







 本文介绍如何使用Python的requests和BeautifulSoup库抓取最好大学网的大学排名数据,包括数据处理、存储为CSV和Excel格式的完整过程。同时提供了使用XPath语法进行数据抓取的替代方案。
本文介绍如何使用Python的requests和BeautifulSoup库抓取最好大学网的大学排名数据,包括数据处理、存储为CSV和Excel格式的完整过程。同时提供了使用XPath语法进行数据抓取的替代方案。
问题描述
请使用 Python 爬取最好大学网的 大学排名数据 ,并保存为 CSV 和 Excel 格式。
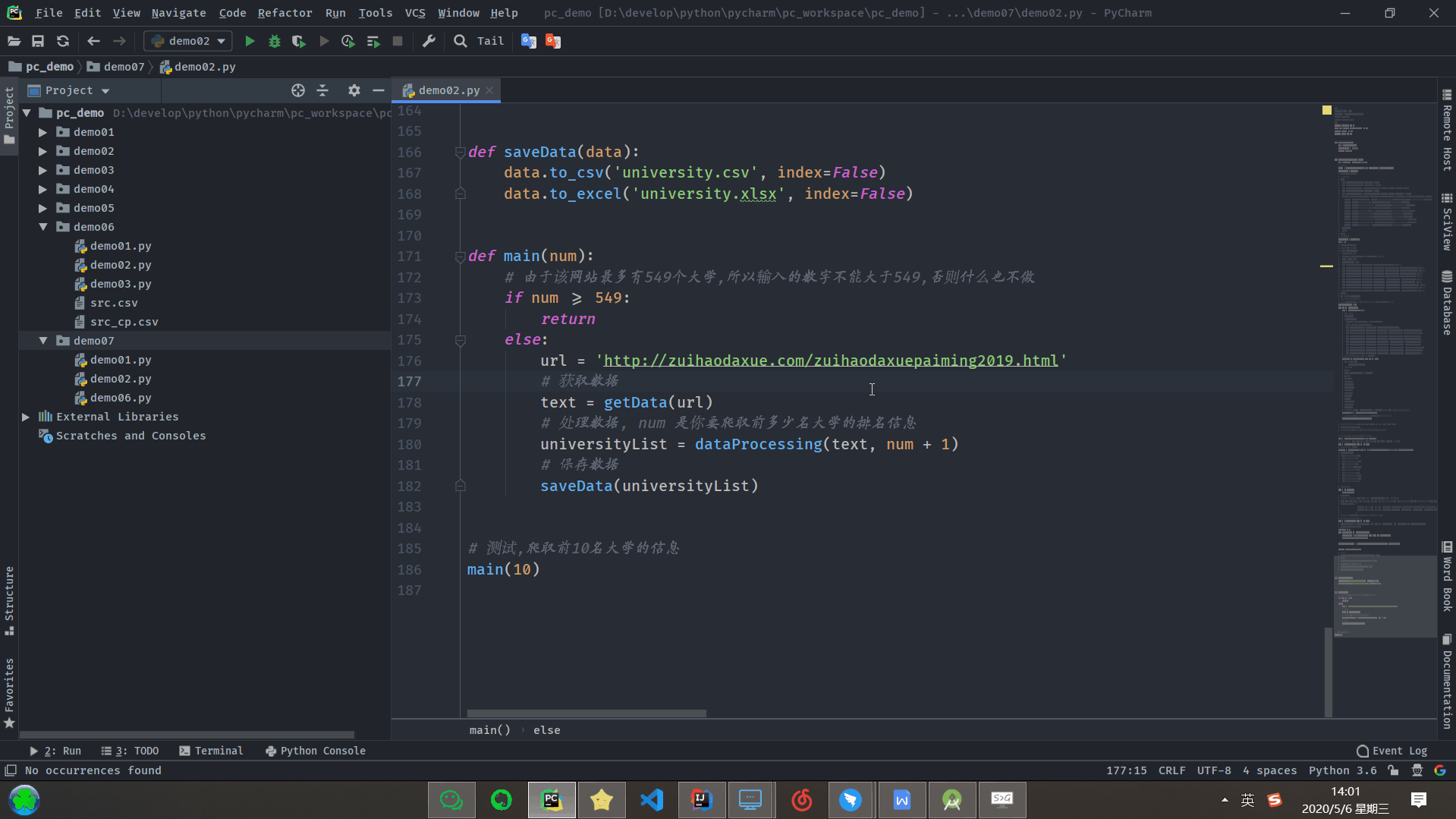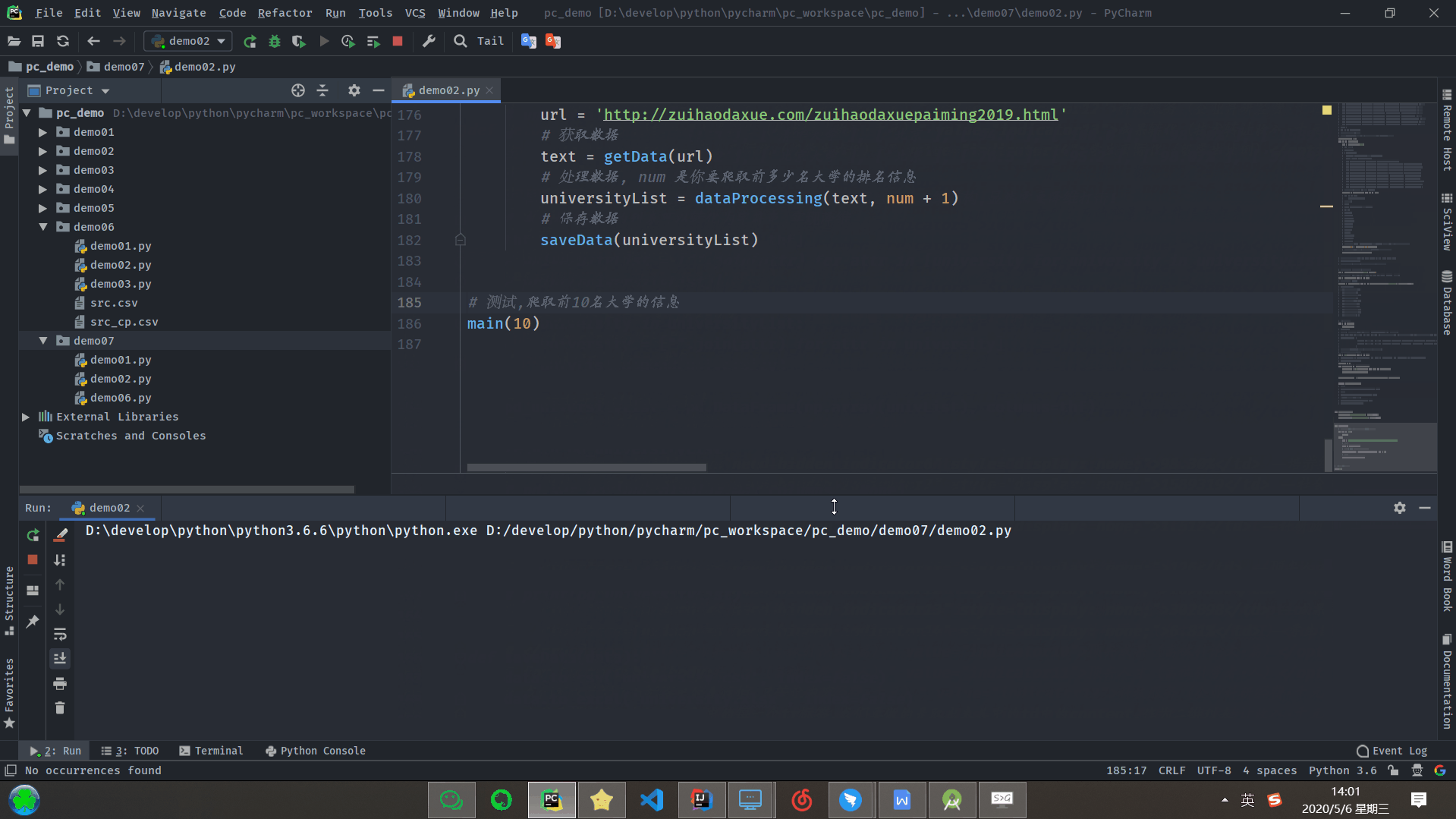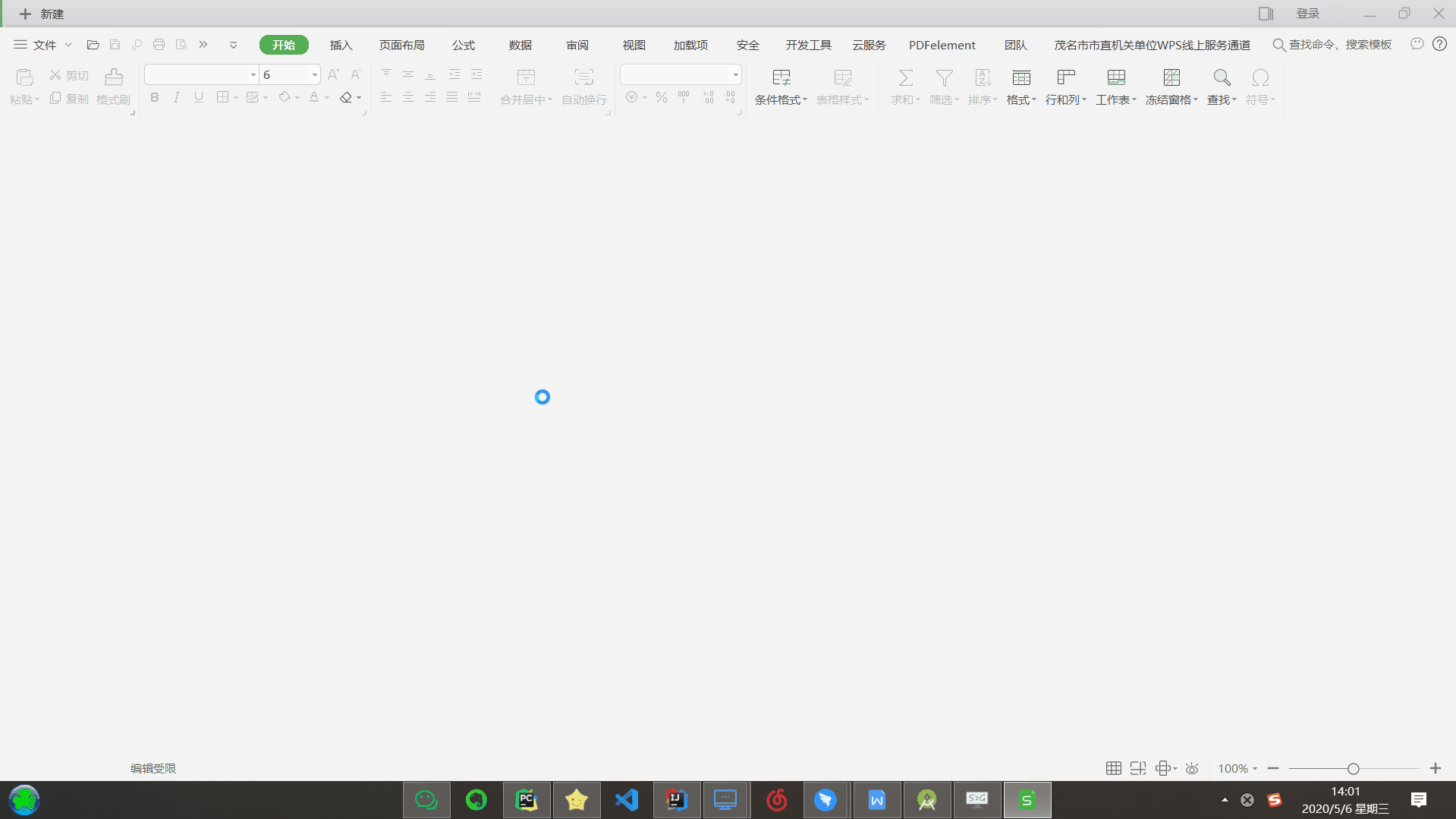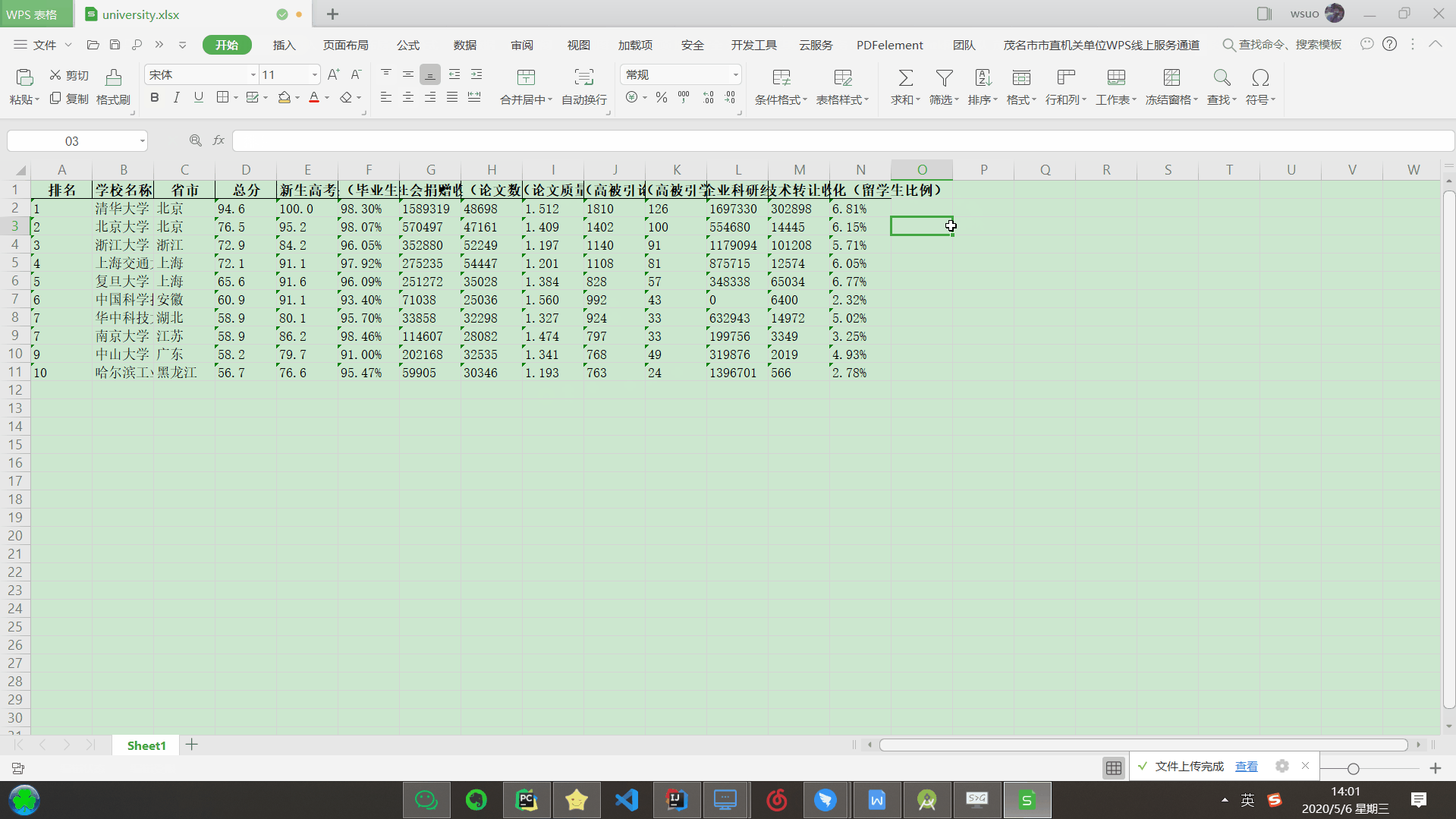
结果展示
以爬取前 10 名大学为例:
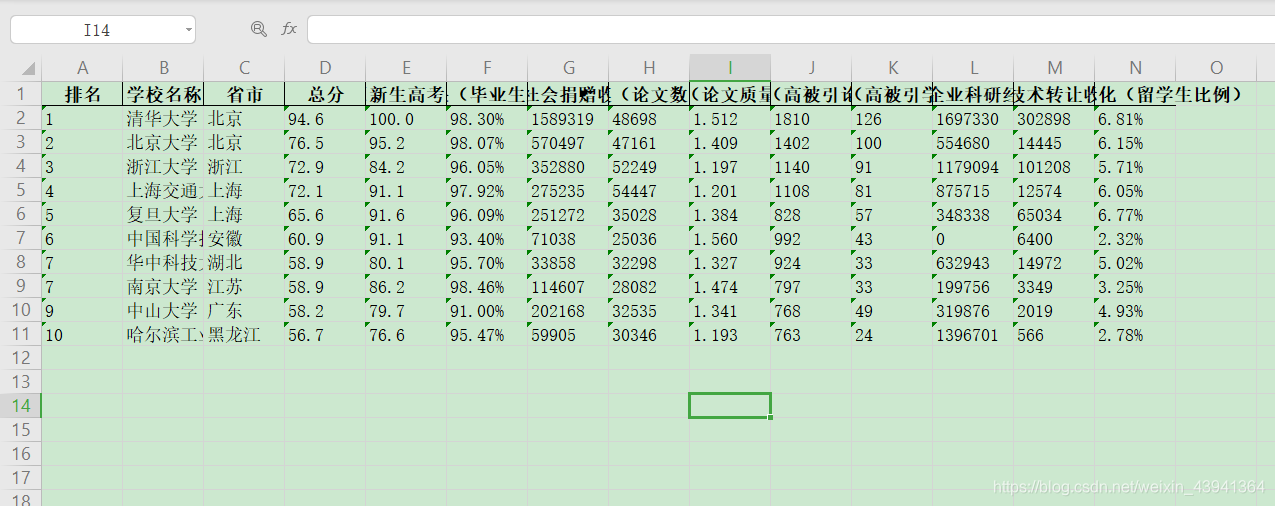
解决思路
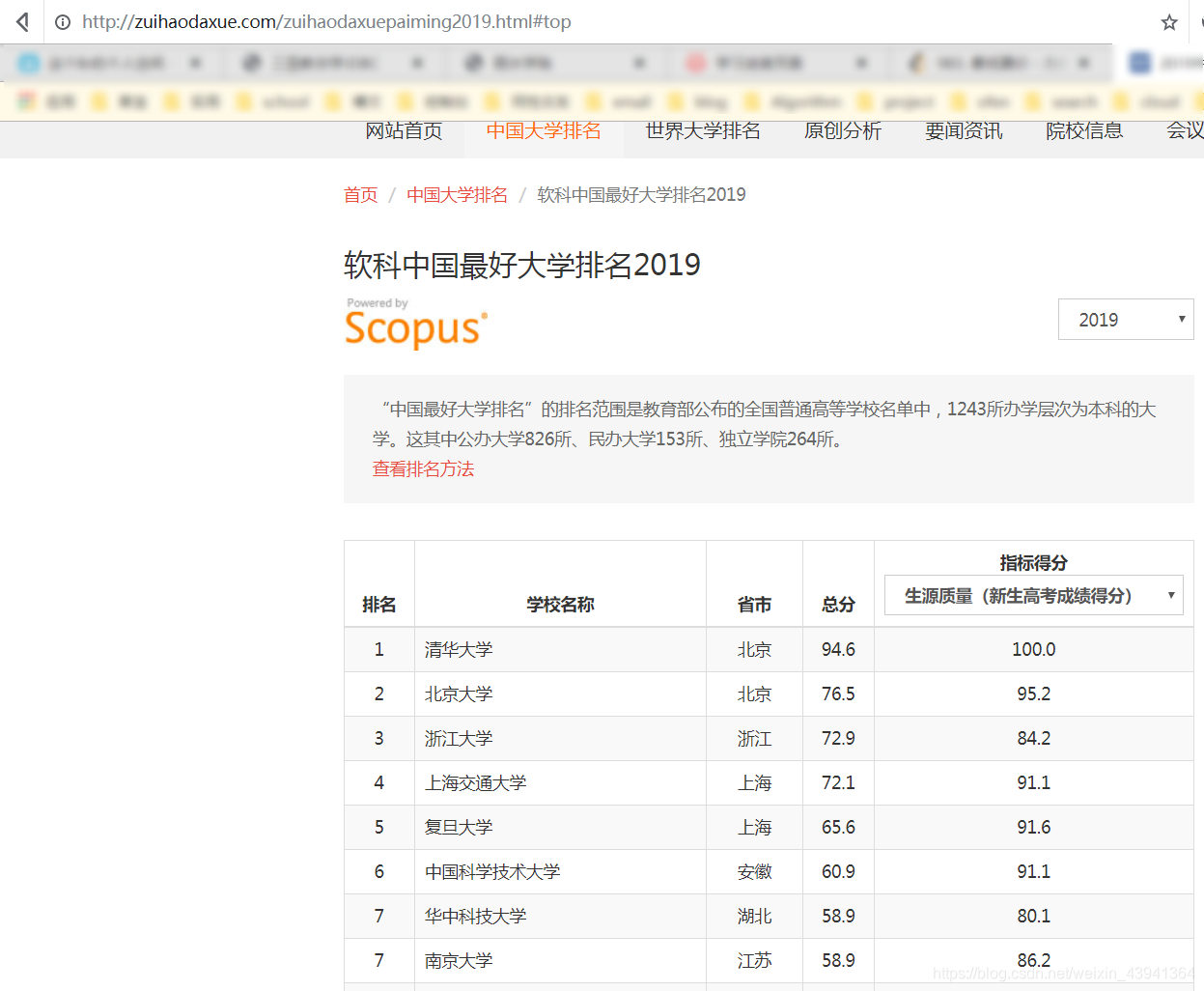
目标网站:软科中国最好大学排名2019
使用 Python 的 BeautifulSoup 库:BeautifulSoup官方文档
这里主要使用了 BeautifulSoup 库,该库功能十分强大,我只使用了它不到 1% 的功能。更多的功能请大家看官方文档,是中文的哦。
因为是使用爬虫,所以必须引入的两个库是:requests 和 BeautifulSoup,另外设计存储到 Excel 中,所以我选择使用 pandas 库,它的二维结构提供很方便的方法可以直接存储到 Excel 中,另外用到pandas就会用到numpy用来生成二维数组。
所以用到的库有:
- 🔥 requests
- 🔥 bs4
- 🔥 pandas
- 🔥 numpy
代码实现
import requests as rq
from bs4 import BeautifulSoup as Bs
import pandas as pd
import numpy as np
def getData(resLoc):
rp = rq.get(resLoc)
rp.encoding = 'utf-8'
return rp.text
def dataProcessing(html, num):
table = Bs(html, features='lxml').table.find_all('tr', limit=num, recursive=True)
table_head = table[0]
universityList = []
for tr in table[1:]:
tds = tr.find_all('td')
contents = [td.contents for td in tds]
contents[1] = contents[1][0].contents
universityList.append(contents)
thf = [th.contents for th in table_head.find_all('th', limit=4)]
for i in [op.contents for op in table_head.find_all('option', recursive=True)]:
thf.append(i)
thf = ["".join(th) for th in thf]
univList = []
for university in universityList:
university = ["".join(attr) for attr in university]
univList.append(university)
return pd.DataFrame(np.array(univList), columns=thf)
def saveData(data):
data.to_csv('university.csv', index=False)
data.to_excel('university.xlsx', index=False)
def main(num):
if num >= 549:
return
else:
url = 'http://zuihaodaxue.com/zuihaodaxuepaiming2019.html'
saveData(dataProcessing(getData(url), num + 1))
# 测试,爬取前 10 名大学的信息
main(10)
但是,相信大家看了上面的代码肯定想杀人,这代码的可读性几乎为0,根本不是写给人看的,所以下面我们讲解一下代码。
代码讲解
下面我采用注释的方式带大家一步一步的来解决这个问题,并且可以学到很多知识。
首先我们先导包:
import requests as rq
from bs4 import BeautifulSoup as Bs
import pandas as pd
import numpy as np
我们使用的 BeautifulSoup 是 bs4 中的一个类,所以我们引入该类就可以了,顺便起一个别名。
但是这个库实际上是叫做 beautifulsoup的,我们 install 的时候也是安装的 beautifulsoup ,但是执行的导包的时候是 bs4。
这里我们以一种自顶向下的思维编程,具体就是,先列出函数,函数具体怎么执行的我先不管,我只要你的返回值,然后我拿来使用。
所以我们先在 main 方法中定义一些函数,之后再实现。
def main(num):
# 由于该网站最多有550个大学,所以输入的数字不能大于550,否则什么也不做
if num >= 550:
print("数量不能大于550")
return
else:
url = 'http://zuihaodaxue.com/zuihaodaxuepaiming2019.html'
# 获取数据
text = getData(url)
# 处理数据, num 是你要爬取前多少名大学的排名信息
universityList = dataProcessing(text, num + 1)
# 保存数据
saveData(universityList)
print("文件保存成功!")
我们打开这个网站来看一下:
习惯上我们使用 F12 打开,也可以右键表格,点击检查:
我们需要的数据就在这里面:
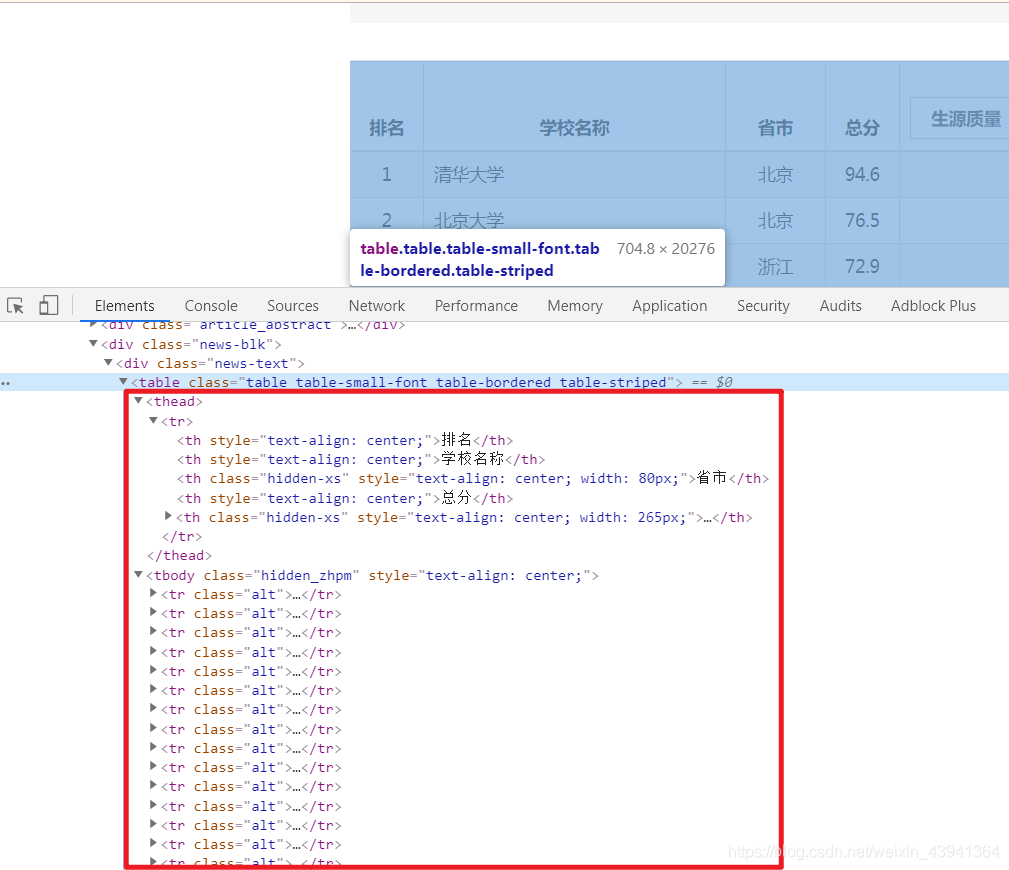
每一个 tr 里面都有一行数据,这就是我们想要的,而表头就是标题,我们后面都会用到。
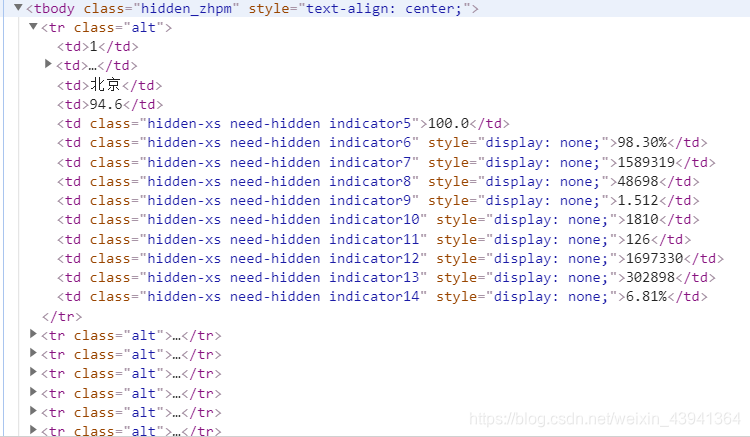
现在我们一个一个的实现这些函数:
首先是 getData(url) 方法,该方法就是通过程序获取我们在浏览器看到的 Html 页面。
# 获取数据,就是通过访问网页,把他的html源代码拿过来
def getData(resLoc):
rp = rq.get(resLoc)
rp.encoding = 'utf-8'
return rp.text
get 表示是 GET 请求,encoding 设置编码。
好了,获取了数据,我们就要分割处理数据了。
就是 dataProcessing(html, num) 方法,num 是爬取的大学数量。
首先创建一个 BeautifulSoup 对象:
bs = Bs(html, features='lxml')
然后呢,这个 bs 其实代表是整个 HTML 的 DOM 树,我们要做的就是从这个 DOM 树中取东西。
我们之前已经看过 HTML 的格式了,他只有一个 table 标签,所以我们可以通过点的方式获取这个 table 元素。
然后他返回的还是一个 bs 对象,只不过这个 DOM 树变小了,所以我们可以使用 find_all 方法来获取 table 下的所有 tr标签。
# 包含表头的列表
table = bs.table.find_all('tr', limit=num, recursive=True)
但是这里是有问题的,因为这张表有表头,表头的 tr我们需要单独拿出来。
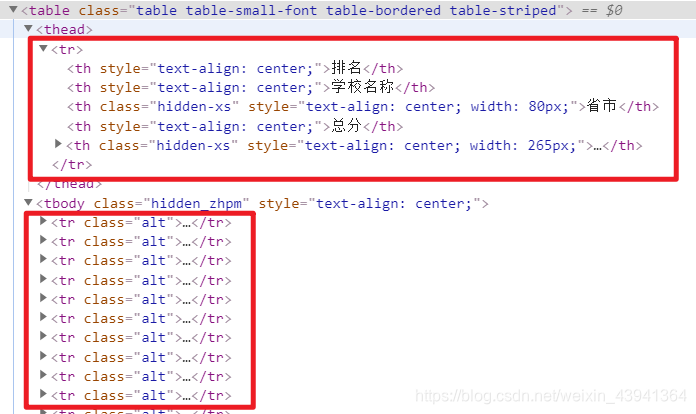
table_head = table[0]
print(table_head)
我们打印出来看一下表头是啥:
# 看一下表头是什么:
# <tr>
# <th style="text-align: center;">排名</th>
# <th style="text-align: center;">学校名称</th>
# <th class="hidden-xs" style="text-align: center; width: 80px;">省市</th>
# <th style="text-align: center;">总分</th>
# <th class="hidden-xs" style="text-align: center; width: 265px;">指标得分<br/>
# <select class="form-control" id="select-indicator-type" name="type" style="text-align: left;">
# <option selected="selected" title="生源质量(新生高考成绩得分)" value="indicator5">生源质量(新生高考成绩得分)</option>
# <option title="培养结果(毕业生就业率)" value="indicator6">培养结果(毕业生就业率)</option>
# <option title="社会声誉(社会捐赠收入·千元)" value="indicator7">社会声誉(社会捐赠收入·千元)</option>
# <option title="科研规模(论文数量·篇)" value="indicator8">科研规模(论文数量·篇)</option>
# <option title="科研质量(论文质量·FWCI)" value="indicator9">科研质量(论文质量·FWCI)</option>
# <option title="顶尖成果(高被引论文·篇)" value="indicator10">顶尖成果(高被引论文·篇)</option>
# <option title="顶尖人才(高被引学者·人)" value="indicator11">顶尖人才(高被引学者·人)</option>
# <option title="科技服务(企业科研经费·千元)" value="indicator12">科技服务(企业科研经费·千元)</option>
# <option title="成果转化(技术转让收入·千元)" value="indicator13">成果转化(技术转让收入·千元)</option>
# <option title="学生国际化(留学生比例) " value="indicator14">学生国际化(留学生比例)</option>
# </select>
# </th>
# </tr>
这正是我们想要的数据,我们可以通过 contents 获取 标签对 里面的数据,就大功告成了。
# 这里为什么只要四个呢? 因为第五个是下拉选框,我们后面再单独处理
ths = table_head.find_all('th', limit=4)
# 这里是表头的前四个元素 [['排名'], ['学校名称'], ['省市'], ['总分']], th_four 代表前四个th
thf = [th.contents for th in ths]
在仔细看你会发现后面有一个不是普通的列表,他是一个 select!所以我们上面只要了前四个。

下面处理下拉框中的元素 option;
options = [op.contents for op in table_head.find_all('option', recursive=True)]
打印出来看看:
# [ ['生源质量(新生高考成绩得分)'],
# ['培养结果(毕业生就业率)'],
# ['社会声誉(社会捐赠收入·千元)'],
# ['科研规模(论文数量·篇)'],
# ['科研质量(论文质量·FWCI)'],
# ['顶尖成果(高被引论文·篇)'],
# ['顶尖人才(高被引学者·人)'],
# ['科技服务(企业科研经费·千元)'],
# ['成果转化(技术转让收入·千元)'],
# ['学生国际化(留学生比例)'] ]
正是我们想要的,不过他是二维列表,不怕后面我们再处理。
将这个和之前的 4 个合并。
for i in options:
thf.append(i)
现在我们处理表体,也就是最最干货的内容。
# 去掉表头,只要表体
table_body = table[1:]
打印出来看一下每一条 tr 里面是什么?
# [ <tr class="alt">
# <td>1</td> --排名
# <td><div align="left">清华大学</div></td> --学校名称
# <td>北京</td> --省市
# <td>94.6</td> --总分
# <td class="hidden-xs need-hidden indicator5">100.0</td> --生源质量
# <td class="hidden-xs need-hidden indicator6" style="display: none;">98.30%</td> --培养结果
# <td class="hidden-xs need-hidden indicator7" style="display: none;">1589319</td> --社会声誉
# <td class="hidden-xs need-hidden indicator8" style="display: none;">48698</td> --科研规模
# <td class="hidden-xs need-hidden indicator9" style="display: none;">1.512</td> --科研质量
# <td class="hidden-xs need-hidden indicator10" style="display: none;">1810</td> --顶尖成果
# <td class="hidden-xs need-hidden indicator11" style="display: none;">126</td> --顶尖人才
# <td class="hidden-xs need-hidden indicator12" style="display: none;">1697330</td> --科技服务
# <td class="hidden-xs need-hidden indicator13" style="display: none;">302898</td> --成果转化
# <td class="hidden-xs need-hidden indicator14" style="display: none;">6.81%</td> --学生国际化
# </tr> ]
我们可以无视上面标签中的属性值,只关注内容,也就是说对于table_body中的每一个tr标签,我们要做的是取出来其中的td中的content,作为二维列表。
编写一个循环来遍历每一个 tr:
universityList = []
for tr in table_body:
tds = tr.find_all('td')
这个时候我们打印一下tds看看:
# tds 的结果是:
# print(tds)
# [ <td>1</td>,
# <td><div align="left">清华大学</div></td>,
# <td>北京</td>, <td>94.6</td>,
# <td class="hidden-xs need-hidden indicator5">100.0</td>,
# <td class="hidden-xs need-hidden indicator6" style="display: none;">98.30%</td>,
# <td class="hidden-xs need-hidden indicator7" style="display: none;">1589319</td>,
# <td class="hidden-xs need-hidden indicator8" style="display: none;">48698</td>,
# <td class="hidden-xs need-hidden indicator9" style="display: none;">1.512</td>,
# <td class="hidden-xs need-hidden indicator10" style="display: none;">1810</td>,
# <td class="hidden-xs need-hidden indicator11" style="display: none;">126</td>,
# <td class="hidden-xs need-hidden indicator12" style="display: none;">1697330</td>,
# <td class="hidden-xs need-hidden indicator13" style="display: none;">302898</td>,
# <td class="hidden-xs need-hidden indicator14" style="display: none;">6.81%</td> ]
可以看到是一个列表,我们获取每一个 td 标签的 content:
contents = [td.contents for td in tds]
# for td in tds:
# print(td.contents)
# 得到的结果如下:
# ['1']
# [<div align="left">清华大学</div>]
# ['北京']
# ['94.6']
# ['100.0']
# ['98.30%']
# ['1589319']
# ['48698']
# ['1.512']
# ['1810']
# ['126']
# ['1697330']
# ['302898']
# ['6.81%']
但是有一个问题就是 [<div align="left">清华大学</div>] 这里有一个 div 标签,我们要把它替换成他里面的元素值。
contents[1] = contents[1][0].contents
大家注意我们现在还在for循环当中哦,我们要这些遍历到的contents存到外面的变量中才能保存起来
universityList.append(contents)
现在我们得到的列表就是类似于这种形式[[[清华], [1], ...], [[北大], [2], ...], ...]
降维打击!
# 下面的问题是, 我们有了表头列表 thf(二维),有了表体列表 universityList(三维), 怎么把它们合并呢?
# thf: [['排名'], ['学校名称'], ['省市'], ['总分'], ['生源质量(新生高考成绩得分)'], ['培养结果(毕业生就业率)'], ['社会声誉(社会捐赠收入·千元)'], ['科研规模(论文数量·篇)'], ['科研质量(论文质量·FWCI)'], ['顶尖成果(高被引论文·篇)'], ['顶尖人才(高被引学者·人)'], ['科技服务(企业科研经费·千元)'], ['成果转化(技术转让收入·千元)'], ['学生国际化(留学生比例)']]
# universityList: [
# [['1'], ['清华大学'], ['北京'], ['94.6'], ['100.0'], ['98.30%'], ['1589319'], ['48698'], ['1.512'], ['1810'], ['126'], ['1697330'], ['302898'], ['6.81%']],
# [['2'], ['北京大学'], ['北京'], ['76.5'], ['95.2'], ['98.07%'], ['570497'], ['47161'], ['1.409'], ['1402'], ['100'], ['554680'], ['14445'], ['6.15%']]
# ]
我们使用 DataFrame配合 numpy 可以实现这个功能,因为DataFrame有一个功能就是可以将几行和一列数据一一对应形成一个表格。
# 但是还有一个问题就是DataFrame是二维结构,我们这里是三维结构,显然需要降维打击!
# 我们把最里面的列表可以转化为字符串,实现降维
# 降维的过程
thf = ["".join(th) for th in thf]
univList = []
for university in universityList:
university = ["".join(attr) for attr in university]
univList.append(university)
# 下面使用 DataFrame 的构造函数,传入一个 numpy 构造的数组和一个列表作为表头
pd_universityList = pd.DataFrame(np.array(univList), columns=thf)
return pd_universityList
上面的代码值得一提的就是这一个pd.DataFrame(np.array(univList), columns=thf),这里先是传入了一个二维数组,然后第二个参数columns指的就是表头,也就是说他会形成一种一一对应的关系,columns的每一个元素,对应二维数组的每一个元素的对应元素。
比如说我们的二维数组是:
1,清华大学,北京
2,北京大学,北京
那么columns对应的就是排名,学校名称,省市,他会自动将排名和1,2对应,学校和清华大学对应。
在调试的过程中可能 DataFrame 显示不全,可以采用下面的方法显示全。
# 显示所有列
# pd.set_option('display.max_columns', None)
# 显示所有行
# pd.set_option('display.max_rows', None)
# 设置value的显示长度为100,默认为50
# pd.set_option('max_colwidth', 100)
# print(pd_universityList)
到此为止,我们最重要的方法就介绍完了,下面我们编写第三个函数吧。
# 负责保存数据到本地磁盘
def saveData(data):
data.to_csv('university.csv', index=False)
data.to_excel('university.xlsx', index=False)
这里直接使用DataFrame自带的方法就可以实现保存到本地。
好了,全部都做完了,下面我们只需要调用一下主函数即可运行程序。
输入几就可以获取前几名大学的数据,但是不能超过550,因为那网页上就只有549个 。
# 测试,爬取前10名大学的信息
main(10)
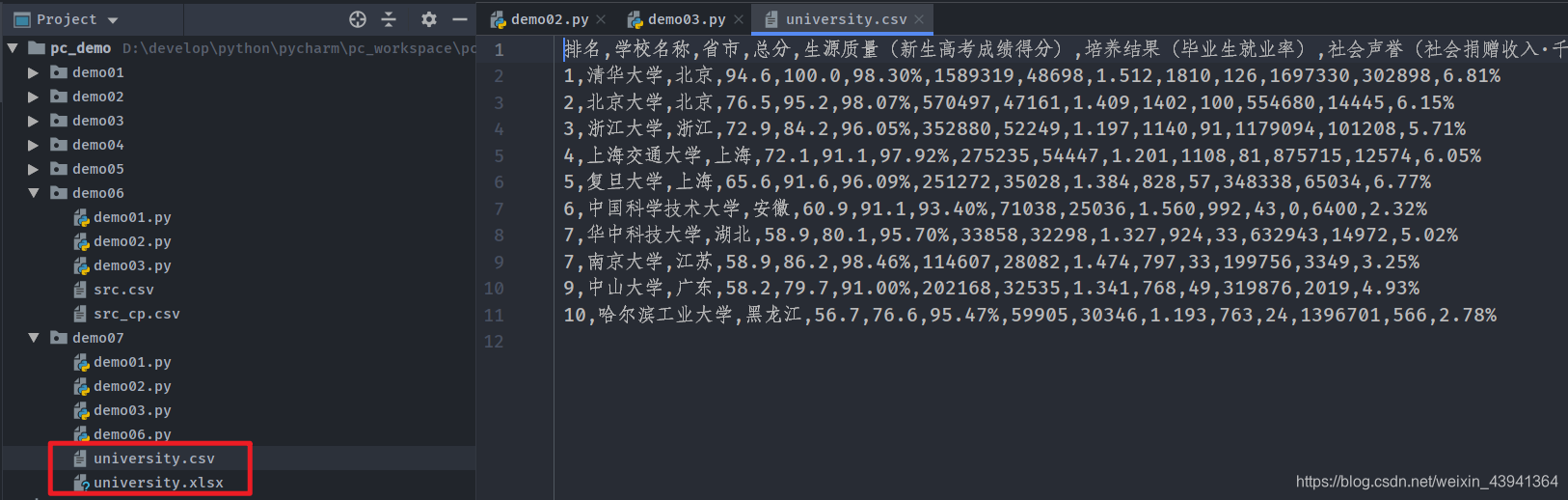
带注释的代码展示:
"""
@author: shoo Wang
@contact: wangsuoo@foxmail.com
@file: demo02.py
@time: 2020/5/6 0006
"""
import requests as rq
from bs4 import BeautifulSoup as Bs
import pandas as pd
import numpy as np
# 获取数据,就是通过访问网页,把他的html源代码拿过来
def getData(resLoc):
rp = rq.get(resLoc)
rp.encoding = 'utf-8'
return rp.text
# 最关键的部分: 数据处理,我们的目标是将文本格式的 html 网页转化为表格的形式;
def dataProcessing(html, num):
bs = Bs(html, features='lxml')
# 包含表头的列表
table = bs.table.find_all('tr', limit=num, recursive=True)
table_head = table[0]
# print(table_head)
# 看一下表头是什么:
# <tr>
# <th style="text-align: center;">排名</th>
# <th style="text-align: center;">学校名称</th>
# <th class="hidden-xs" style="text-align: center; width: 80px;">省市</th>
# <th style="text-align: center;">总分</th>
# <th class="hidden-xs" style="text-align: center; width: 265px;">指标得分<br/>
# <select class="form-control" id="select-indicator-type" name="type" style="text-align: left;">
# <option selected="selected" title="生源质量(新生高考成绩得分)" value="indicator5">生源质量(新生高考成绩得分)</option>
# <option title="培养结果(毕业生就业率)" value="indicator6">培养结果(毕业生就业率)</option>
# <option title="社会声誉(社会捐赠收入·千元)" value="indicator7">社会声誉(社会捐赠收入·千元)</option>
# <option title="科研规模(论文数量·篇)" value="indicator8">科研规模(论文数量·篇)</option>
# <option title="科研质量(论文质量·FWCI)" value="indicator9">科研质量(论文质量·FWCI)</option>
# <option title="顶尖成果(高被引论文·篇)" value="indicator10">顶尖成果(高被引论文·篇)</option>
# <option title="顶尖人才(高被引学者·人)" value="indicator11">顶尖人才(高被引学者·人)</option>
# <option title="科技服务(企业科研经费·千元)" value="indicator12">科技服务(企业科研经费·千元)</option>
# <option title="成果转化(技术转让收入·千元)" value="indicator13">成果转化(技术转让收入·千元)</option>
# <option title="学生国际化(留学生比例) " value="indicator14">学生国际化(留学生比例)</option>
# </select>
# </th>
# </tr>
# 去掉表头,只要表体
table_body = table[1:]
# print(table_body)
# 看一下每一条 tr 里面是什么?
# [ <tr class="alt">
# <td>1</td> --排名
# <td><div align="left">清华大学</div></td> --学校名称
# <td>北京</td> --省市
# <td>94.6</td> --总分
# <td class="hidden-xs need-hidden indicator5">100.0</td> --生源质量
# <td class="hidden-xs need-hidden indicator6" style="display: none;">98.30%</td> --培养结果
# <td class="hidden-xs need-hidden indicator7" style="display: none;">1589319</td> --社会声誉
# <td class="hidden-xs need-hidden indicator8" style="display: none;">48698</td> --科研规模
# <td class="hidden-xs need-hidden indicator9" style="display: none;">1.512</td> --科研质量
# <td class="hidden-xs need-hidden indicator10" style="display: none;">1810</td> --顶尖成果
# <td class="hidden-xs need-hidden indicator11" style="display: none;">126</td> --顶尖人才
# <td class="hidden-xs need-hidden indicator12" style="display: none;">1697330</td> --科技服务
# <td class="hidden-xs need-hidden indicator13" style="display: none;">302898</td> --成果转化
# <td class="hidden-xs need-hidden indicator14" style="display: none;">6.81%</td> --学生国际化
# </tr> ]
# for tr in table_body:
# 我们可以无视上面标签中的属性值,只关注内容
# 也就是说对于table_body中的每一个tr标签,我们要做的是取出来其中的td中的content,作为二维列表
universityList = []
for tr in table_body:
tds = tr.find_all('td')
# tds 的结果是:
# print(tds)
# [ <td>1</td>,
# <td><div align="left">清华大学</div></td>,
# <td>北京</td>, <td>94.6</td>,
# <td class="hidden-xs need-hidden indicator5">100.0</td>,
# <td class="hidden-xs need-hidden indicator6" style="display: none;">98.30%</td>,
# <td class="hidden-xs need-hidden indicator7" style="display: none;">1589319</td>,
# <td class="hidden-xs need-hidden indicator8" style="display: none;">48698</td>,
# <td class="hidden-xs need-hidden indicator9" style="display: none;">1.512</td>,
# <td class="hidden-xs need-hidden indicator10" style="display: none;">1810</td>,
# <td class="hidden-xs need-hidden indicator11" style="display: none;">126</td>,
# <td class="hidden-xs need-hidden indicator12" style="display: none;">1697330</td>,
# <td class="hidden-xs need-hidden indicator13" style="display: none;">302898</td>,
# <td class="hidden-xs need-hidden indicator14" style="display: none;">6.81%</td> ]
# 可以看到是一个列表,我们获取每一个 td 标签的 content
contents = [td.contents for td in tds]
# for td in tds:
# print(td.contents)
# 得到的结果如下:
# ['1']
# [<div align="left">清华大学</div>]
# ['北京']
# ['94.6']
# ['100.0']
# ['98.30%']
# ['1589319']
# ['48698']
# ['1.512']
# ['1810']
# ['126']
# ['1697330']
# ['302898']
# ['6.81%']
# 但是有一个问题就是 [<div align="left">清华大学</div>] 这里有一个 div 标签,我们要把它替换成他里面的元素值
contents[1] = contents[1][0].contents
# 大家注意我们现在还在for循环当中哦,我们要这些遍历到的contents存到外面的变量中才能保存起来
universityList.append(contents)
# 现在我们得到的列表就是类似于这种形式[[[清华], [1], ...], [[北大], [2], ...], ...]
# print(universityList)
# 但是现在还没有把表头加上,现在我们加上表头,但是表头还是那个乱七八糟的形式,所以我们要先处理一下
# 这里为什么只要四个呢? 因为第五个是下拉选框,我们后面再单独处理
ths = table_head.find_all('th', limit=4)
# 这里是表头的前四个元素 [['排名'], ['学校名称'], ['省市'], ['总分']], th_four 代表前四个th
thf = [th.contents for th in ths]
# 下面处理下拉框中的元素 option
options = [op.contents for op in table_head.find_all('option', recursive=True)]
# print(options)
# [ ['生源质量(新生高考成绩得分)'],
# ['培养结果(毕业生就业率)'],
# ['社会声誉(社会捐赠收入·千元)'],
# ['科研规模(论文数量·篇)'],
# ['科研质量(论文质量·FWCI)'],
# ['顶尖成果(高被引论文·篇)'],
# ['顶尖人才(高被引学者·人)'],
# ['科技服务(企业科研经费·千元)'],
# ['成果转化(技术转让收入·千元)'],
# ['学生国际化(留学生比例)'] ]
# 好了,现在我们合并表头
for i in options:
thf.append(i)
# print(thf)
# 下面的问题是, 我们有了表头列表 thf(二维),有了表体列表 universityList(三维), 怎么把它们合并呢?
# thf: [['排名'], ['学校名称'], ['省市'], ['总分'], ['生源质量(新生高考成绩得分)'], ['培养结果(毕业生就业率)'], ['社会声誉(社会捐赠收入·千元)'], ['科研规模(论文数量·篇)'], ['科研质量(论文质量·FWCI)'], ['顶尖成果(高被引论文·篇)'], ['顶尖人才(高被引学者·人)'], ['科技服务(企业科研经费·千元)'], ['成果转化(技术转让收入·千元)'], ['学生国际化(留学生比例)']]
# universityList: [
# [['1'], ['清华大学'], ['北京'], ['94.6'], ['100.0'], ['98.30%'], ['1589319'], ['48698'], ['1.512'], ['1810'], ['126'], ['1697330'], ['302898'], ['6.81%']],
# [['2'], ['北京大学'], ['北京'], ['76.5'], ['95.2'], ['98.07%'], ['570497'], ['47161'], ['1.409'], ['1402'], ['100'], ['554680'], ['14445'], ['6.15%']]
# ]
# 但是还有一个问题就是DataFrame是二维结构,我们这里是三维结构,显然需要降维打击!
# 我们把最里面的列表可以转化为字符串,实现降维
thf = ["".join(th) for th in thf]
# universityList = ["".join(attr) for attr in [university for university in universityList]]
# print(universityList)|
univList = []
for university in universityList:
university = ["".join(attr) for attr in university]
univList.append(university)
pd_universityList = pd.DataFrame(np.array(univList), columns=thf)
return pd_universityList
# 显示所有列
# pd.set_option('display.max_columns', None)
# 显示所有行
# pd.set_option('display.max_rows', None)
# 设置value的显示长度为100,默认为50
# pd.set_option('max_colwidth', 100)
# print(pd_universityList)
# 负责保存数据到本地磁盘
def saveData(data):
data.to_csv('university.csv', index=False)
data.to_excel('university.xlsx', index=False)
def main(num):
# 由于该网站最多有550个大学,所以输入的数字不能大于550,否则什么也不做
if num >= 550:
print("数量不能大于550")
return
else:
url = 'http://zuihaodaxue.com/zuihaodaxuepaiming2019.html'
# 获取数据
text = getData(url)
# 处理数据, num 是你要爬取前多少名大学的排名信息
universityList = dataProcessing(text, num + 1)
# 保存数据
saveData(universityList)
print("文件保存成功!")
# 测试,爬取前10名大学的信息
main(10)
总结一下
最重要的还是看 文档,我这里只用了一个方法就是find_all,他还有非常多强大的功能,我们只需要会使用就行了,我太 CAI 了,只是一个 API 选手,你敢信就这几行代码我扣了俩小时才写出来😔,还是得更努力的学,虽然学到最后还只是一个 API 调用者。
会这一个方法就可以爬一些网站的数据了,其他的也是以此类推,只需要分析另一个网页的 DOM 结构即可,所以方法是通用的,如果你也是初学,不妨使用这个项目练练手。
使用 XPath 实现
从http://www.zuihaodaxue.cn/网站中爬虫数据,获取中国大学排名(Top10)
- 爬取的数据保存为
CSV文件(.CSV) - 采用
xpath语法提取数据
"""
@author: shoo Wang
@contact: wangsuoo@foxmail.com
@file: demo01.py
@time: 2020/5/11 0011
"""
import requests as rq
from lxml import etree
import pandas as pd
import numpy as np
# 获取数据,就是通过访问网页,把他的html源代码拿过来
def getData(resLoc):
rp = rq.get(resLoc)
rp.encoding = 'utf-8'
return rp.text
# 最关键的部分: 数据处理,我们的目标是将文本格式的 html 网页转化为表格的形式;
def dataProcessing(html, num):
html = etree.HTML(html)
# 获取表头 //thead//th[position() < 5] //thead//option
th = html.xpath('//thead//th[position() < 5]/text()')
th_select = html.xpath('//thead//option/text()')
th.extend(th_select)
# 大学名称
univ = html.xpath('//tbody/tr/td/div/text()')[:num]
# //tbody/tr[1]/td/text() 获取每一条记录的数值
nums = [[j for j in html.xpath('//tbody/tr[' + str(i + 1) + ']/td/text()')] for i in range(num)]
idx = 0
for num in nums:
num.insert(1, univ[idx])
idx += 1
# 转化为 DataFrame 结构,因为这种结构很好转化为 Excel
pd_universityList = pd.DataFrame(np.array(nums), columns=th)
return pd_universityList
# 负责保存数据到本地磁盘
def saveData(data):
data.to_csv('university_china.csv', index=False)
def main(num):
# 由于该网站最多有 1000 个大学,所以输入的数字不能大于 1000 ,否则什么也不做
if num >= 1000:
print("数量不能大于1000")
return
else:
url = 'http://zuihaodaxue.com/zuihaodaxuepaiming2019.html'
universityList = dataProcessing(getData(url), num)
saveData(universityList)
print("文件保存成功!")
# 测试,爬取前10名大学的信息
main(10)



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











