









数据规范
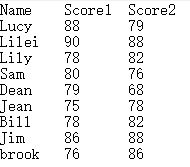
.txt表格型数据如下,其中分割符为’\t’,最后通过换行符’\n’换行
核心思想
打开文件,排除与数据无关的第一行,将从第二行开始的有效数据通过去尾、分割转化为易于操作的二维列表形式,通过int()或float()把数字型字符串数据转化为数字数据
预操作
with open(filepath) as f:#filepath自定义
f.readline()#去掉与数据无关的第一行
lines=f.readlines()#读取剩下有数据的行
for i in range(len(lines)):#循环对8行进行操作
if lines[i].endswith('\n'):
lines[i]=lines[i][:-1] #将字符串末尾的\n去掉
lines[i]=lines[i].split('\t') #以\t分割
此时处理后的lines数据为:
[['Lucy', '88', '79'], ['Lilei', '90', '88'], ['Lily', '78', '82'], ['Sam', '80', '76'], ['Dean', '79', '68'], ['Jean', '75', '78'], ['Bill', '78', '82'], ['Jim', '86', '88'], ['brook', '76', '86']]
就变成了一组二维列表,此后的数据操作就已经和txt文件完全无关了
数据操作
每个列表元素的第一个元素都是Name,第二个都是Score1,第三个都是Score2,故如果把Score1和Score2各附以50%的权重,在for循环内对二维列表进行如下处理
Score=int(lines[i][1])*0.5+int(lines[i][2])*0.5#i为循环变量
就可以把每一个列表元素的第二和第三个数据进行加权计算,将第一个Name数据一并输出
print(lines[i][0]+'的总成绩为'+str(Score))#输出总成绩
即可得结果:
Lucy的总成绩为83.5
Lilei的总成绩为89.0
Lily的总成绩为80.0
Sam的总成绩为78.0
Dean的总成绩为73.5
Jean的总成绩为76.5
Bill的总成绩为80.0
Jim的总成绩为87.0
brook的总成绩为81.0
实现了对于表格型字符串的简单数据处理
非表格型.txt文件字符串
不是表格型的其实更简单,而且也不可能涉及到数据操作,读取后就没.txt文件什么事了。当做一个字符串,用字符串的函数进行操作即可



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











