






【Link】:http://codeforces.com/contest/828/problem/C
【Description】
让你猜一个字符串原来是什么;
你知道这个字符串的n个子串;
且知道第i个字符t[i],在k[i]个位置出现过;
且告诉你这k[i]个位置在哪里;
数据不会产生矛盾;
让你输出最终的字符串,输出字典序最小的那个;
【Solution】
对于输入的n个子串;
对于每个位置;
看看那个位置有没有子串之前出现过,没有的话,就放在那个位置;
否则,如果当前这个子串ti的长度比原来在xij那个位置的子串更长;
则也用这个ti代替在xij那个位置的子串;
顺便获取出这个串可能的最长长度maxlen;
然后从1到maxlen枚举
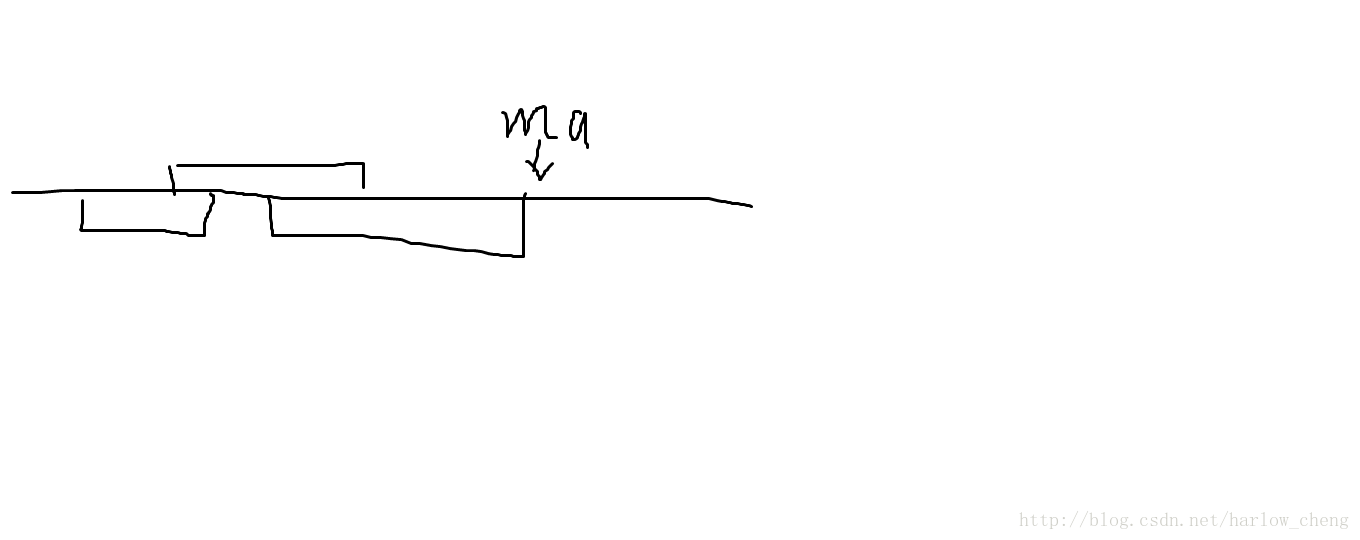
对于第i个位置,如果答案数组s[i]没有值,则ma = i;
(这里的ma,是这一块已经知道字符是什么的块的最末端的位置)
如果有子串s在第i个位置开始;
则从ma开始,到i+leni-1赋值成相应的字符
然后ma = max(ma,i + leni-1);
这样就能避免不必要的重复赋值了;
能跳过已经知道了的字符
如果没有子串s在第i个位置开始;
则,如果s[i]没有值,s[i]=’a’;
上面一开始s[i]没有值的时候,就说明有了间断的地方,则需要重新开始获取最末端了
【NumberOf WA】
0
【Reviw】
能想到这个方法,觉得自己很优秀;
【Code】
#include <bits/stdc++.h>
using namespace std;
#define lson l,m,rt<<1
#define rson m+1,r,rt<<1|1
#define LL long long
#define rep1(i,a,b) for (int i = a;i <= b;i++)
#define rep2(i,a,b) for (int i = a;i >= b;i--)
#define mp make_pair
#define pb push_back
#define fi first
#define se second
#define ms(x,y) memset(x,y,sizeof x)
#define Open() freopen("F:\\rush.txt","r",stdin)
#define Close() ios::sync_with_stdio(0)
typedef pair<int,int> pii;
typedef pair<LL,LL> pll;
const int dx[9] = {0,1,-1,0,0,-1,-1,1,1};
const int dy[9] = {0,0,0,-1,1,-1,1,-1,1};
const double pi = acos(-1.0);
const int NN = 2e6;
const int N = 1e5;
int n,maxlen = 0;
string t[N+100];
pii open[NN+100];
char s[NN+10];
int main(){
Close();
rep1(i,1,NN) s[i] = '0';
cin >> n;
rep1(i,1,n){
cin >> t[i];
int num;
cin >> num;
rep1(j,1,num){
int p;
cin >> p;
maxlen = max(maxlen,p + (int) t[i].size()-1);
if (open[p].se == 0){
open[p] = mp(i,(int) t[i].size());
}else
if (open[p].se < (int) t[i].size())
open[p] = mp(i,(int) t[i].size());
}
t[i] = ' '+t[i];
}
int ma = 1;
rep1(i,1,maxlen){
if (s[i]=='0') ma = i;
if (open[i].se>0){
rep1(j,ma,i+open[i].se-1){
int k = j-i+1;
s[j] = t[open[i].fi][k];
}
ma = max(ma,i+open[i].se-1);
}
else
if (s[i]=='0')s[i]='a';
}
rep1(i,1,maxlen)
cout << s[i];
cout << endl;
return 0;
}














 270
270











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









