







Redis 的列表相当于 Java 语言里面的 LinkedList,注意它是链表而不是数组。这意味着 list 的插入和删除操作非常快,时间复杂度为 O(1),但是索引定位很慢,时间复杂度为 O(n),这点让人非常意外。 当列表弹出了最后一个元素之后,该数据结构自动被删除,内存被回收。
1.常用命令

1.存(push)
lpush key value [key value...] // 将一个或多个值value插入到key列表的表头(最左边)
rpush key value [key value...] // 将一个或多个值value插入到key列表的表尾(最右边)
2.取(pop)
lpop key // 移除并返回key列表的头元素
rpop key // 溢出并返回key列表的尾元素
blpop key timeout // 从key列表表头弹出一个元素,若列表中没有元素,阻塞等待timeout秒,如果timeout=0,一直阻塞等待
brpop key timeout // 从key列表表尾弹出一个元素,若列表中没有元素,阻塞等待timeout秒,如果timeout=0,一直阻塞等待
lrange key start stop // 范围取(range),返回列表key中指定区间[start,stop]内的元素,
2.应用示例
1.实现栈,队列,阻塞队列
一般都使用lpush,pop看具体场景要求
stack(栈) = lpush + lpop // FILO
queue(队列) = lpush + rpop // FIFO
blockingqueue(阻塞队列) = lpush + brpop
2.订阅(消息队列)
list可以用于微博和微信的订阅消息,比如我关注了某个公众号,它一发文章我就能收到
- 服务器通过redis为每个用户都维护一个消息队列
- 当某个用户发送消息后,通过查数据库查出订阅者的uId,然后向指定消息队发送
- 待订阅者打开相关页面时,再从相应消息队列里取出
//...消息发送方查出订阅者uId
// 向订阅者的通道发送消息
lpush msg:uId msgId1
lpush msg:uId msgId2
// 从队列中取出消息给订阅者
lrange msg:uId 0 5 // 取5条msg
3.存储原理
在 Redis3.2 之前,List 底层采用了 ZipList 和 LinkedList 实现的。
初始化的 List 使用的 ZipList,List 满足以下两个条件时则一直使用 ZipList 作为底层实现,当以下两个条件任一一个不满足时,则会被转换成 LinkedList
- List 中存储的每个元素的长度小于 64byte
- 元素个数小于 512
3.2 版本之后,List 底层采用 QuickList 来存储。quicklist 存储了一个双向链表,每个节点都是一个 ziplist。
ZipList 方式
压缩列表是 redis 为了节约内存而开发的,是由一系列的特殊编码的连续内存块组成的双向链表。一个压缩列表可以包含任意多个节点(entry),每个节点可以保存一个字节数组或者一个整数值,值的类型和长度由节点的encoding属性决定。
它不存储指向上一个链表节点和指向下一个链表节点的指针,而是存储上一个节点长度和当前节点长度,也就是和说与数组的区别在于数组的每个元素大小相同,而 ziplist 的每个节点的大小不是固定(保存->计算地址)。
ziplist 通过牺牲部分读写性能,来换取高效的内存空间利用率,是一种时间换空间的思想。只用在字段个数少,字段值小的场景里面。
来看 ziplist 的整体结构:
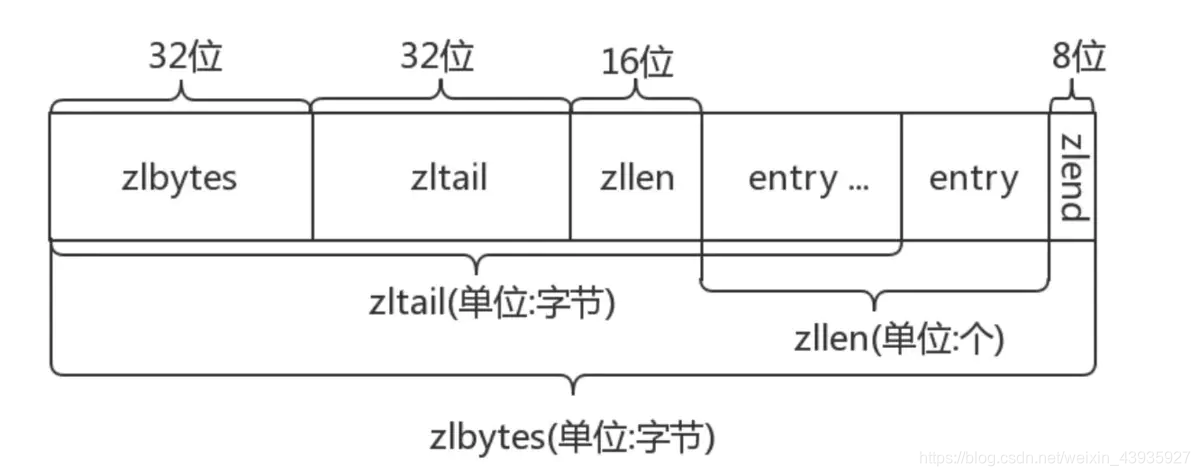
- zlbytes:表示当前 list 的存储元素的总长度
- zllen:表示当前 list 存储的元素的个数
- zltail:表示当前 list 的头结点的地址,通过 zltail 就是可以实现 list 的遍历
- zlend:表示当前 list 的结束标识
下面看具体的元素 zlentry 是怎么定义的:
typedef struct zlentry {
/* 上一个链表节点占用的长度 */
unsigned int prevrawlensize;
/* 存储上一个链表节点的长度数值所需要的字节数 */
unsigned int prevrawlen;
/* 存储当前链表节点长度数值所需要的字节数 */
unsigned int lensize;
/* 当前链表节点占用的长度 */
unsigned int len;
/* 当前链表节点的头部大小(prevrawlensize + lensize),即非数据域的大小 */
unsigned int headersize;
/* 编码方式 */
unsigned char encoding;
/* 压缩链表以字符串的形式保存,该指针指向当前节点起始位置 */
unsigned char *p;
} zlentry;
ZipList 的优缺点比较
- 优点:内存地址连续,省去了每个元素的头尾节点指针占用的内存
- 缺点:对于删除和插入操作比较可能会触发连锁更新反应,比如在 list 中间插入删除一个元素时,在插入或删除位置后面的元素可能都需要发生相应的移动操作
LinkedList 方式
LinkedList 都比较熟悉了,是由一系列不连续的内存块通过指针连接起来的双向链表。
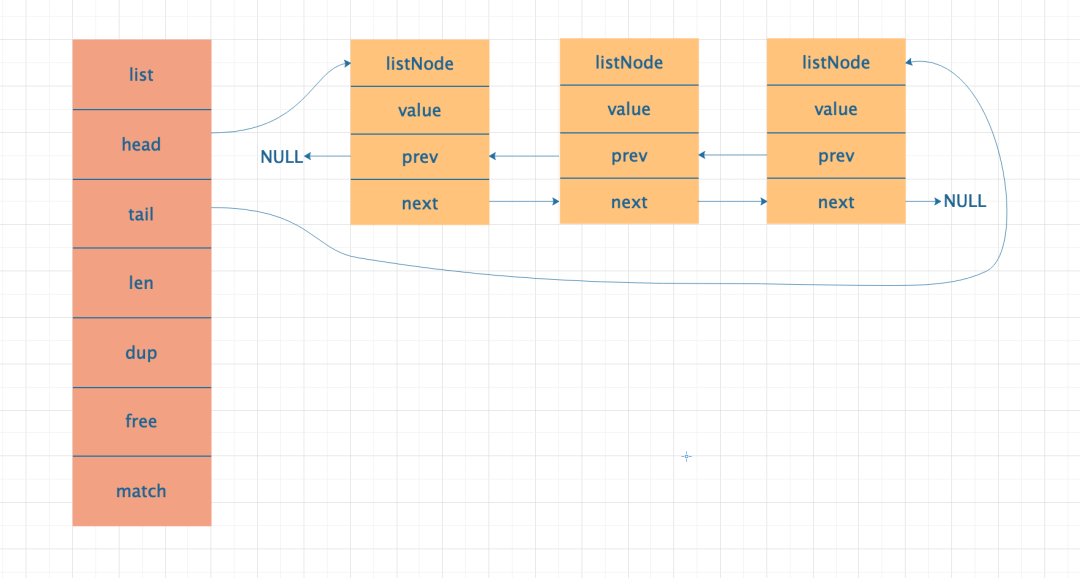
各部分作用说明:
- head:表示 List 的头结点;通过其可以找到 List 的头节点
- tail:表示 List 的尾节点;通过其可以找到 List 的尾节点
- len:表示 List 存储的元素个数
- dup:表示用于复制元素的函数
- free:表示用于释放元素的函数
- match:表示用于对比元素的函数
QuickList 方式
在 Redis3.2 版本之后,Redis 集合采用了 QuickList 作为 List 的底层实现,QuickList 其实就是结合了 ZipList 和 LinkedList 的优点设计出来的。
typedef struct quicklist {
/* 指向双向列表的表头 */
quicklistNode *head;
/* 指向双向列表的表尾 */
quicklistNode *tail;
/* 所有的 ziplist 中一共存了多少个元素 */
unsigned long count;
/* 双向链表的长度,node 的数量 */
unsigned long len;
/* fill factor for individual nodes */
int fill : 16;
/* 压缩深度,0:不压缩; */
unsigned int compress : 16;
} quicklist;

各部分作用说明:
- 每个 listNode 存储一个指向 ZipList 的指针,ZipList 用来真正存储元素的数据
- ZipList 中存储的元素数据总大小超过 8kb(默认大小,通过 list-max-ziplist-size 参数可以进行配置)的时候,就会重新创建出来一个 ListNode 和 ZipList,然后将其通过指针关联起来















 1084
1084











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











