








MySQL优化主要体现在几个方面
- 设计:存储引擎,字段选择,范式与反范式
- 功能:索引,缓存,分区分表
- 架构:主从复制,读写分离,负载均衡
设计方面
一、存储引擎
MySQL >= 5.5 版本默认的存储引擎是InnoDB。
- InnoDB的数据存储在表空间内,由一系列数据文件组成。
- InnoDB采用多版本控制机制(MVCC)来支持高并发,并且实现了四个隔离级别。其默认隔离级别为REPETABLE READ(可重复读),并且通过间隙锁策略防止幻读(读未提交)的出现。
- InnoDB是基于聚簇索引建立的
- 支持事务
- 具有自动崩溃恢复功能
- 支持外键
InnoDB的表空间分为:独立表空间、共享表空间。
独立表空间:每个表都会生成独立的文件方式来存储,每个表都有一个 .frm 的描述文件, 还有一个 .ibd 文件。其中这个文件包括单独的一个表的数据及索引内容,默认情况下它的存储在var/lib/mydb目录下。
优点:
每个表都有自己独立的表空间,可以实现单表的迁移;表空间可以回收(使用drop table操作),drop table操作自动回收表空间;删除大量数据后可以使用alter table table_name engin=innodb进行回收不用的空间;也可以使用truntcate table进行空间收缩;对于使用独立表空间,不管怎么删除表空间的碎片都不会太严重。
缺点:
单表增加过大,如超过100G。使用共享表空间将文件分开,但是对于查询范围太大同样访问文件过多的话,依旧很慢;对于独立表空间的解决办法是:使用分区表,将大的表空间移动到别的空间上建立一个连接。
共享表空间:某一个数据库的所有表数据,索引存储在一个文件中。
优点:
可以将表空间分成多个文件存储在各个磁盘中(表空间文件大小不受表大小的限制)
缺点:
所有的数据和索引存储一个文件中,将来会是一个很大的文件,虽然可以把这个文件拆分成多个文件,但是多个表及索引在表空间中存储,这样对于一个表做了大量的删除操作后表空间会有间隙,对于统计分析和日志不适合用共享表空间。
二、字段选择:
- 尽量使用更小的数据类型(占用更少的磁盘,内存,CPU缓存)
- VARCHAR 的长度只分配真正需要的空间,需要注意的是255这个范围,大于255则会使用2个字节来存储字符长度,小于等于255则使用1个字节来存储字符长度。
- 创建自增长的主键ID
- 尽量使用TIMESTAMP 而非 DATETIME
- 单表不要有太多字段,建议20以内
- 避免使用 NULL 字段,很难查询优化且占用额外索引空间
三、三范式与反范式
三范式
- 字段不可再分割
- 有主键,非主键字段依赖主键
- 非主键字段不能相互依赖(设置自增ID主键)
反三范式:数据放在一张表中,不需要关联表,查询快。
四、索引部分
- 索引并不是越多越好,要根据SQL查询有针对性的创建,考虑 WHERE 和 ORDER BY。
- 可以使用 EXPLAIN 来查看是否用了索引还是全表扫描。
- 应尽量避免在 WHERE 子句中对字段进行 NULL 值判断,否则将导致引擎放弃使用索引而进行全表扫描。
- 值分布比较稀少的字段不适合建立索引,例如“性别”这种只有两三个值的字段。
- 字符字段只建前缀索引。
- 一般没有具体要求,设置无符号且不为负的自增 ID 为主键索引。
- 尽量不用外键,由程序保证约束。
- 尽量不用 UNIQUE, 由程序保证约束。
- 使用多列索引时注意顺序和查询条件保持一致,同时删除不必要的单列索引。
五、缓存
MySQL在解析一个查询语句前,如果查询缓存是打开的。那么MySQL会检查这个查询语句是否命中查询缓存中的数据。如果当前查询恰好命中查询缓存,会直接返回缓存中的结果。这种情况下,查询不会被解析,也不会生成执行计划,更不会执行语句。如果未命中查询缓存,MySQL进行语句解析,优化,查找到数据返回结果集,并且将结果集存入缓存中。
MySQL将缓存存放在一个引用表(不要理解成table,可以认为是类型HashMap的数据结构),通过一个哈希值索引,这个哈希值通过查询本身、当前要查询的数据库、客户端协议、版本号等一些可能影响结果的信息计算得来。所以两个查询在任何字符上的不同(例如:空格、注释),都会导致缓存不会命中。
如果查询中包含任何用户自定义函数、存储函数、用户变量、临时表、MySQL库中的系统表、其查询结果都不会被缓存。
既然是缓存,就会失效,那么查询缓存何时失效呢?MySQL的查询缓存系统会根据查询设计的每个表,如果这些表(数据或结构)发生变化,那么和这张表相关的所有缓存数据都将失效。正因为如此,在任何的写操作时,MySQL必须将对应表的所有缓存设置为失效。所以MySQL的缓存更加适用于“静态表”。
而且查询缓存对系统的额外小号也不仅仅在写操作,读操作也不例外:
- 任何的查询语句在开始之前都必须经过缓存检查,即使这条SQL语句永远不会命中缓存。
- 如果查询结果可以被缓存,那么执行完成后,会将结果存入缓存,也会带来额外的系统消耗。
六、分区分表
分区的好处是:
- 可以让单表存储更多的数据。
- 分区表的数据更容易维护,可以通过清除整个分区批量删除大量数据,也可以增加新的分区来支持新插入的数据。另外,还可以对一个独立分区进行优化、检查、修复等操作。
- 部分查询能够从查询条件确定只落在少数分区上,速度会很快。
- 可以使用分区表来皮鞭某些特殊瓶颈,例如 InnoDB 单个索引的互斥访问。
- 可以备份和恢复单个分区。
分区的限制和缺点:
- 一个表最多只能有1024个分区
- 如果分区字段有主键或者唯一索引的列,那么所有主键列和唯一索引列都必须包含进来。
- 分区表无法使用外键约束。
- NULL 值会使分区过滤无效。
- 所有分区必须使用相同的存储引擎。
垂直拆分
垂直分库是根据数据库里面的数据表的相关性进行拆分。
比如:一个数据库里面即存在用户数据,又存在订单数据,那么垂直拆分可以把用户数据放到用户库、把订单数据放到订单库。
垂直分表示对数据表进行垂直拆分的一种方式,常见的是把一个多字段的大表按常用字段非常用字段进行拆分,每个表里面的数据记录一般情况下是相同的,只是字段不一样,使用主表的主键关联。
比如原始的用户表为:

垂直拆分后是:
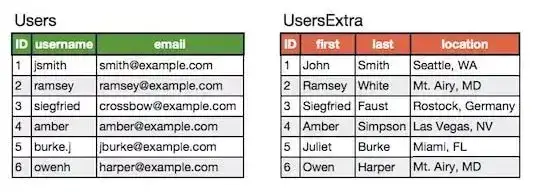
垂直拆分的优点:
- 可以使得行数据变小。
- 可以达到最大化利用 Cache 的目的,具体在垂直拆分的时候可以将不常用的字段放一起,将常改变的放一起。
- 数据维护简单。
缺点:
- 主键出现冗余,需要管理冗余列。
- 表关联 JOIN 操作(增加CPU开销),可以通过业务服务器上进行 JOIN 来减少数据库压力。
- 依然存在单表数据量过大的问题(需要水平拆分)。
- 事务处理复杂。
水平拆分
水平拆分是通过某种策略将数据分片存储,分库分表和分库两部分,每片数据会分散到不同的 MySQL 表或库。达到分布式的效果,能够支持非常大的数据量。前面的表分区本质也是一种特殊的库内分表。
库内分表,仅仅是单纯的解决了单一表数据过大的问题,由于没有把表的数据分布到不同的机器上,因此对于减轻 MySQL服务器的压力来说,并没有太大的作用,大家还是在竞争同一个物理机上的 IO、CPU、网络,这个就要通过分库来解决。
原始表:

进行水平拆分:


实际情况中往往是垂直拆分和水平拆分的结合。
水平拆分的优点:
- 不存在单库大数据和高并发的性能瓶颈。
- 应用端改造较少。
- 提高了系统的稳定性和负载能力。
缺点是:
- 分片事务一致性难以解决。
- 跨节点 JoIn 性能差,逻辑复杂
- 数据多次扩展难度跟维护量极大。
分片原则:
- 能不分就不分,参考单表优化。
- 分片数量尽量少,分片尽量均匀分布在多个数据节点上,因为一个查询 SQL 跨分片越多,则总体性能越差,虽然要好于所有数据在一个分片的结果,只在必要的时候进行扩容,增加分片数量。
- 分片规则需要慎重选择做好提前规划,分片规则的选择,需要考虑数据的增长模式,数据的访问模式,分片关联性问题,以及分片扩容问题,最近的分片策略为范围分片,枚举分片,一致性 Hash 分片,这几种分片都利用扩容。
- 尽量不要在一个事务中的 SQL 跨越多个分片, 分布式事务一直是个不好处理的问题。
- 查询条件尽量优化,避免 SELECT * 的方式,大量数据结果集下,会消耗大量带宽和 CPU 资源,查询尽量避免返回大量结果集,并且尽量为频繁使用的查询语句建立索引。
- 通过数据冗余和表分区依赖降低跨库 Join 的可能。
总的来说,分片的选择取决于醉频繁的查询 SQL 的条件,因为不带任何 Where 语句的查询 SQL,会遍历所有的分片,性能相对最差, 因此这种 SQL 越多,对系统的影响越大, 所以我们要尽量避免这种 SQL 的产生。
















 6万+
6万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











