









思路:匹配中文并依次排除注释中的内容,检测字符是否在注释中时使用了正则表达式的断言。
1. 根据Unicode编码规则,匹配中文使用:[\u4e00-\u9fa5],注:该范围不含中文标点符号等字符
2. 排除单行注释,即忽略单行中出现//后的内容:(?<!\/\/.*)[\u4e00-\u9fa5]+
3. 排除/**/包裹的多行注释:(?<!\/\*(.(?<!\*\/)\n?)*)[\u4e00-\u9fa5]+
4. 同理,排除<!---->包裹的多行注释:(?<!<!--(.(?<!-->)\n?)*)[\u4e00-\u9fa5]+
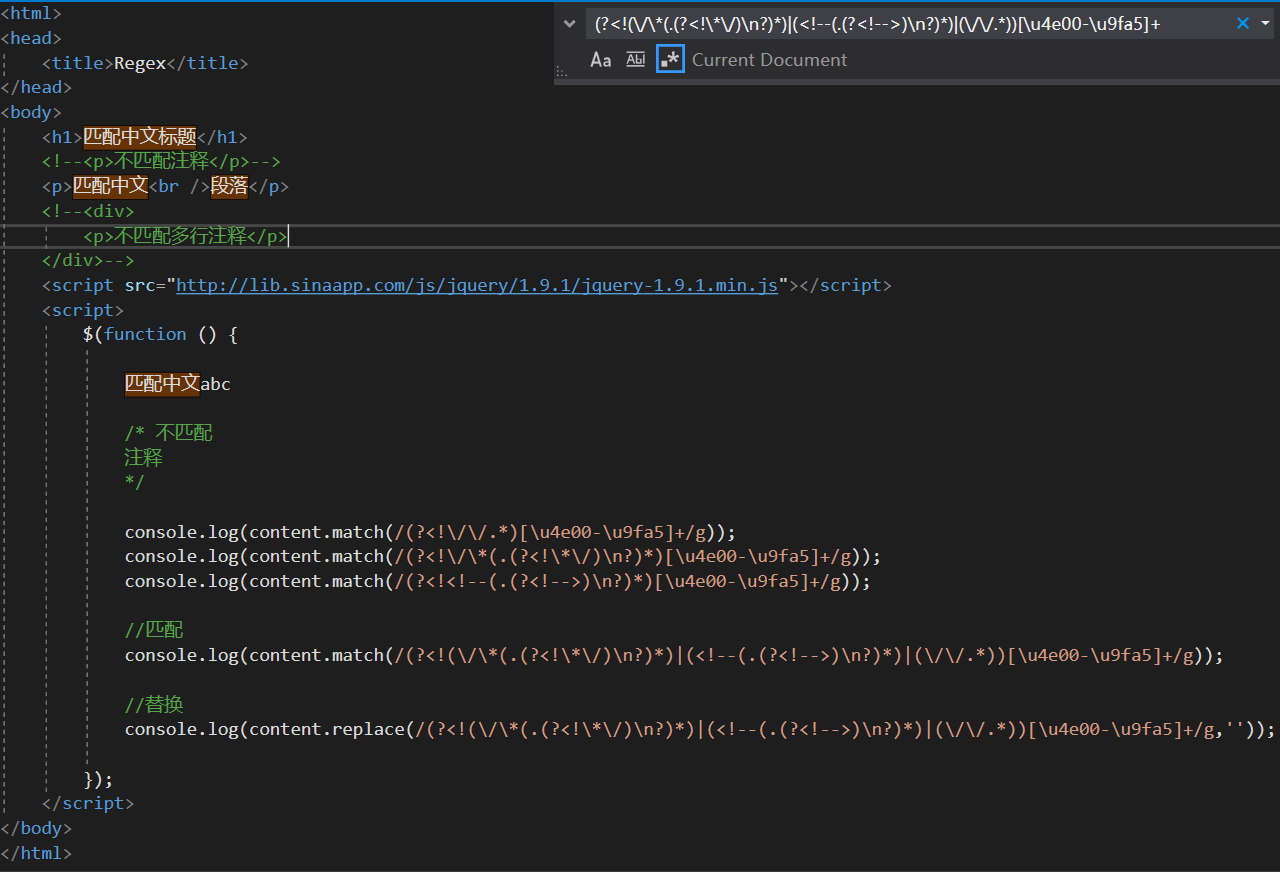
5. 整合为一个表达式:(?<!(\/\*(.(?<!\*\/)\n?)*)|(<!--(.(?<!-->)\n?)*)|(\/\/.*))[\u4e00-\u9fa5]+JavaScript完整测试代码,将以下代码保存为html文档,在浏览器打开即可在控制台查看效果。
<html>
<head>
<title>正则测试</title>
</head>
<body>
<script src="http://lib.sinaapp.com/js/jquery/1.9.1/jquery-1.9.1.min.js"></script>
<script>
$(function () {
var content = `<html>
<head>
<title>Regex</title>
</head>
<body>
<h1>匹配中文标题</h1>
<!--<p>不匹配注释</p>-->
<p>匹配中文<br />段落</p>
<!--<div>
<p>不匹配多行注释</p>
</div>-->
<script>
$(function () {
匹配中文abc //不匹配注释
/* 不匹配
注释
*/
});`;
//去除//类型的注释
console.log(content.match(/(?<!\/\/.*)[\u4e00-\u9fa5]+/g));
//去除/**/类型的注释
console.log(content.match(/(?<!\/\*(.(?<!\*\/)\n?)*)[\u4e00-\u9fa5]+/g));
//去除<!---->类型的注释
console.log(content.match(/(?<!<!--(.(?<!-->)\n?)*)[\u4e00-\u9fa5]+/g));
//匹配
console.log(content.match(/(?<!(\/\*(.(?<!\*\/)\n?)*)|(<!--(.(?<!-->)\n?)*)|(\/\/.*))[\u4e00-\u9fa5]+/g));
//替换
console.log(content.replace(/(?<!(\/\*(.(?<!\*\/)\n?)*)|(<!--(.(?<!-->)\n?)*)|(\/\/.*))[\u4e00-\u9fa5]+/g,''));
});
</script>
</body>
</html>Visual Studio编辑器中测试效果。















 4912
4912











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









