






论文链接:https://arxiv.org/pdf/2111.06377.pdf
论文作者:Kaiming He Xinlei Chen Saining Xie Yanghao Li Piotr Dolla ́r Ross Girshick
Abstract
论文展示的遮掩自编码器(masked autoencoders, MAE)是一种用于计算机视觉的可扩展的自监督学习器。MAE的方法很简单:对输入图像的随机碎片进行掩蔽,再重建缺失的像素。
基于两个核心设计:
- 不对称的encoder-decoder架构,一个encoder只对可见的碎片子集进行操作(没有mask tokens);以及一个轻量级的decoder从潜在表示和mask tokens重建原始图像
- 掩蔽大部分输入图像(例如,75%)会产生重要且有意义的自监督任务
结合以上的两个设计,我们能高效地训练大型模型:加速训练(3倍或更多)并提高准确率。我们可扩展的方法允许学习泛化性更好的高容量模型,例如,在仅使用ImageNet-1K数据的方法中,vanilla ViT-Huge模型实现了最佳准确率(87.8%)。下游任务中的迁移性能优于有监督的预训练,并展示出有希望扩展的行为。
1. Introduction
深度学习见证了不断增长的能力和容量的架构的爆炸性增长。由于硬件的快速增长,如今的模型很容易过拟合一百万张图像,并开始需要数亿张标记图像(通常是无法公开访问的)。
这种数据需求已经通过自监督预训练在自然语言处理中成功解决。这种基于GPT的自回归语言模型和BERT中的遮蔽自编码的解决方案在概念上很简单:它们移除了一定比例的数据,并学习预测移除的内容。这些方法现在能用于训练包含了超过一千亿参数的可泛化的NLP模型。
掩蔽自编码器这种思想,一种更通用的去噪自编码器,是自然的,也适用于计算机视觉。实际上,视觉上与其密切相关的研究先于BERT,但是视觉中的自编码方法的进展落后于NLP。
问题:是什么使得视觉和语言之间的掩蔽自编码(MAE)不同?
本论文试图从三方面回答这个问题:
- 架构不同。在视觉中,卷积网络在过去十年中占领主导地位。卷积通常是在规则的网格上进行的,将例如掩码标记(mask tokens)或者位置嵌入(positional embeddings)之类的“指标”集成到卷积网络中是很不容易的。然而,架构上的差距由于**Vision Transformer(ViT)**的出现已经被解决了,目前已经不是再是困难。
- 语言和视觉之间的信息密度不同。语言是一种由人生成的高度语义和高信息密度的信号。当我们训练模型来对每个句子只预测缺失的几个单词时,这样的任务会导致复杂的语言理解。而图像则相反,是一种由大量空间冗余的自然信号,例如,一个缺失的碎片可以在对部分、对象和场景都没有什么高级理解时由邻近的碎片恢复。为了克服这种差距,并鼓励学习有用的特征,我们使用了一个简单的策略,在计算机视觉中效果很好:掩蔽很大一部分的随机碎片。这种策略很大程度上减少了冗余度并且创造了一个具有挑战性的自适应任务 – 需要超越低级图像统计的整体理解。为了对重构任务有定性的认识,看Figures2-4。


- 自编码解码器,将潜在表示映射回输入,在重构文本和图像时,扮演不同的角色。在视觉中,解码器重构的是像素,因此其输出的语义级别低于常见的识别任务。这在语言中是截然相反的,解码器预测的是包含了丰富语义信息的缺失单词。虽然在BERT中,解码器可能很简单(MLP),但我们发现,对于图像,解码器设计在确定学习到的潜在表示的语义级别上起着关键作用。
经过分析,我们提出了一个简单,有效并且可扩展的掩蔽自编码器(MAE)形式,用于视觉表示学习。我们的MAE从输入图像中遮蔽随机的碎片并在像素空间上重构这些缺失的碎片。它拥有一个非对称的encoder-decoder设计。我们的编码器仅在可见的碎片子集上进行操作(没有掩码标记),我们的轻量级的decoder从潜在表示和mask tokens重建原始图像。如下图:

在我们的非对称encoder-decoder中,将掩码标记转移到小型解码器上会导致计算量大幅减少。在这种设计下,一个非常高的掩码比例(例如,75%)可以获得一个双赢的情景:它优化了准确率,同时允许编码器在很小比例(例如,25%)的碎片上进行处理。这可以减少预训练时间(3倍或更多)和内存消耗,能轻松地将MAE扩展到大型模型中。
我们的MAE学习非常高容量的模型,这些模型可以很好的泛化。通过MAE预训练,我们可以在ImageNet-1K上训练数据密集型模型,如ViT-Large/-Huge,并提高泛化性能。使用普通的ViT-Huge模型,我们在ImageNet-1K上微调得到87.8%的准确率。这超过了之前仅使用ImageNet-1K数据的所有结果。我们也在目标检测、实例分割、语义分割上评估了迁移学习。在这些任务中,我们的预训练得到了比其有监督预训练更好的结果。更重要的是,我们通过扩大模型观察到了显著的收益。这些观察结果与NLP中自监督预训练中的观察结果一致。我们希望它们将使我们的领域探索类似的轨迹。
2. Related Work
略
3.Approch
我们的掩蔽自编码器(MAE)是一个简单的自编码方法,由给出的部分观察重构原始的信号。与所有自编码器相比:
- 相同点:我们的方法有一个将观察到的信号映射到潜在表示的编码器,以及一个将潜在表示重构为原始信号的解码器。
- 不同点:我们采用了不对称的设计,允许编码器仅对部分,可观察到的信号(没有掩码标记)进行操作,并采用轻量级的解码器从潜在表示和掩码标记重构完整信号。
Masking
遵循ViT,我们将图片分割成规则不重叠的碎片,然后我们对碎片的子集进行采样并将剩下的部分掩蔽起来(例如,移除)。我们的采样策略很直接:我们按照均匀分布,不替换的对随机碎片进行采样。我们简单的称其为“随机采样”。
以一个高的掩蔽比例进行随机采样极大的减少了冗余度,因此创建了不能轻易的通过从可见的相邻块外推来解决的任务。均匀分布避免了潜在的中心偏差(例如,更多的掩码碎片在图像中心附近)。最后,高度稀疏的输入创造了一个设计高效编码器的机会。
MAE encoder
我们的编码器是一个ViT,但是仅作用在可见的,未被掩蔽的碎片上。正如标准ViT,我们的编码器通过添加位置嵌入的线性投影嵌入碎片,然后通过一系列Transformer块处理结果集。然而,饿哦吗的编码器仅作用在全集的一个很小的子集(例如,25%)上。掩蔽的碎片被移除了,不使用掩码标记。这是的我们能仅使用一小部分计算和内存来训练非常大的编码器。全集有轻量级的解码器处理,描述如下。
MAE decoder
MAE解码器的输入是tokens的全集,包括(i)编码的可见碎片和(ii)掩码标记。每个掩码标记都是一个共享的学习向量,指示是否存在需要预测的缺失碎片。我们对全集中的所有tokens添加了位置嵌入;如果没有这个,掩码标记将没有关于它们在图像中位置的信息。解码器有另一系列的Transformer块。
MAE解码器仅在预训练期间用于执行图像重构任务(仅使用编码器生成用于识别的图像表示)。因此,可以以独立于编码器设计的方式灵活地设计解码器架构。我们用非常小的解码器进行实验,比编码器更窄更浅。例如,我们的默认解码器与编码器相比每个token只有不到10%的计算量。由于这种不对称的设计,tokens的全集仅被轻量级的解码器处理,极大的减少了预训练时间。
Reconstruction target
我们的MAE通过预测每个掩码碎片的像素值来重构输入,解码器输出中的每个元素都是一个表示碎片的像素值向量。解码器的最后一层是线性投影,它的输出通道数量等同于碎片的像素值数量。解码器的输出被重新整形以形成重构的图像。我们的损失函数计算在像素空间上重构的和原始图像之间的均方误差(MSE)。与BERT类似,我们仅在掩码碎片上计算损失。
我们也研究了一个变体,它的重构目标是每个掩码碎片的归一化像素值。特别地,我们计算了一个碎片的所有像素的均值和标准差,并使用它们来标准化这个碎片。在我们的实验中,使用归一化像素作为重构目标可以提高表示的质量。
Simple implementation
我们的MAE预训练可以被有效地实施,重要的是,不需要任何专门的稀疏操作。首先,我们为每个输入碎片生成一个token(通过添加了位置嵌入的线性投影)。然后,我们基于掩蔽率,随机shuffle tokens列表并删除列表中的最后一部分。这个过程为编码器生成了一部分tokens,相当于在没有替换的情况下采样碎片。在编码之后,我们将一个掩码标记列表附加到编码碎片列表中,并unshuffle这个完整的列表(反转随机shuffle操作)以将所有token是与其目标对齐,这个解码器作用在整个列表上(添加上位置嵌入)。如上所述,不需要稀疏操作,这个简单的实现引入的开销可以忽略不计,因为shuffle和unshuffle操作很快。
4. ImageNet Experiments
我们在ImageNet-1K训练集上进行自监督预训练,然后使用(i)端到端的微调或(ii)线性探测进行有监督训练评估表示。我们报告了单个224*224裁剪的top-1验证精度。
Baseline:ViT-Large. 我们使用ViT-Large(ViT-L/16)作为我们消融研究的支柱,ViT-L非常大(比ResNet-50大一个数量级)并且容易过拟合。下面是从头开始训练的ViT-L与我们的baselineMAE微调的比较:
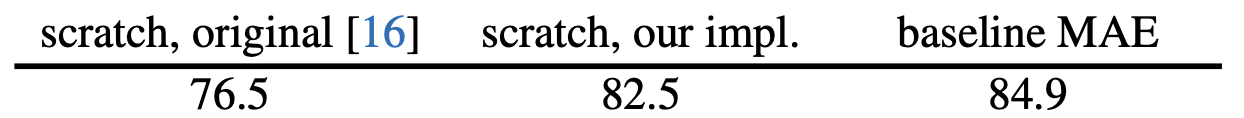
我们注意到从头开始训练有监督的ViT-L是很重要的,并且需要一个具有强正则化的good recipe(82.5%)。经过如此,我们MAE预训练贡献了一个很大的进步。此处,微调仅针对50个epoch(而从头开始训练是200个),这一位置微调精度在很大程度上取决于预训练。
4.1. Main Properties
我们使用表1中的默认设置切除我们的MAE,观察到几个有趣的特性:
Masking ratio 下图展示了masking ratio的影响。
最优的比率超乎想象的高,75%在线性探测和微调上表现的都很好。这种表现在BERT上正好相反,典型的掩蔽率是15%。与计算机视觉中的相关工作相比,我们的掩蔽率也高出了很多(20%-50%)。
该模型推断(infer)缺失的碎片来产生不同但是合理的输出。它可以理解为对象和场景的完形,这不能简单地通过延长线条或纹理来完成。我们假设这种类似推理的行为与有用表征的学习有关。
上图(Figure 5)也表明了线性探测和微调的结果有不同的趋势。对于线性探测,准确率随着掩蔽率逐步增加直到the sweet point:准确率差距高达20%(54.6% vs. 73.5%)。对于微调,结果对比率并不是太敏感,并且在很宽范围的掩蔽比率(40%-80%)上的效果很好。所有微调结果都优于从头开始训练(82.5%)
Decoder design 我们的MAE解码器可以灵活的设计,如表1a和1b。
Table 1a改变了解码器的深度(Transformer块的数量)。一个足够深的解码器对线性探测是很重要的。这可以通过像素重构任务和识别任务之间的差距解释:自编码器的最后几层更针对重构,但与识别的相关性更小。一个合理深度的解码器可以解释重构的专业化,将潜在表示留在更抽象的层次上。这种设计可使线性探测提高8%(Table 1a, ‘lin’)。但是,如果使用微调,则可以调整编码器的最后几层以适应识别任务,解码器深度对改进的微调的影响较小(Table 1b, ‘ft’)。
有趣的是,我们的带有单块解码器的MAE可以通过微调表现的很好(84.8%)。请注意,单个Transformer块是将信息从可见标记传播到掩码标记的最低要求,这么小的解码器可以进一步加快训练速度。
在Table 1b中,我们研究了解码器的宽度(通道数量)。我们使用默认的512-d,这个维度在线性探测和微调下都表现的很好。一个微调的窄解码器也表现的很好。
总的来说,我们默认的MAE解码器是轻量级的,它有8个块,宽度为512-d。与ViT-L(24个块,1024-d)相比,每个token仅有9%的FLOPs。因此,虽然解码器处理了所有的tokens,但它仍然是整体计算的一小部分。
Mask token 我们的MAE的一个重要设计是在编码器上跳过了掩码标记并在之后将其应用在轻量级的解码器上,Table 1c研究了这个设计。
如果编码器使用了掩码标记,将表现的更差:在线性探测中,它的准确率下降了14%。在这种情况下,预训练和部署之间存在差距:该编码器在预训练的输入中有很大一部分都是掩码标记,这在未损坏的图像中是不存在的。这种差距可能会降低部署的准确性。通过从编码器中移除掩码标记,我们限制编码器始终看到真实的碎片,从而提高准确率。
此外,通过跳过编码器中的掩码标记,大大减少了训练计算量。在Table 1c中,我们将整体训练FLOPs减少了3.3倍。这使得我们实现中的wall-clock加速了2.8倍。对于较小的解码器(1块)、较大的编码器(Vi-H)或者两者都有,wall-clock加速甚至更大(3.5-4.1倍)。特别是对于75%的掩蔽率,加速可以超过4倍,一部分的原因是因为自注意力复杂度是二次的。此外,内存也大大减少,这可以训练更大的模型或者通过大批量的训练加快速度。时间和内存的高效使我们的MAE有利于训练非常大的模型。
Reconstruction target 我们在Table 1d上比较了不同的重构目标。到目前为止,我们的结果基于没有归一化(每个碎片)的像素,使用归一化像素可以提高准确性。这种逐块归一化在局部增强了对比度。在另一个变体中,我们的碎片空间中执行PCA并使用最大的PCA系数(此处为96)作为目标,这样做会降低准确性。两个实验都表明高频分量在我们的方法中很有用。
我们也比较了一个用于预测tokens的MAE变体,即BEiT中使用的目标。特别是对于这个变体,我们使用DALLE预训练的dVAE作为分词器,如下。这里MAE解码器使用交叉熵损失预测token索引。这种分词器与非标准化像素相比将微调精度提高了0.4%,但是与标准化像素相比没有优势。它还降低了线性探测的准确率。在第五节中,我们会进一步展示在迁移学习中分词器不是必需的。
我们基于像素的MAE相比于分词器简单很多。dVAE分词器需要一个额外的预训练阶段,这可能取决于额外的数据(250M图像)。dVAE编码器是一个大型卷积网络并增加了非平凡的开销(ViT-L的40%FLOPs),使用像素不会遇到这些问题。
Data augmentation 在MAE预训练中,Table 1e研究了数据增强的影响。
我们的MAE使用仅裁剪的增加方法效果很好,无论是固定尺寸还是随机尺寸(都具有随机水平翻转)。添加颜色抖动会降低结果,因此我们不会在其他实验中使用它。
令人惊讶的是,即使没有使用数据增强(只有中心裁剪,没有反转),我们的MAE也表现的很好。这一特性与严重依赖数据增强的对比学习和相关方法截然不同。根据观察,对于BYOL和SimCLR,使用仅裁剪增强分别降低了13%和28%的准确率。此外,没有证据表明对比学习可以在没有增强的情况下工作:一个图像的两个视图是相同的,可以很容易地满足一个简单的解决方案。
在MAE中,数据增强的角色主要表现为随机掩蔽(在后面进行分割)。每次迭代的masks都不同,因此无论数据增强如何,它们都会生成新的训练样本。掩蔽使得pretext任务变得困难,并且需要较少的增强来规范训练。
Mask sampling strategy 在Table 1f中,我们比较了不同的掩蔽采样策略,如下图所示。
BEiT提出的块级别掩蔽策略倾向于移除较大的块,如上图中间所示。我们的块级掩蔽MAE在50%的比率下表现的很好,但在75%的比率下性能下降。这项任务比随机采样更难,因为观察到更高的训练损失,重构也更模糊。
我们也研究了网格级采样,规则的保留了每四个碎片的一个(如上图右侧)。这是一个更简单的任务并且有更低的训练损失。重构更清晰,但是表示的质量较低。
简单的随机采样工作最适合我们的MAE。它允许一个更高的掩蔽率,提供了更大的加速优势,同时有良好的准确率。
Training schedule 目前为止,我们的分割基于800-epoch的预训练,下图展示了训练时间(training schedule)长度的影响。更长的训练持续的提高了准确率。实际上,即使在1600-epoch,我们也没有观察到线性探测的准确率饱和。这种行为与对比学习方法是不同的,例如,MoCo v3在ViT-L的300-epoch时饱和。值得注意的是,MAE的编码器在每个epoch只能看到25%的碎片,而在对比学习中,编码器在每个epoch上能看到200%(两次裁剪)甚至更多(多次裁剪)的碎片。
















 7341
7341











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









