







这个网站可以形象的把正则表达式以图形的形式展现出来
先来一波正则简介
平时我们在sql语句中的 * 其实就是正则表达式
还有linux中查找文件 find ./ -name *.txt 也是正则表达式
简单的以数字开头
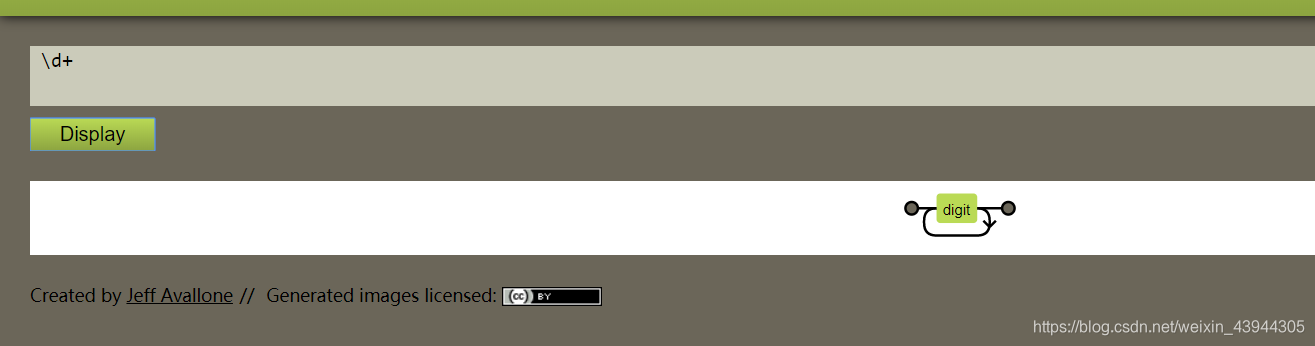
/d
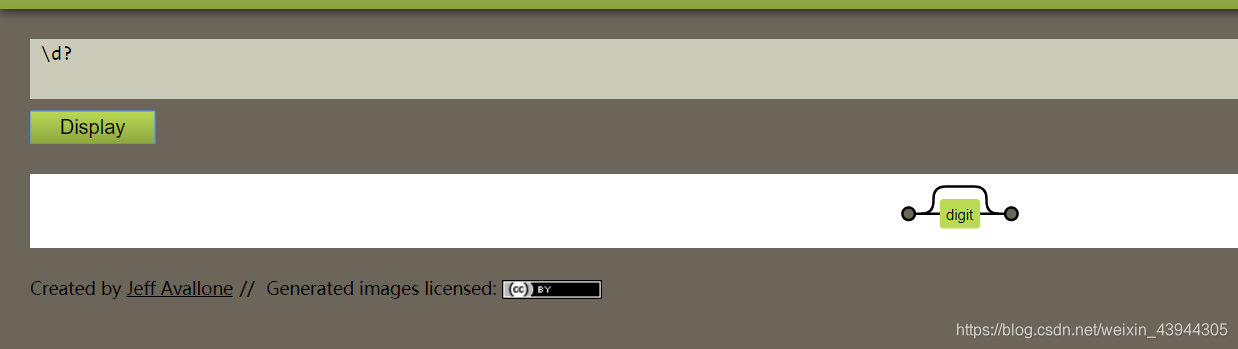
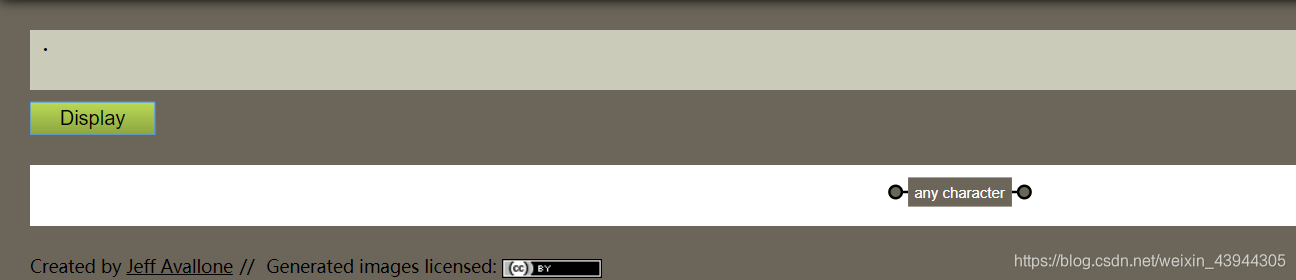
后面可以跟 * , + , ? , . 分别是任意次数,一次或多次,0或1次,任意字符
转义字符和其他语言一样也是反斜杠 \
或者用 中括号标识[ ]
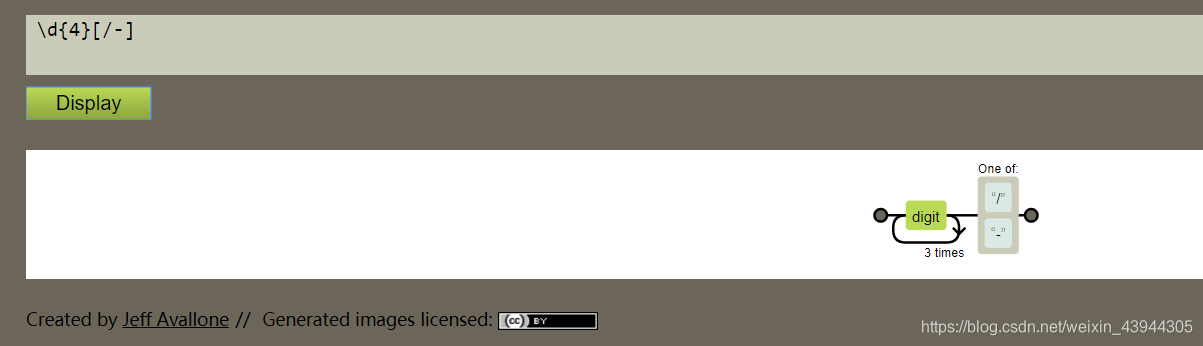
[/-]代表 / 或者 - 字符
\d{4}[/-]代表4个数字后接 / 或者 -
代表开头和结尾分别是 ^ 和 $
例如,下面筛选时间的正则
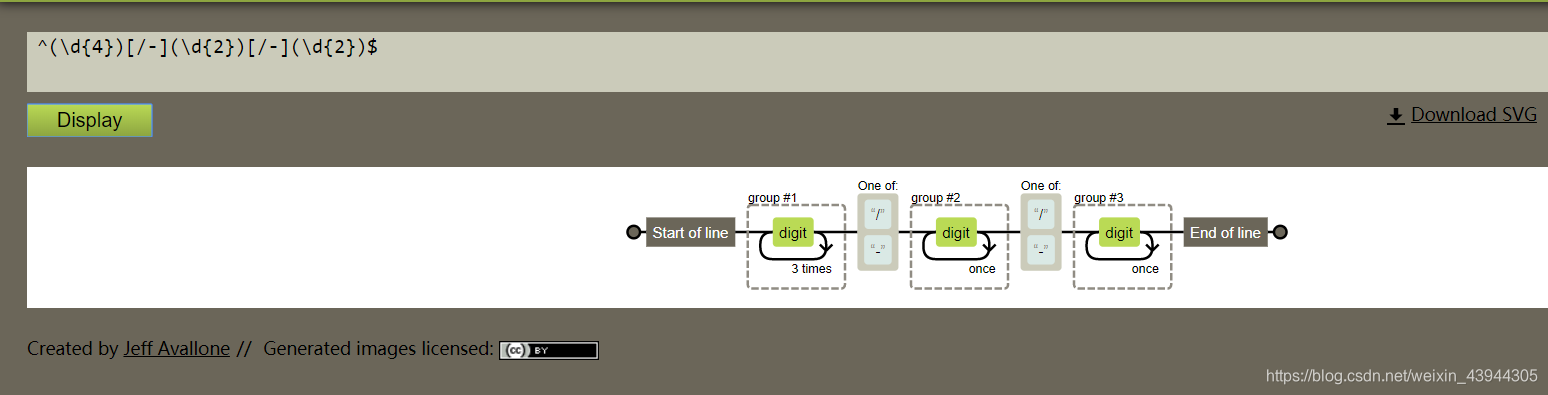
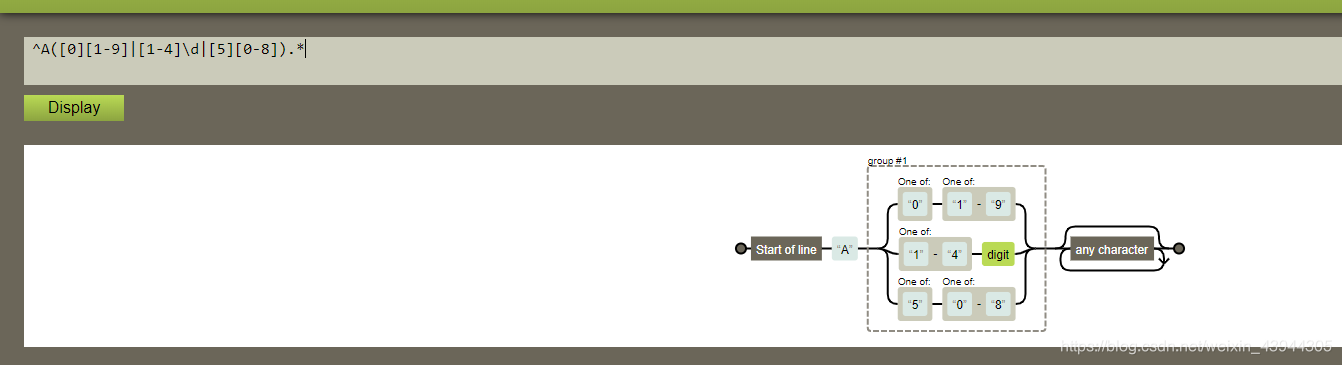
^\d{4}[/-]\d{2}[/-]\d{2}$
代表以4个数字开头,接/或者-,接2个数字,接/或者-,接2个数字结尾
获取筛选到的内容用(),可以看下面的日期和字符替换操作
* , + , ? , . 在上面网站中的图形分别是

是不是很形象
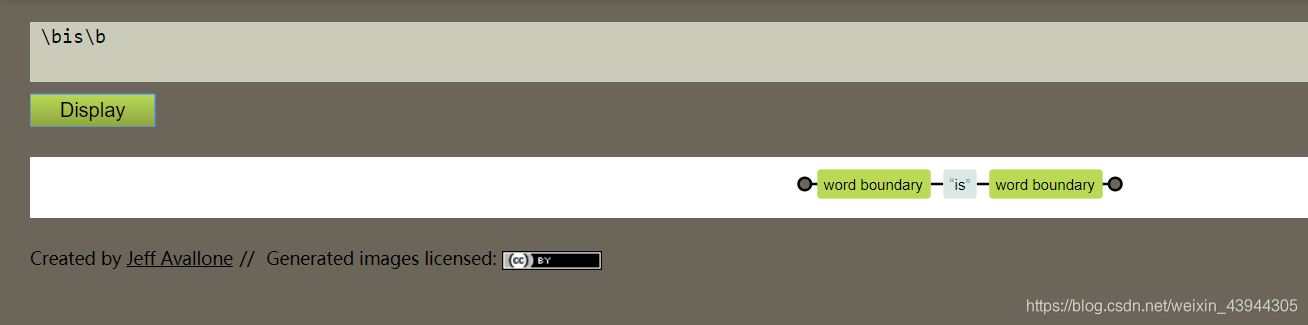
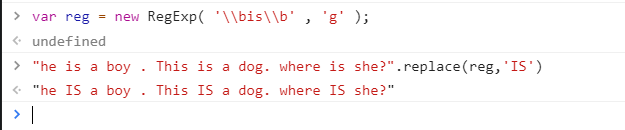
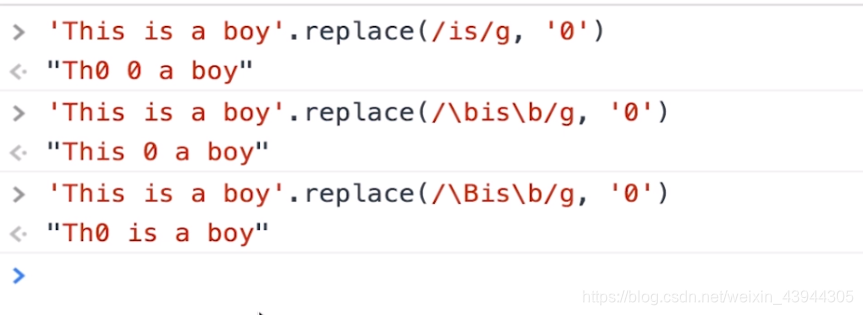
根据单词边界\b匹配单词
\b代表单词的边界
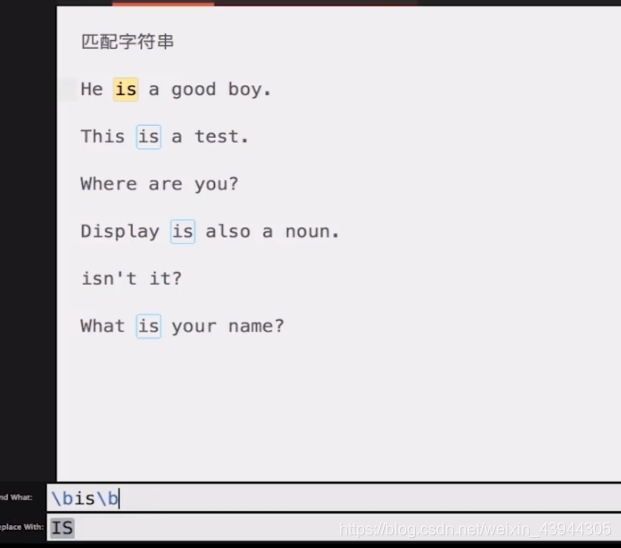
\bis\b代表只匹配小写的is,并且是单个is单词,而不是某一个单词中的is
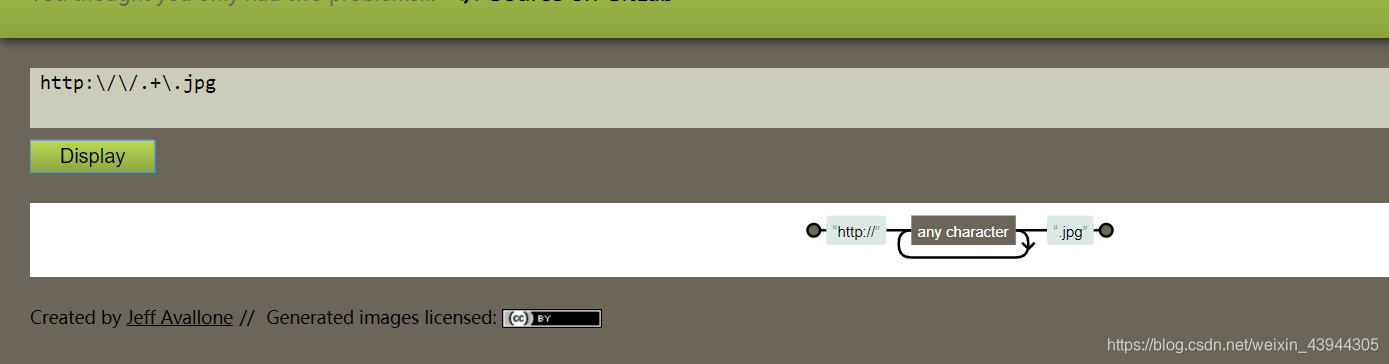
筛选以某个字符开头,某个字符结尾的字符串
如下图要求,
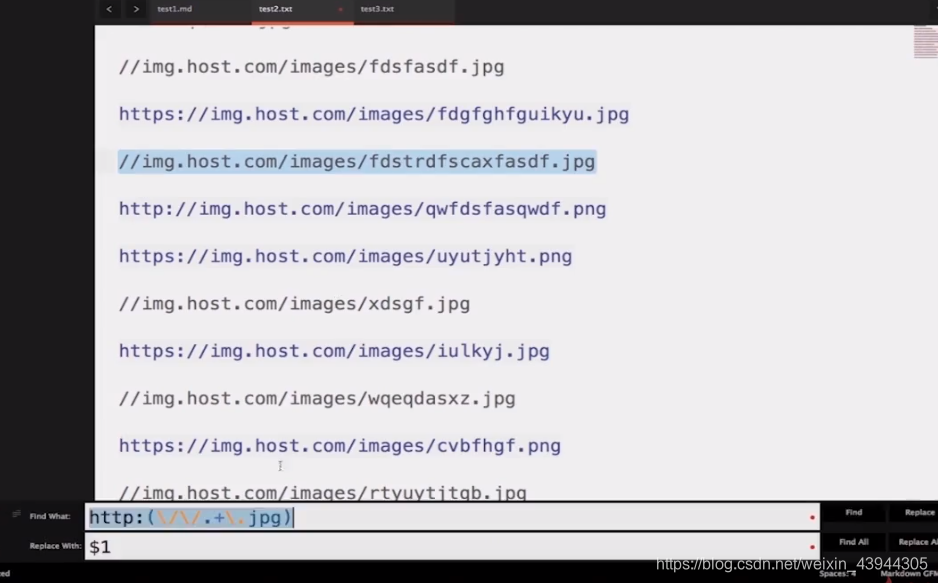
http://.+.jpg
代表以http://开头.任意字符+至少出现一次(类似do while)然后以.jpg结尾的字符串

在图形展示中
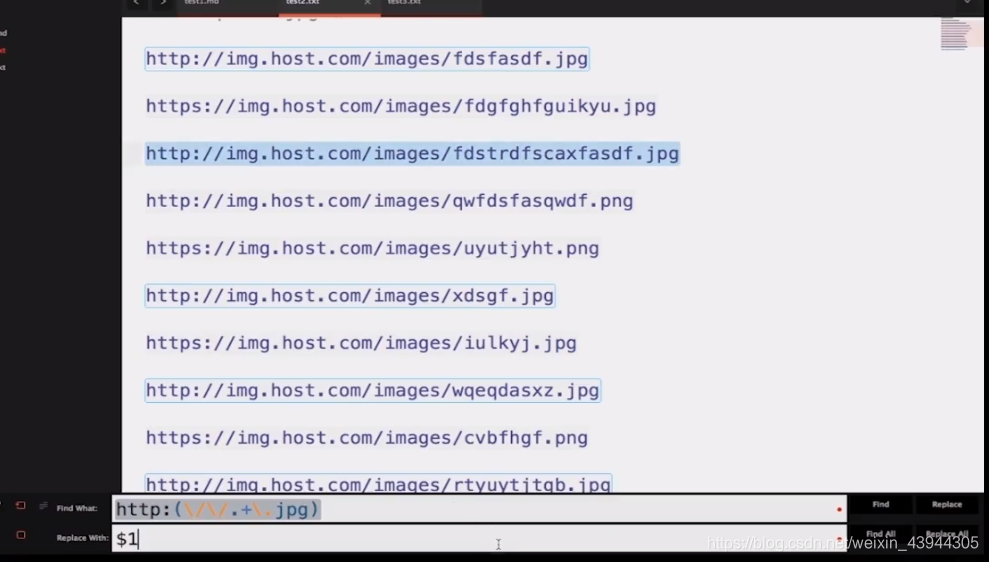
但是上面这样只是筛选出来,并没有获取到这些个筛选出来的字符串啊,这里就要用到分组了
http:(//.+.jpg)
加个括号,就可以把括号中的内容全部获取了
用$1获取
下图展示的是,把括号中的内容替换匹配到的字符串
替换后
不规则的日期替换
^\d{4}[/-]\d{2}[/-]\d{2}$
代表以4个数字开头,接/或者-,接2个数字,接/或者-,接2个数字结尾
用个编辑器就可以马上实验出来了,这里成功筛选到了想要的日期格式

如何把上面筛选到的字符串替换掉呢,还是用()括号分组
这里我要替换成月日年

替换后

js中通过内置对象RegExp支持正则表达式
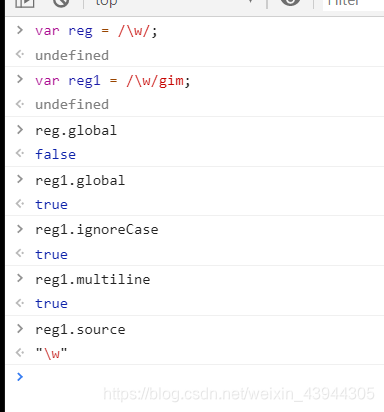
声明正则的时候 g 和 i 和 m 的意思

直接声明
var reg = /\bis\b/g;
在/和/g中间就是我们的正则表达式,这里末尾的 g 代表匹配全文,如果不加g就默认匹配第一个
不加g
var reg = /\bis\b/;

加g

这里是筛选单个小写的is单词
\b代表单词边界,开头也有举例
用构造函数声明
var reg = new RegExp( '\\\bis\\\b' , 'g' );
这里的双斜杠是为了把反斜杠转义,后面第二个参数和上面说的一样,整个字符串全文匹配
忽略大小写只需要加个i
i加在g后面也是为了整个字符串匹配

正则表达式由两种基本字符类型组成
原义字符:代表本身,就比如abc就是匹配abc
元字符:有特殊含义的字符,如\b代表单词边界,并不是匹配\b
字符类,元字符定义符合特性的一连串字符,类似java中的类的概念

[abc]代表一个类,这个类里有abc三个属性,只要字符串中有a,b,c或者abc的排列组合,不管逆序组合还是顺序组合,都会被匹配到
demo如下
把abc排列组合的字符串替换成X
"a1b2c3d4ab5bc6ac7abc8ba9".replace(/[abc]/g,'X');

字符类取反

demo如下
把abc排列组合以外的字符替换成X
"a1b2c3d4ab5bc6ac7abc8ba9".replace(/[^abc]/g,'X');

范围类
上面定义的字符类假如要定义1~9 那么这样定义也行[123456789],但是这样太麻烦了

demo如下
把字符串中的小写字母都替换成Q
'a1b2c3x4aaaaa,bbbWWWEEE'.replace(/[a-z]/g,'Q')

那么要同时匹配大小写字母呢,可以在里面这样写
[a-zA-Z]
这样就代表这个字符范围类同时可以匹配大小写字母的组合
demo如下
匹配大小写字母的组合
'a1b2c3x4aaaaa,bbbWWWzxczcasdEWDEEE'.replace(/[a-zA-Z]/g,'Q')

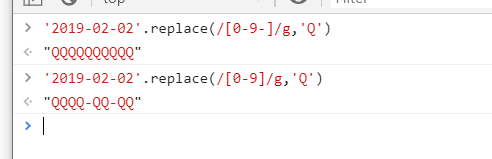
如何在匹配的同时匹配上横线呢
比如在2020-02-02
我们这样匹配[0-9]只能匹配到数字
[0-9-]在后面再加一个 - 就可以匹配上恒横线了
demo如下
[0-9-]代表这个字符范围类包括了0-9的数组和-横线的组合
'2019-02-02'.replace(/[0-9-]/g,'Q')
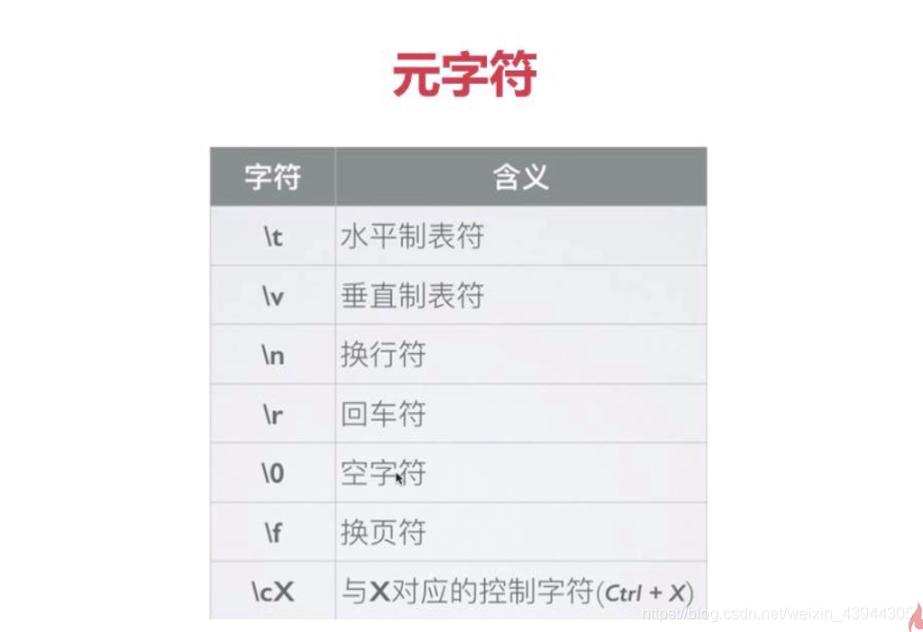
预定义类
其实就是正则表达式的快捷键

边界

边界demo如下

匹配有换行符的字符串

量词,定义字符出现的字数

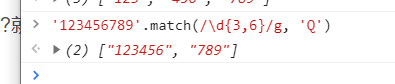
贪婪模式,尽可能多的匹配
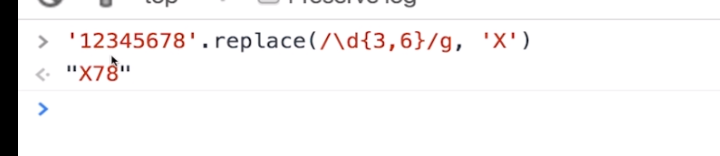
如果是’123456789’的话会变成QQ,因为第一个1-6匹配了最多,后面7-9正好匹配上最少

用match可以验证
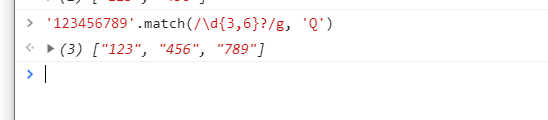
非贪婪模式,一单匹配成功就不再继续尝试
做法很简单,只要在量词后面加上?就可以了
\d{3,6}?按照最少的3次进行匹配
'123456789'.replace(/\d{3,6}?/g, 'Q')

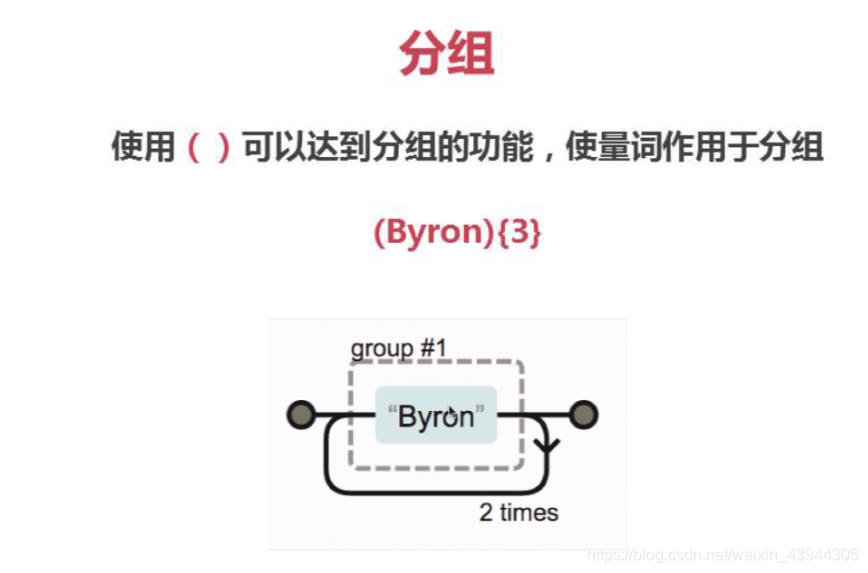
分组
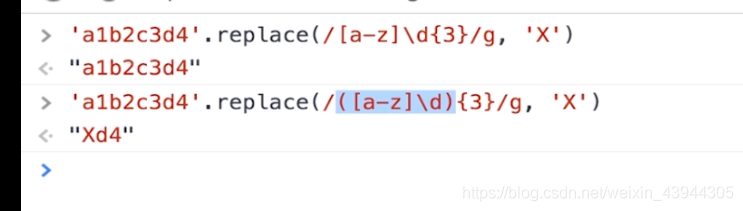
小写字母加数字连续出现3次
demo如下
或
就是java里的 ||
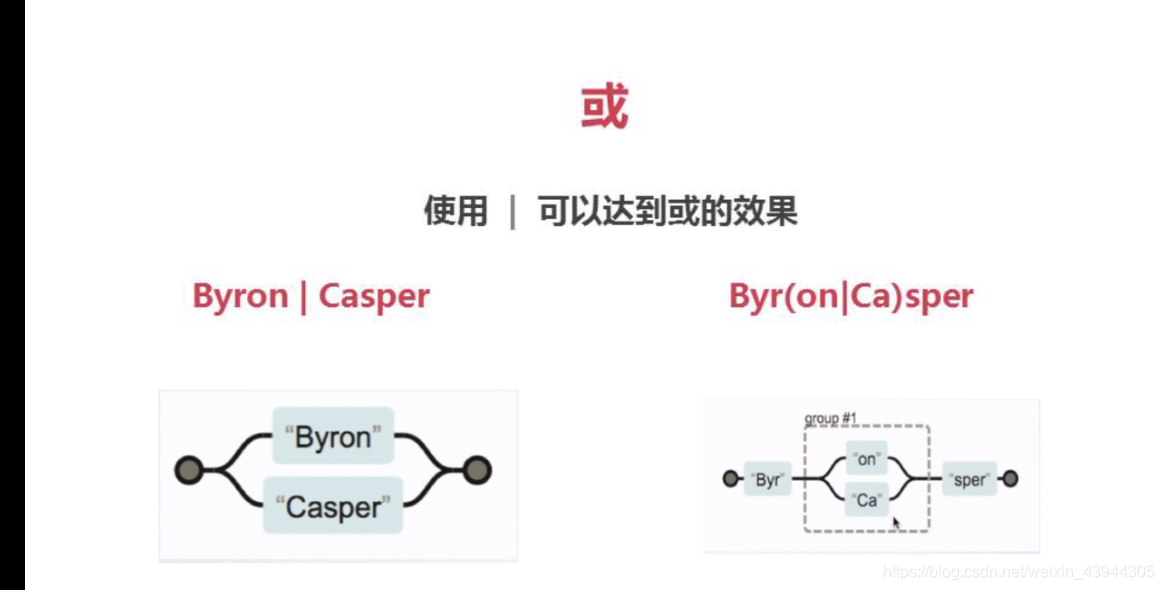
正则排除掉某个值
下面的demo是要排除掉 A59任意字符
A00任意字符-A59任意字符
中的59和00,我这里用的想法是分段,分成
^A([0][1-9]|[1-4]\d|[5][0-8]).*
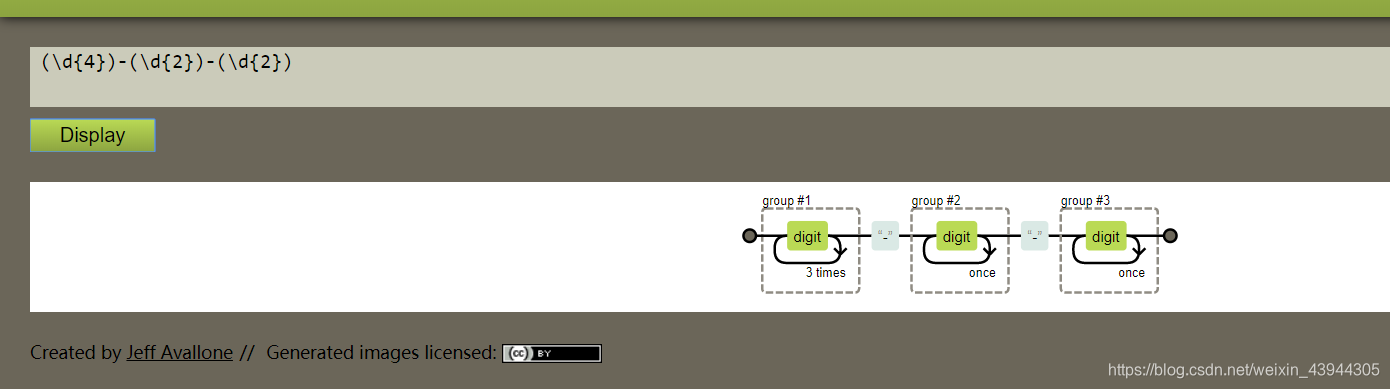
反向引用,就是用$符号获取前面分组内的内容,动态获取
ps:只有前面分组了才可以获取
demo

用图形展示,这里的group1 group2 group3就是$1 $2 $3
忽略分组,不捕获分组,就是(?:XXX)这个分组不会被$符号捕获,类似被continue了

前瞻

语法如下

前瞻符合后面的断言条件的demo
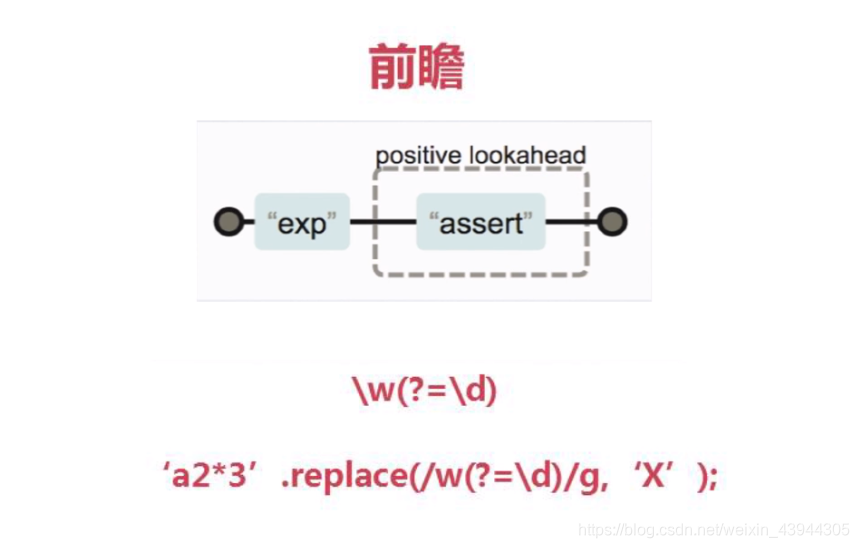
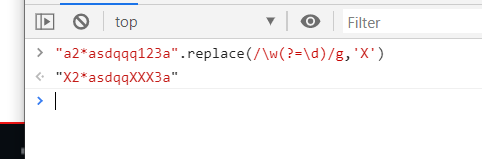
"a2*asdqqq123a".replace(/\w(?=\d)/g,'X')
\w(?=\d)
代表匹配到\w这个单词后向前方向(就是从左到右)看看后面是不是紧跟着一个数字,是的话就符合这个断言,否则不匹配.
demo中 a 的后面正好跟着一个数字所以a被匹配到了,a后面的数字是不会被匹配到了,只是a2这个整体符合了后面的断言,就像复核 if 里面的条件,然后我们注意到后面的q123也被匹配到了,这是因为123数字也属于单词字符,q1的q符合条件,12的1,23的2符合,这里注意到匹配的时候是整体匹配后出结果的,并不是先匹配了q1把q1替换成X后再继续匹配
前瞻不符合后面断言条件的,其实就是把?=换成?!取反
js的demo如下

"a2*asdqqq123a".replace(/\w(?!\d)/g,'X')
\w(?!\d)
代表单词字符后面跟着的不是数字的单词字符会被匹配到
这里我们注意到3a是符合的,但是3a后面最后一个a也被匹配到了,说明结尾的时候后面没有内容也符合不是数字这一断言匹配规则
js对象属性

声明的全局,忽略大小写,匹配多行对象属性是只读的,不能后面赋值
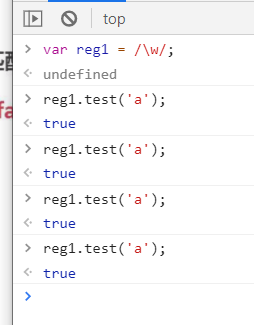
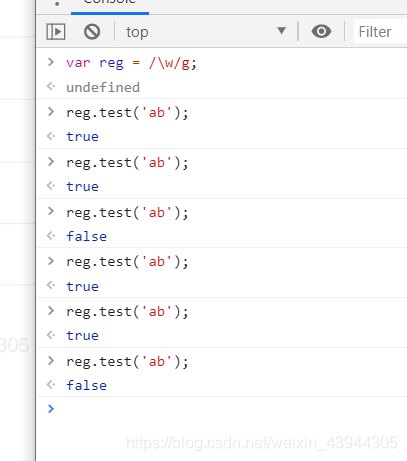
js使用RegExp.prototype.tes(str)检测字符串中是否存在符合正则表达式的内容,这里对同一个字符串只是第一次的检测,不能对同一个重复检测会有坑,请细看下方demo

demo如下
没有加 g 全局匹配的时候是ok的,但是加上g全局匹配会有一个现象,就是第一次匹配是ok的但是第二次匹配的时候发现变成了false,这是因为里面的lastIndex在作怪,reg1.lastIndex代表了当前匹配字符的最后一个字符的下一个字符的位置,demo中当前匹配的字符是a,a就是当前匹配字符的最后一个字符.然后lastIndex就变成了a的后面2虽然a后面没有元素了,但是lastIndex还是++了,这个只是表明位置下标
lastIndex是从0开始的
因为每次匹配的时候并不是从头开始的,比如
(/\w/g).test('ab')
第一次匹配到了a,lastIndex就是1,就是下一次找到中b的位置,匹配到了b,b的下一个就是2(为了下一次的寻找),虽然b后面没有元素了,但是lastIndex每次都是++,是用来寻找下一个元素.
一开始匹配到a,然后lastIndex=1,下次匹配就会找1的位置,匹配到2,lastIndex=2,下次匹配就会找2的位置,然后2没有,所以demo3中第三次匹配的时候就匹配不到了.并不是正则不稳定
ps:在非全局下lastIndex是不起作用的
demo1
demo2
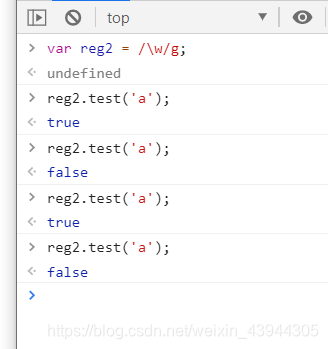
demo3
js正则检测字符串中的内容之exec方法


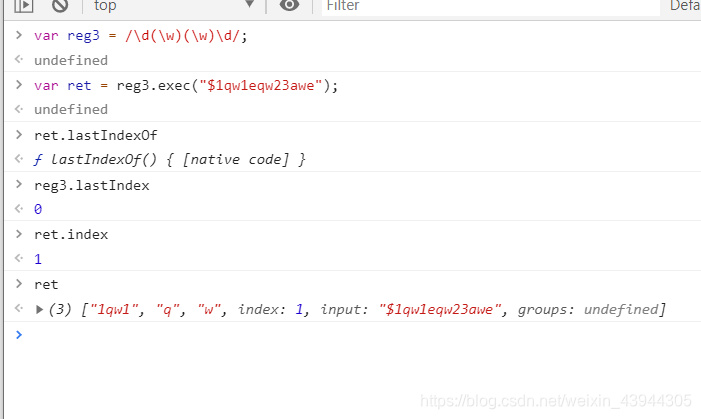
exec非全局匹配
首先我们发现lastindex=0了这是因为在非全局的时候lastindex是失效的,这很好理解,lastindex代表的是当前匹配内容的最后一个字符的下一个字符的位置,非全局的都不用匹配到下一个字符,当然就失效了
ret.index代表的是当前匹配到的内容的第一个字符的位置下标,比如下面demo中匹配到的是1qw1,其中1的下标的1所以,ret.index=1
ret是执行exec返回的对象数组,数组里面第一个元素是匹配到的内容,第二个和第三个是里面的分组中的内容,分组多的话依次类推,input是输入的匹配内容
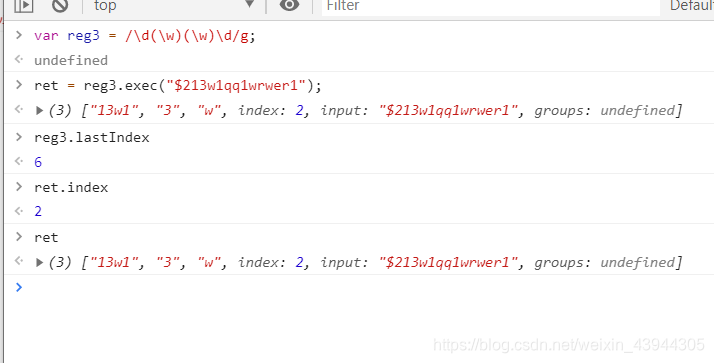
exec之全局匹配
全局匹配的时候lastindex就生效了,其余和上面的非全局匹配中介绍的一样
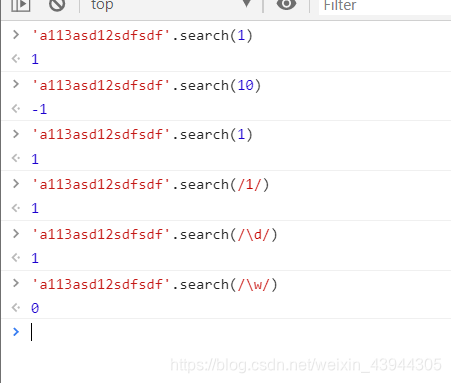
字符串的search也可以用正则,并且用正则的时候忽略全局g,即使声明了也没有差异,简单说就是全局不生效

demo如下
search中可以直接写正则,每次都是从头开始的,所以不用担心那个lastIndex
字符串的match,这个也可以写正则,返回匹配结果数组,声明全局g和不声明有差异


demo如下
非全局匹配下可以看到,和exec很像lastIndex也没生效
返回的数组中第一个元素是匹配到的内容,第二个是匹配到的内容中分组的内容,如果有多个分组这里就依次类推,index代表当前匹配到的内容的位置,也就是首字符的下标,input就是被匹配内容
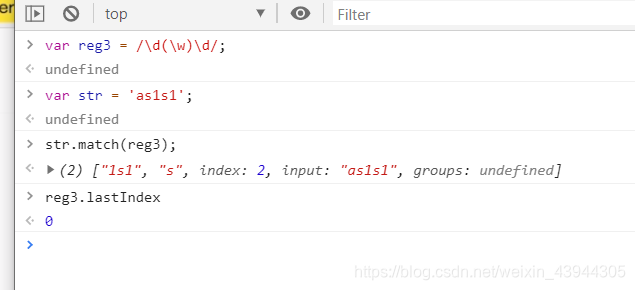

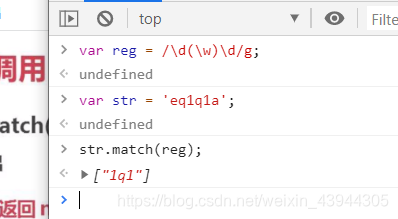
全局调用还是和非全局不一样的
demo如下
全局调用的时候是没有分组,输入的被匹配内容,index和lastindex属性的,只有匹配到的所有内容,没有配到就返回null
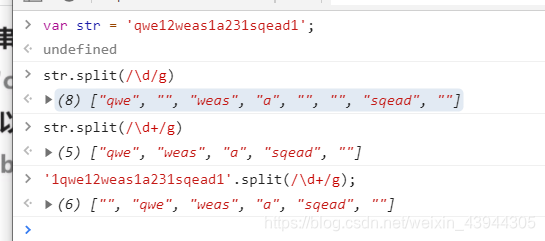
字符串的split方法里面也可以传正则

demo
适合按照数字分组,但是没指定哪个数字的情况下,这里要注意一个问题,假如被split的字符串的最后一位是数字,分组的最后一个会变成"",js把空字符串也当成最后一个字符了
js字符串的replace方法

传function的时候里面的参数

demo
没有分组的时候

有分组的时候
去掉匹配到的内容中间的字母

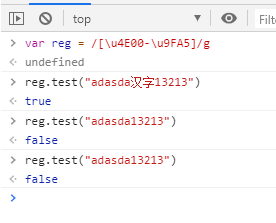
js 正则判断 汉字、数字、英文的格式
var pattern = /[\u4E00-\u9FA5]/g; //只能为英文
var numReg = /^(([1-9]+[0-9]*.{1}[0-9]+)|([0].{1}[1-9]+[0-9]*)|([1-9][0-9]*)|([0][.][0-9]+[1-9]*))$/; //只能为正数
var zh_reg = /^[\u4e00-\u9fa5]+$/ //只能为汉字
- 汉字demo
验证结果要取反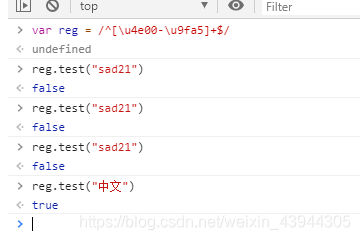
- 英文demo














 1813
1813











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









