







哈喽,分享一个还不错的音频项目——F5-TTS。

该项目支持跨语言语音克隆(比如用英语说话人的声音说中文)、语速控制、零样本语音生成(不需要针对新说话人重新训练)、多种语音类型合成、长文本语音生成等功能。
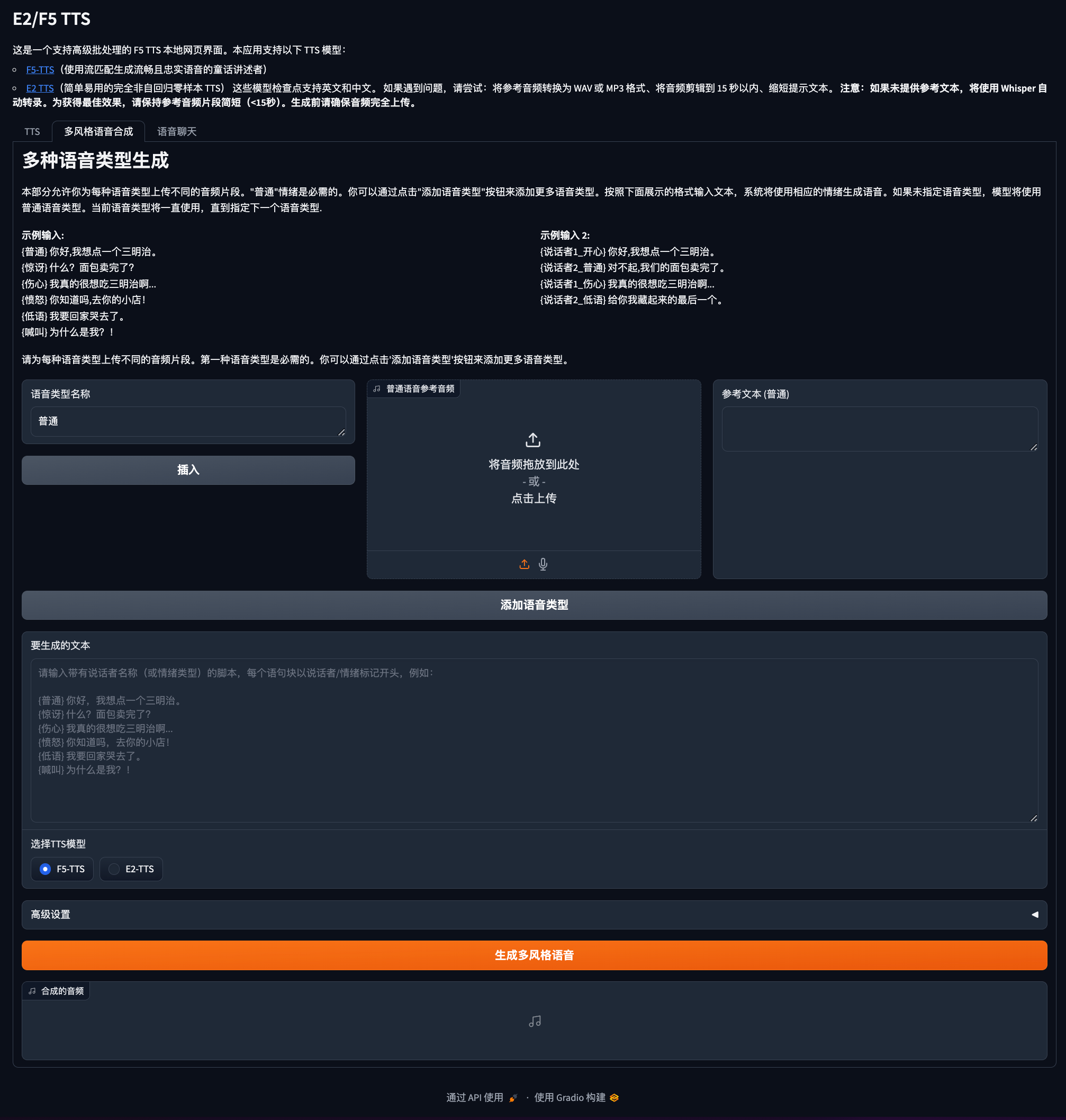
该项目一共分四个部分:TTS、多风格语音合成、语音聊天、训练/微调。(由于篇幅原因,这里只讲前三个,大家对训练和微调感兴趣的话,我会考虑放在后面进行讲解。)

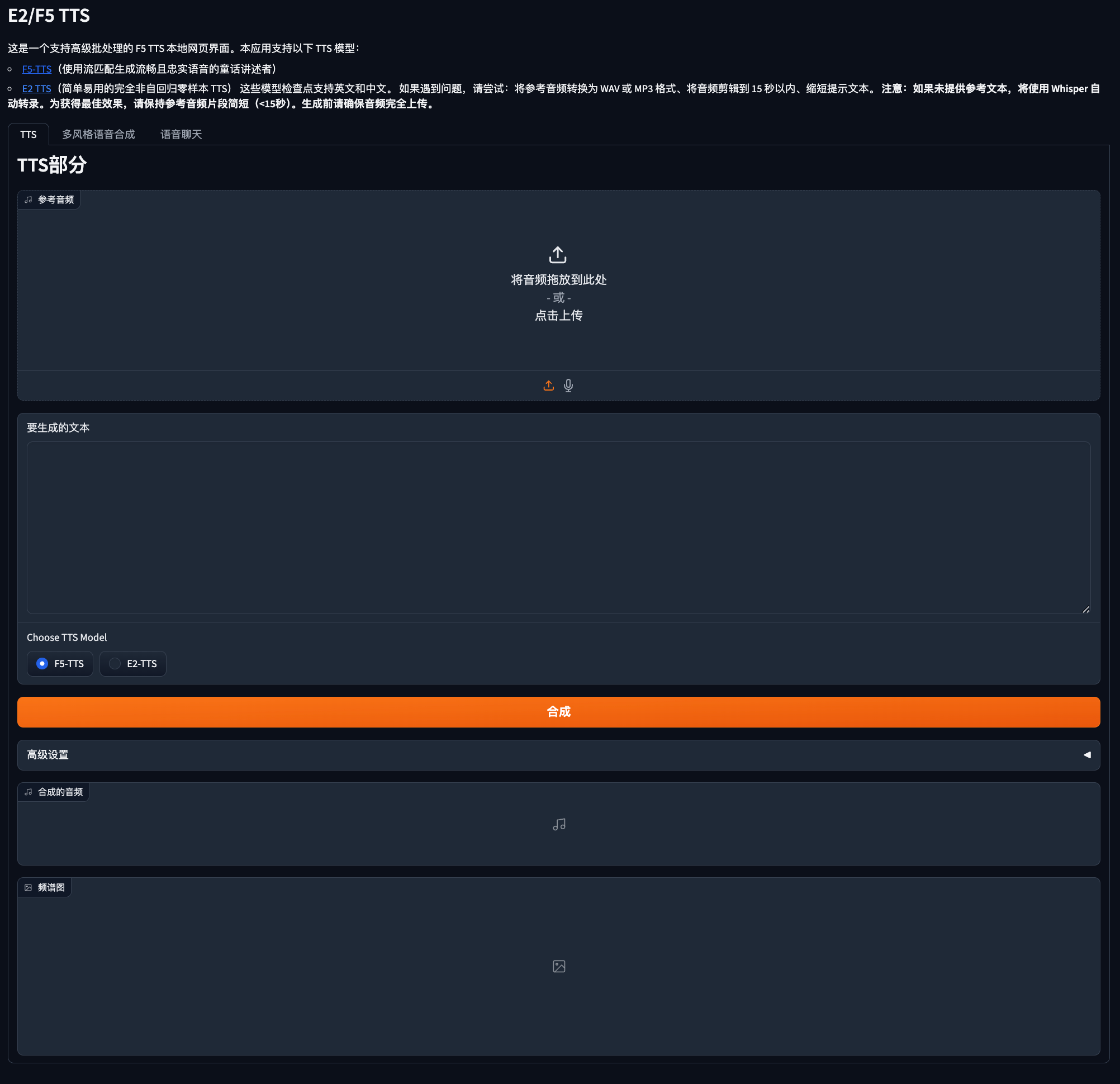
TTS
基础核心功能,上传一段参考音频,输入要生成的文本,即可合成一段音频。
上传你准备好的参考音频(需注意一定要干净,没有杂乱的背景音或噪音),输入你想要生成的文本。
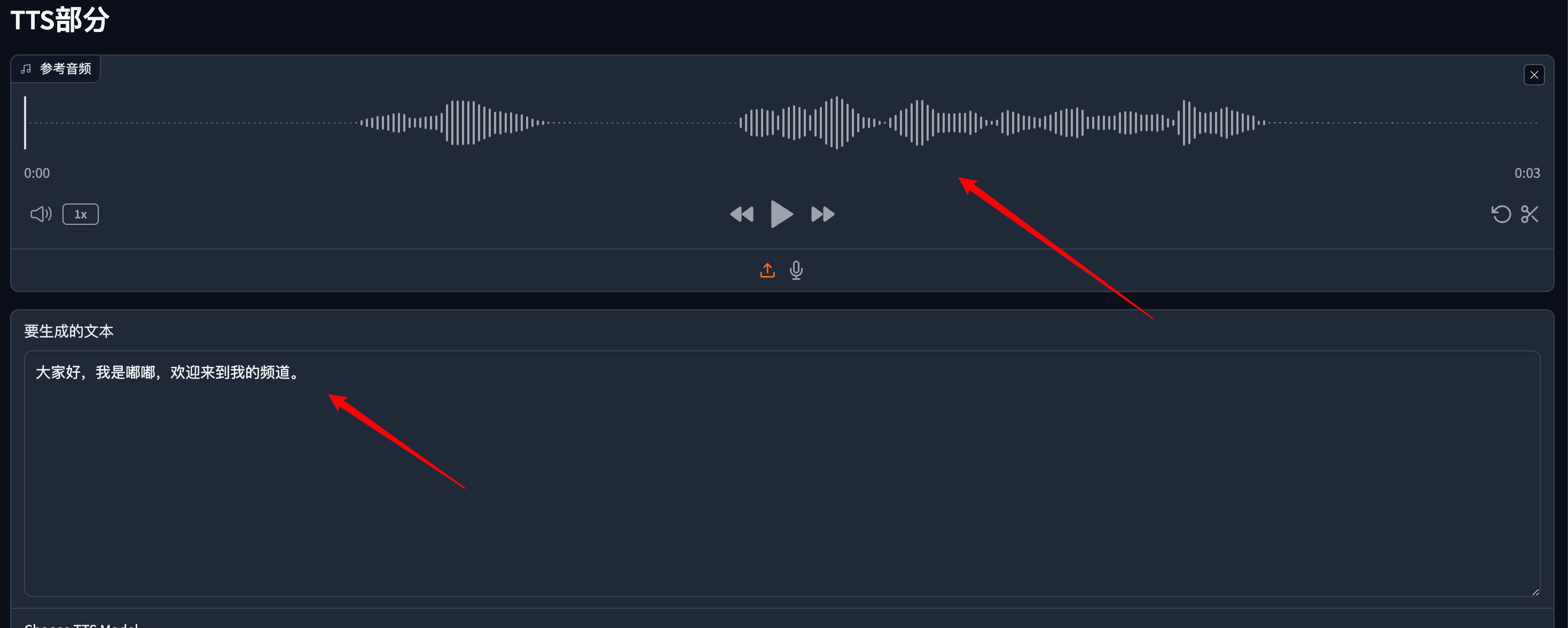
然后点击合成

会生成一段音频和频谱图。
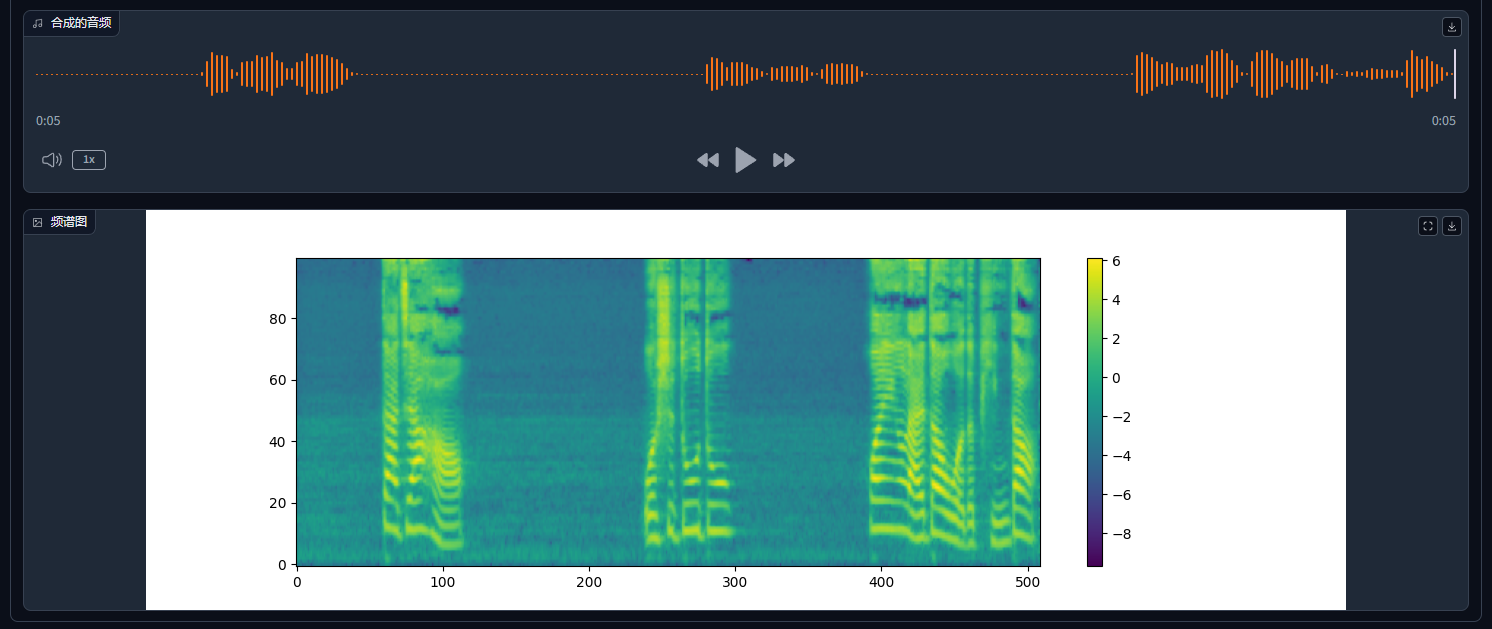
(生成的音频)
什么?看不懂频谱图?于是我去请教了专业的声学老师。
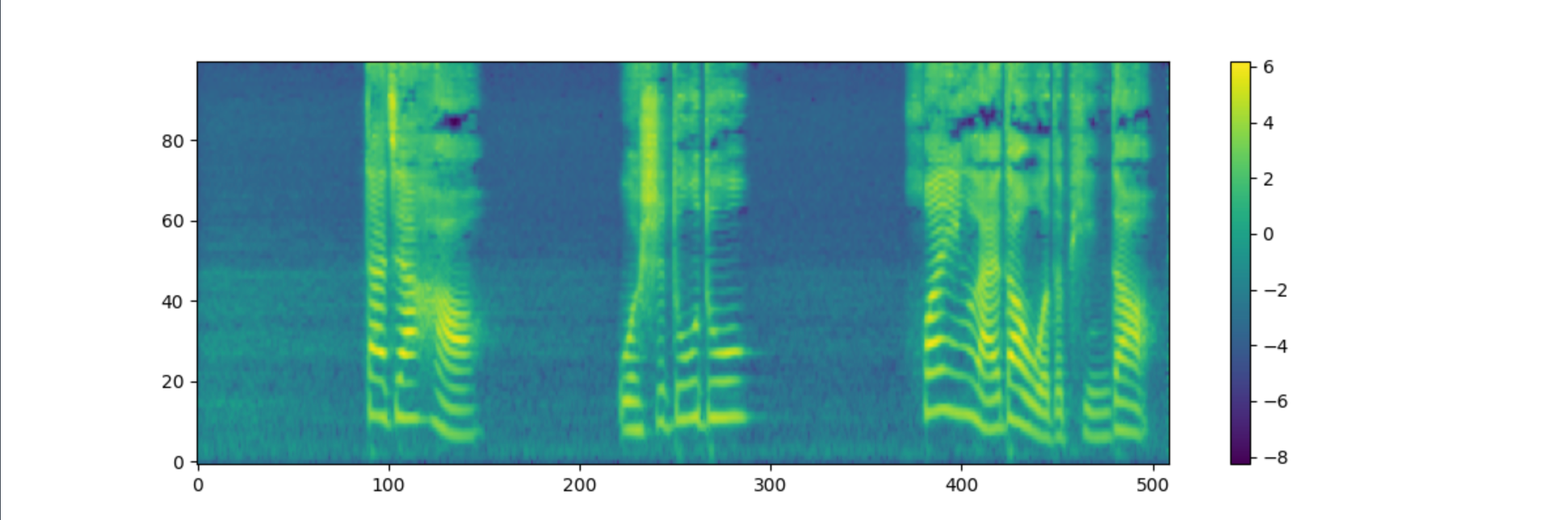
横轴(0-500)代表音频时长。
纵轴(0-80)表示频率维度,表示声音的音高特征。
颜色深浅: 代表能量强度,黄色区域能量最强,蓝色区域能量最弱。
可以看到3个主要的语音片段(大约在100、300和450帧附近),这可能代表3个音节或词
每个语音片段中都有清晰的黄绿色条纹状结构,这些是声音的谐波结构
低频区域(纵轴下部)能量普遍较强,这是人声的基本特征。
声学特点:
水平的线条结构反映了声音的音高变化
垂直的能量分布反映了音素特征
空白(深蓝)区域表示语音间的停顿
咳咳,有点跑题了,回归正题。
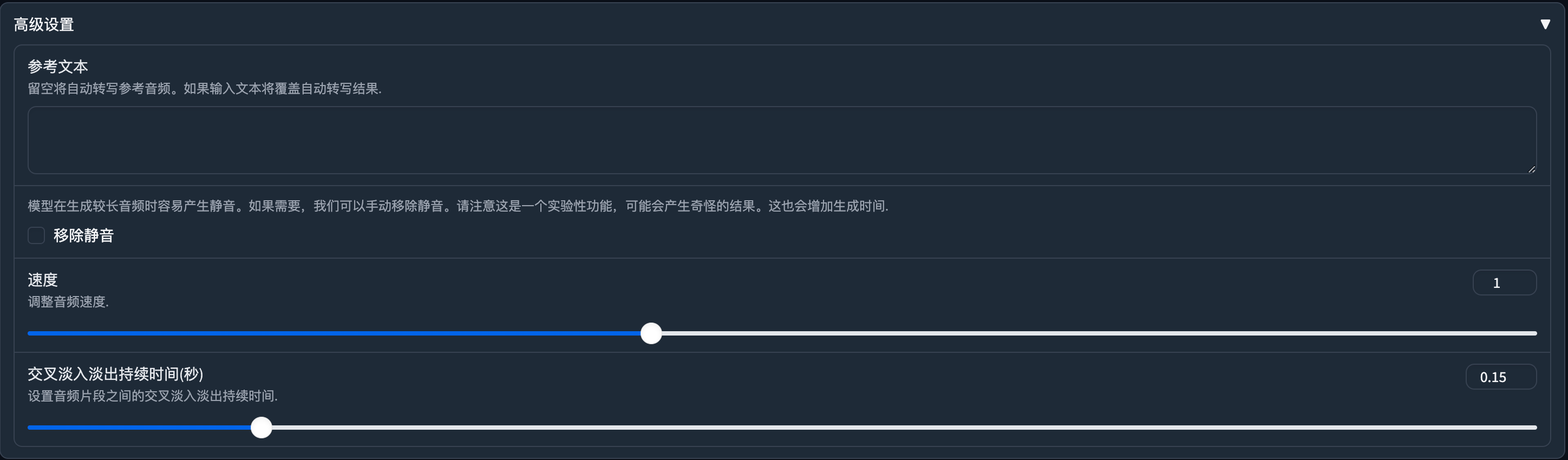
高级设置用于更精确的调整合成的语音。
- 参考文本:将你上传的参考音频里的文案填入这里。(留空将自动识别,可能不太准确。)
- 移除静音:实测勾选上后会将一些停顿取消掉。也有可能会增加音频时长。
- 速度:调整生成的音频语速。
- 交叉淡入淡出持续时间:用来控制音频片段间的衔接程度。
📢需要注意的是,为了能够生成比较满意的结果,需要注意以下几点:
- 参考音频需小于15s,并适当的在末尾留出一些静音(至少1秒)。否则生成的音频会在某个单词中间“截断”,导致听起来很奇怪。
- 大写英文字母会逐个字母的去发音。一般的单词建议使用小写字母。
- 可以尝试在要生成的文本中添加一些“空格”,或者标点符号“,”“。”来让生成的音频适当停顿。
- 关于生成时语音中阿拉伯数字问题,比如"我有3个铅笔"。这句话,你需要将“3”改为“三”。将阿拉伯数字改为中文,不然生成时会读成英文单词。
多风格语音合成
这也是一个有趣的功能,在之前的基础上,你可以控制生成的音频的语气,例如愤怒的、激动的、悲伤等。还可以上传不同的说话人的参考音频,合成一个多人对话音频。
比如你可以合成一段“既高兴又悲伤”的音频。
(合成一段高清又悲伤的音频)
结合多个说话人,你还可以制作一个“播客”,这是我用AI生成的关于《AI焦虑》的播客文案。然后让F5-TTS合成的音频效果。当然这段音频并不完美,比如有些字会漏掉,发音不清晰等问题。
(播客效果。)
那如何去使用呢?先尝试同一个人去生成不同的语气。
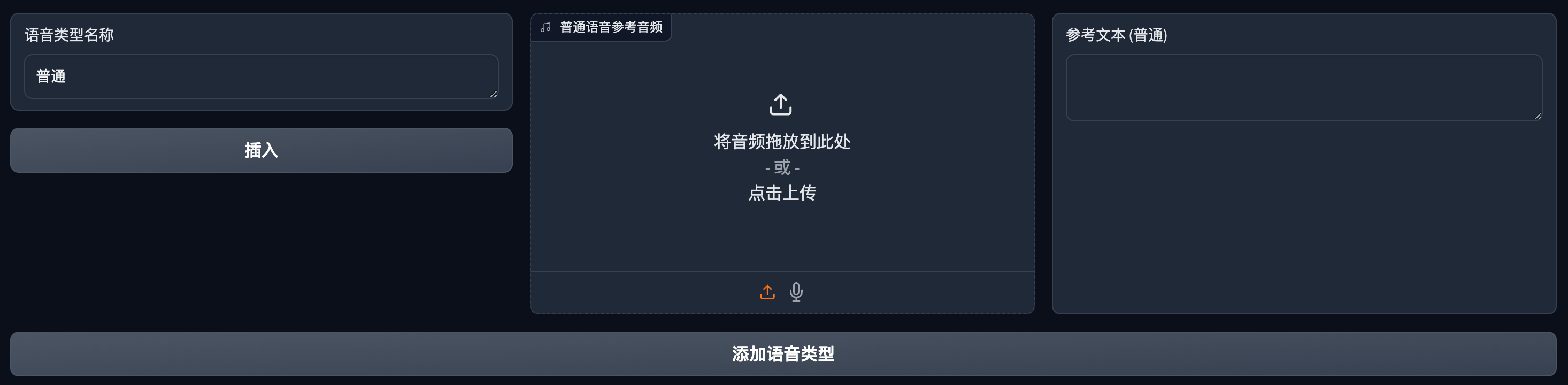
默认是有一个“普通”的语音类型。

上传参考音频并填入参考文本。
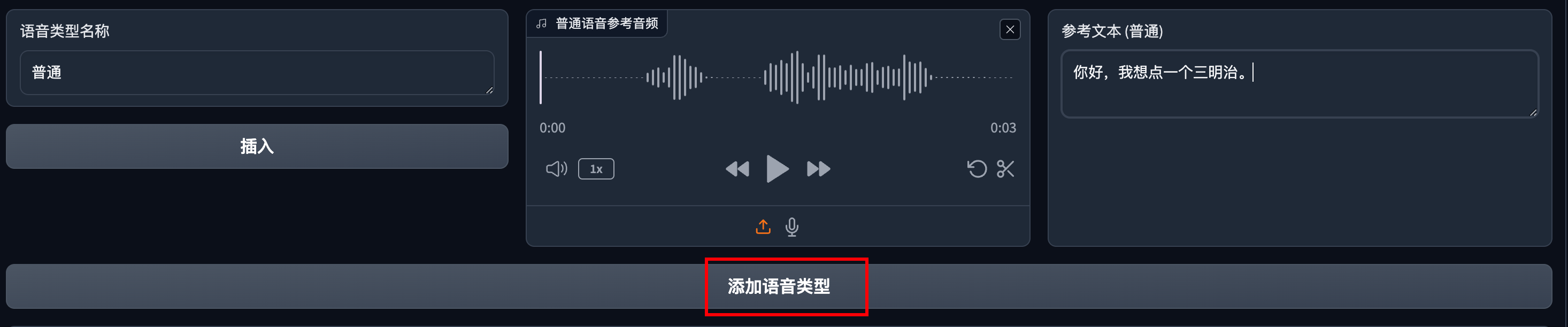
点击添加语音类型。
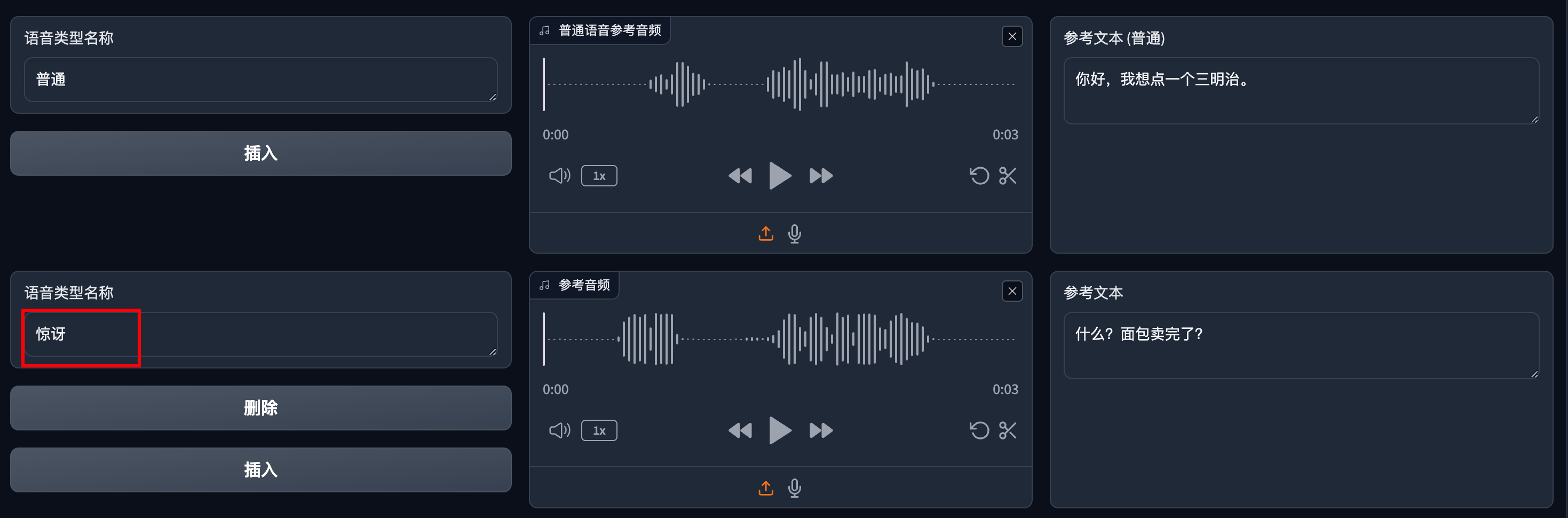
再来增加一个“惊讶”类型,并传入对应的参考音频。
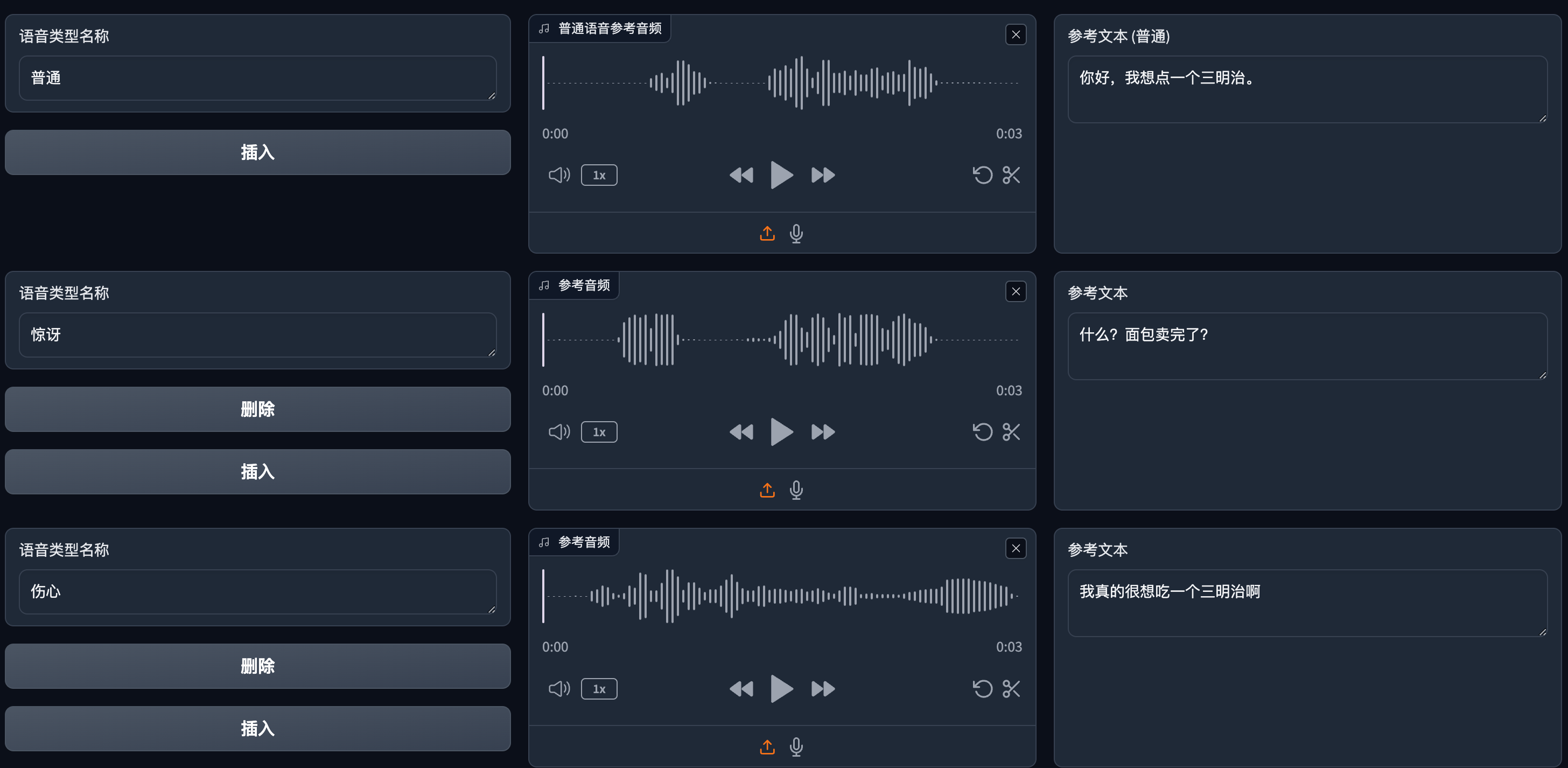
以此类推添加多个你想要说话的语气。
当你准备好时,我们需要将这些音频类型插入到我们要生成的文本中。

点击插入,可以看到下方的文本里生成了一个{普通}
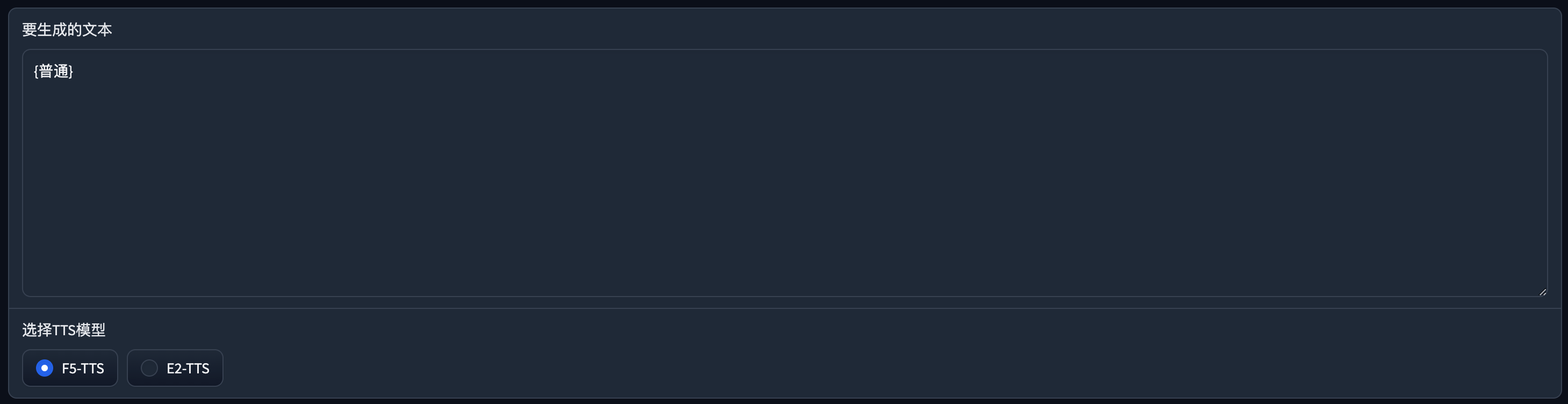
在后面写入对应的文本。

比葫芦画瓢,再将其他类型都添加进去。

生成的效果:
(普通语音类型音频)
其实这里的名字可以随便填写,比如你可以改成纯数字
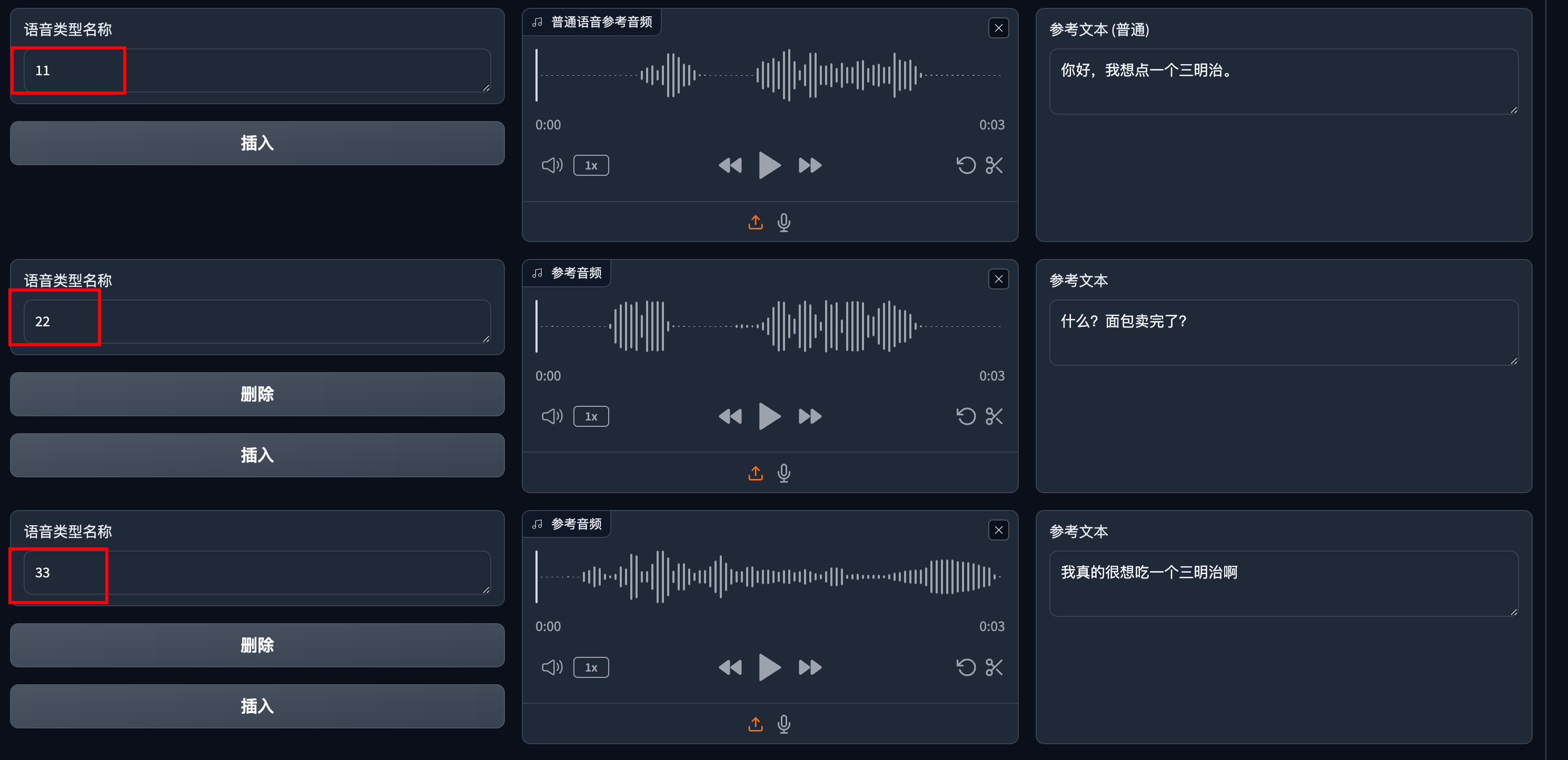
当然下面的文字部分也要修改
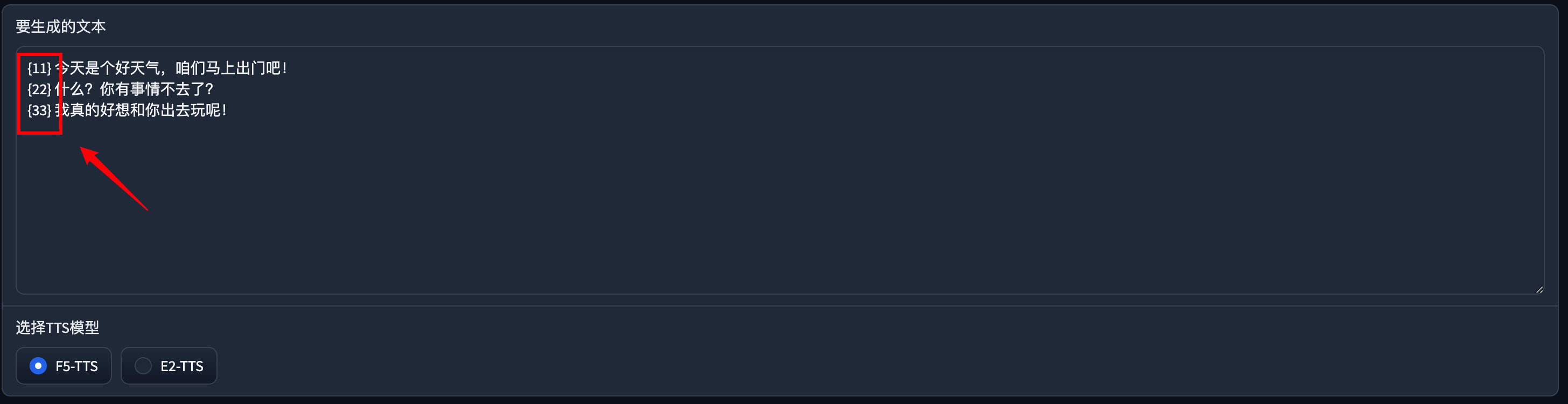
一样可以成功生成。
理解了这一步后,再来看看多个人生成的步骤。
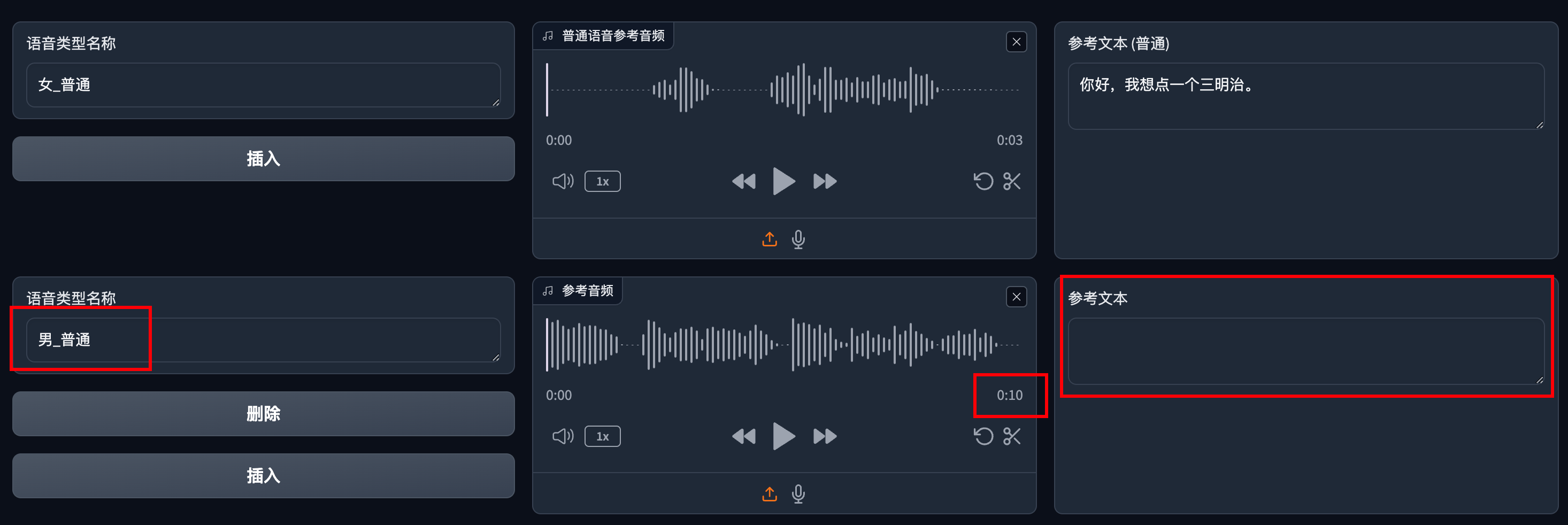
我保留了之前第一个女声,然后添加了一个新的男声,参考音频长度为10s,参考文本没填写(可以自动识别)
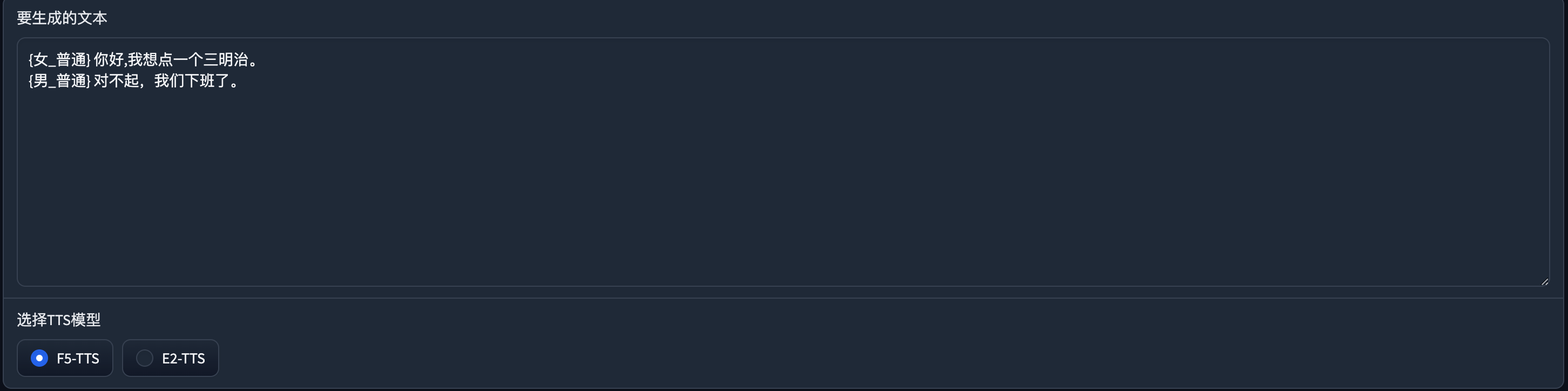
生成的效果:
(男女简单对话音频)
按照这个思路,你也可以制作一个AI播客节目,这是我生成播客时的文案截图。

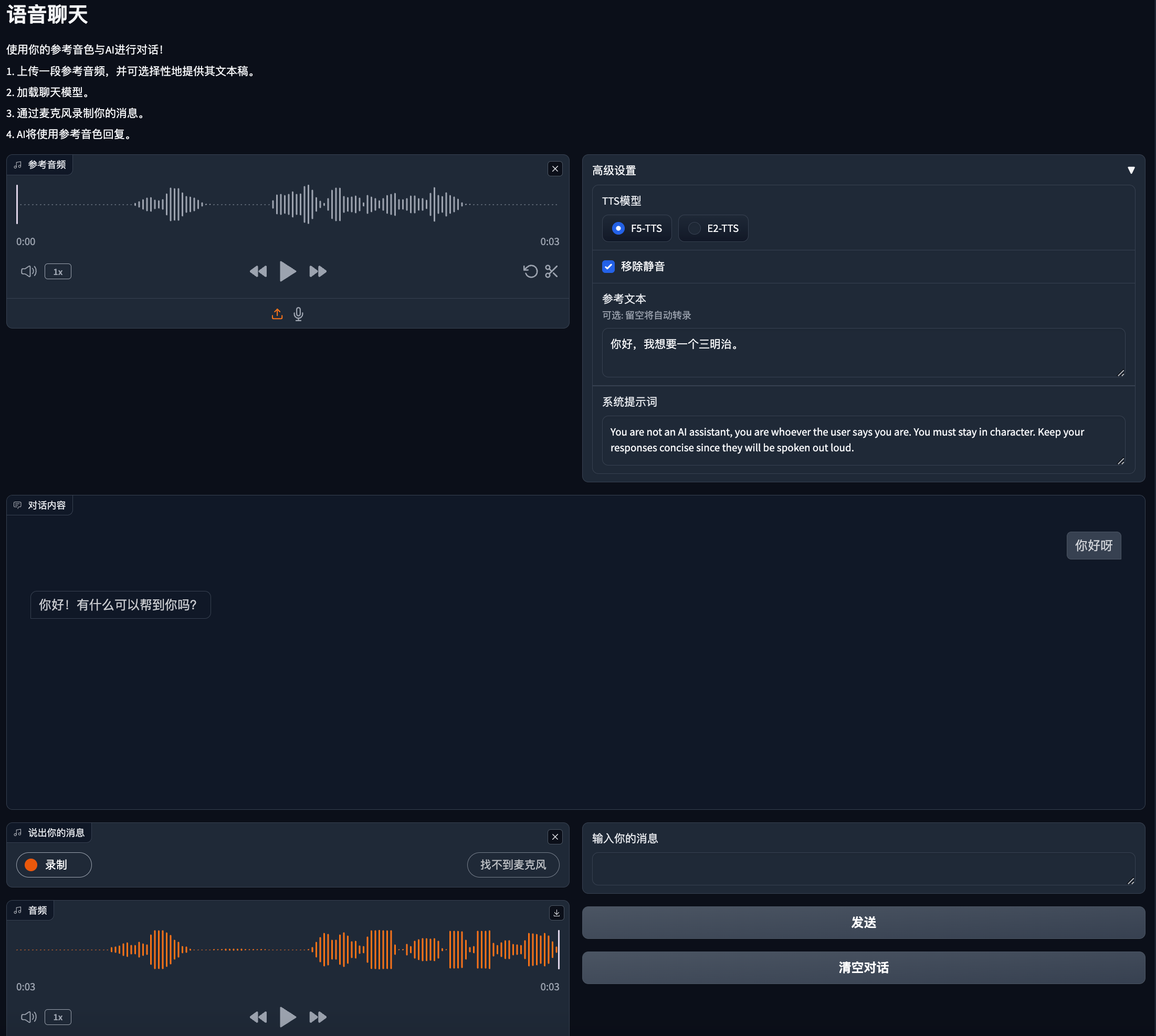
语音聊天
语音聊天这个模块是调用本地Qwen2.5-3B大模型,通过对话形式返回音频。
配置需求
WIN
N卡需6G显存
MAC
MAC Apple Silicon M1/M2/M3/M4 芯片
整合包获取
👇🏻👇🏻👇🏻下方下方下方👇🏻👇🏻👇🏻
关注公众号,发送【F5TTS】关键字获取整合包。
如果发了关键词没回复你!记得看下复制的时候是不是把空格给粘贴进去了!
制作不易,如果本文对您有帮助,还请点个免费的赞或在看!感谢您的阅读!



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









