,默认50M
- fetch.min.bytes 向一个node发起一次fetch请求时最小可拉取的字节数,默认0
- partition.assignment.strategy 消费者分区订阅算法,默认轮询
- enable.auto.commit 是否自动提交偏移量















 925
925











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









