






1 介绍
年份:2020
会议: 2019CPVR
Zhao B, Xiao X, Gan G, et al. Maintaining discrimination and fairness in class incremental learning[C]//Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. 2020: 13208-13217.
本文提出了一种解决类别增量学习中灾难性遗忘问题的算法,通过知识蒸馏(KD)保持旧类之间的区分度,并引入权重对齐(WA)方法校正全连接层中偏差的权重,以维持新旧类别之间的公平性。
2 创新点
- 知识蒸馏(KD)的作用分析:
- 通过实验分析了知识蒸馏在类别增量学习中的实际作用,包括其正面和负面影响。
- 权重对齐(WA)的提出:
- 提出了一种新的权重对齐方法,用于纠正全连接层中偏差的权重,以保持新旧类别之间的公平性。
- 权重对齐的实现方式:
- 权重对齐方法不需要额外的参数或预先保留的验证集,而是利用偏差权重本身的信息来进行校正。
- 模型结构的简化:
- 与以往的工作相比,提出的解决方案简化了模型结构,不依赖于额外的模型参数或超参数调整。
- 实验验证:
- 在ImageNet-1000、ImageNet-100和CIFAR-100数据集上进行了广泛的实验验证,结果表明所提方法优于现有的最先进方法。
- 信息利用的探索:
- 工作可能暗示了在训练好的模型中隐藏着许多有用的信息,这些信息值得进一步探索和利用。
3 算法
3.1 算法原理
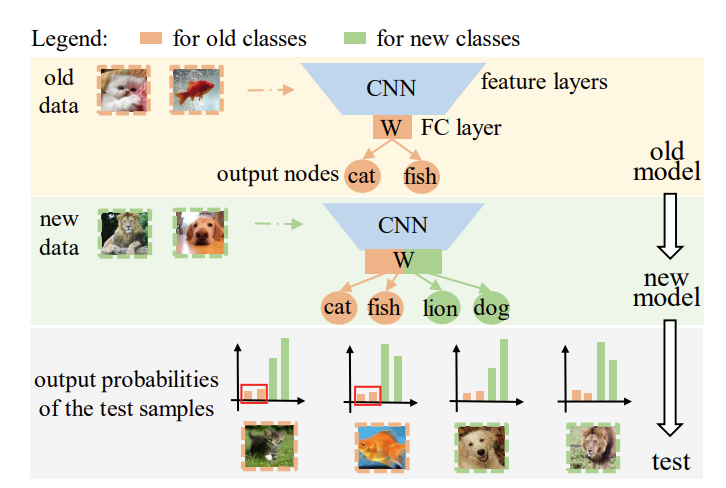
- 知识蒸馏(Knowledge Distillation, KD):
- 利用知识蒸馏技术,通过从教师模型(已经训练好的模型)向学生模型(新模型)传递关键知识,以保持对旧类别的区分度。知识蒸馏通过修改交叉熵损失函数来保留旧模型的能力,帮助模型在输出旧类别时更加具有区分性。
- 权重对齐(Weight Aligning, WA):
- 观察到在类别增量学习过程中,全连接层(FC层)的权重对于新类别会有较大的偏差。为了纠正这种偏差,提出了权重对齐方法,该方法通过调整新类别的权重向量范数使其与旧类别的权重向量范数对齐,从而减少模型对新类别的预测偏好。
- 权重对齐的具体实施:
- 在权重对齐阶段,算法首先将FC层的权重分为旧类别权重(Wold)和新类别权重(Wnew)两部分。
- 计算这两部分权重向量的范数,并计算旧类别和新类别权重向量范数的平均值。
- 通过调整新类别权重向量的平均范数与旧类别相等,来实现权重对齐。具体来说,通过乘以一个缩放因子(γ),该因子是旧类别权重向量范数平均值与新类别权重向量范数平均值的比值。
- 权重限制(Restriction to the Weights):
- 为了使权重向量的范数与其对应的输出对数几率更加一致,算法在训练过程中对FC层的权重向量元素施加了正数限制,即通过权重剪辑(weight clipping)确保权重向量只包含正值。
- 两阶段训练:
- 算法分为两个阶段:首先是保持区分度阶段,使用交叉熵损失和知识蒸馏损失联合训练新模型;其次是保持公平性阶段,对第一阶段训练好的模型应用权重对齐方法进行校正。
3.2 算法步骤
- 初始化模型:
- 在每个增量学习步骤开始时,使用之前步骤中学习到的模型参数初始化新模型,并为新类别添加新的输出节点(在FC层中随机初始化权重)。
- 结合知识蒸馏训练模型:
- 使用交叉熵损失(LCE)和知识蒸馏损失(LKD)联合训练模型。交叉熵损失帮助模型学习新数据,而知识蒸馏损失则保持模型对旧类别的识别能力。
- 权重对齐(Weight Aligning, WA):
- 在正常训练过程之后,应用权重对齐方法来纠正FC层中偏差的权重。具体步骤包括:
- 将FC层的权重分为旧类别权重(Wold)和新类别权重(Wnew)。
- 计算旧类别和新类别权重向量的范数,并求出各自的平均值。
- 通过计算旧类别和新类别权重向量范数的平均值的比值(γ),来调整新类别权重向量,使得它们的平均范数与旧类别相等。
- 在正常训练过程之后,应用权重对齐方法来纠正FC层中偏差的权重。具体步骤包括:
- 输出对数几率的调整:
- 根据权重对齐的结果,调整模型输出的对数几率,以减少对新类别的预测偏好。
- 权重限制:
- 在训练过程中,对FC层的权重向量元素施加正数限制,通过权重剪辑确保权重向量只包含正值,使得权重向量的范数与其对应的输出对数几率更加一致。
- 模型评估:
- 在每个增量学习步骤结束时,评估模型在所有已学习类别上的性能,确保新旧类别都能被准确识别。
- 迭代学习:
- 重复以上步骤,直到所有增量学习步骤完成,实现在不断学习新类别的同时,保留对旧类别的记忆和识别能力。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











