







一、什么是MemCache
-
memcache是一套分布式的高速缓存系统,目前被许多网站使用以提升网站的访问速度,尤其对于一些大型的、需要频繁访问数据库的网站访问速度提升效果十分显著 ,这是一套开放源代码软件,以BSD license授权发布。
-
通过在内存中缓存数据和对象来减少读取数据库的次数,从而提高了网站访问的速度,MemCaChe是一个存储键值对的HashMap,在内存中对任意的数据(比如字符串、对象等)所使用的key-value存储,数据可以来自数据库调用、API调用,或者页面渲染的结果。MemCache设计理念就是小而强大,它简单的设计促进了快速部署、易于开发并解决面对大规模的数据缓存的许多难题,而所开放的API使得MemCache能用于Java、C/C++/C#、Perl、Python、PHP、Ruby等大部分流行的程序语言。
Memcache和memcached的区别:
Memcache是这个项目的名称,而memcached是它服务器端的主程序文件名。
MemCache访问模型
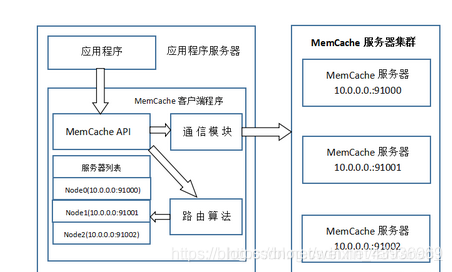
MemCache虽然被称为"分布式缓存",但是MemCache本身完全不具备分布式的功能,MemCache集群之间不会相互通信. 与之形成对比的,比如JBoss Cache,某台服务器有缓存数据更新时,会通知集群中其他机器更新缓存或清除缓存数据.所谓的"分布式",完全依赖于客户端程序的实现,就像上面这张图的流程一样
从上图,我们理出MemCache一次写缓存的流程:
-
应用程序输入需要写缓存的数据
-
API将Key输入路由算法模块,路由算法根据Key和MemCache集群服务器列表得到一台服务器编号
-
由服务器编号得到MemCache及其的ip地址和端口号
-
API调用通信模块和指定编号的服务器通信,将数据写入该服务器,完成一次分布式缓存的写操作、读缓存和写缓存一样,只要使用相同的路由算法和服务器列表,只要应用程序查询的是相同的Key,MemCache客户端总是访问相同的客户端去读取数据,只要服务器中还缓存着该数据,就能保证缓存命中
这种MemCache集群的方式也是从 分区容错性 的方面考虑的,假如Node2宕机了,那么Node2上面存储的数据都不可用了,此时由于集群中Node0和Node1还存在,下一次请求Node2中存储的Key值的时候,肯定是没有命中的,这时先从数据库中拿到要缓存的数据,然后路由算法模块根据Key值在Node0和Node1中选取一个节点,把对应的数据放进去,这样下一次就又可以走缓存了,这种集群的做法很好,但是缺点是成本比较大。
二、MemCache的工作流程
- 客户端把请求先发送给代理服务器(一般是nginx)
- 先检查客户端的请求数据是否在
memcached(MemCached是MemCache服务器端可以执行文件的名称)中,如有,直接把请求数据返回,不再对数据库进行任何操作 - 如果请求的数据不在memcached中,就去查数据库,把从数据库中获取的数据返回给客户端,同时把数据缓存一份到memcached中(memcached客户端不负责,需要程序明确实现)
- 每次更新数据库的同时更新memcached中的数据,保证一致性
- 当分配给memcached内存空间用完之后,会使用LRU(Least Recently
Used,最近最少使用)策略加上到期失效策略失效数据首先被替换,然后再替换掉最近未使用的数据
三、Memcache特性和限制
- 在 Memcached中可以保存的item数据量是没有限制的,只要内存足够 。
- memcached是一种无阻塞的socket通信方式服务,基于libevent库,由于无阻塞通信,对内存读写速度非常之快
- memcached分服务器端和客户端,可以配置多个服务器端和客户端,应用于分布式的服务非常广泛
四、为什么要使用Memcache ?
主要用于动态Web应用以减轻数据库的负载。它通过在内存中缓存数据和对象来减少读取数据库的次数,从而提高了网站访问的速度
memcache使用场景:
- 访问频繁的字典数据
- 大量的hot数据
- 页面缓存
- 频繁的查询条件和结果
- 临时处理的数据
五、MemCache对php页面的缓存加速优化
实验思想:
osi七层模型每一层都可以加上属于自己的缓存,现在我们
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 195
195











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









