







Python 内置了 requests 模块,该模块主要用来发 送 HTTP 请求,requests 模块比 urllib 模块更简洁。
将一个链接输入浏览器,浏览器接受链接后,会寻找链接的地址,这个地址的主人也是一台电脑(不过是超级电脑,也叫服务器,支持大量文件的存储和计算),我们访问的网页就是这台电脑(服务器)上的某个文件。浏览器找到服务器后,会发送一个请求过去,告诉服务器我们需要访问上面文件。服务器收到请求后,会把文件发送给浏览器,这一步叫响应。
一般而言,我们所用的 HTTP 协议或 HTTPS 协议,使用的请求方式只有 GET 方式和 POST 方式。
GET 方式: 访问某个网页前不需要在浏览器里输入链接之外的东西,因为我们只是想向服务器获取一些资源,可能就是一个网页。
POST 方式:访问某个网页前需要在浏览器里输入链接之外的东西,因为这些信息是服务器需要的。 比如在线翻译,我们需要输入点英文句子,服务器才能翻译。
get方式和post方式区别:GET产生 一个 TCP数据包,POST产生 两个 TCP数据包。对于GET方式的请求,浏览器会把http header和data一并发送出去,服务器响应200(返回数据);而对于POST,浏览器先发送header,服务器响应100 continue,浏览器再发送data,服务器响应200 ok(返回数据)。
注: 虽然用 GET 方式也可以提交数据,但一般不用 GET 方式而是用 POST 方式。在 HTTP协议中,建议 GET 方式只用来获取数据,而 POST 方式则用来提交数据(而不是获取数据)。
http常见请求参数
| 参数 | 说明 |
|---|---|
| GET | 请求获取URL位置的资源 |
| HEAD | 请求获取URL位置资源的响应消息报告,即获得资源的头部信息 |
| POST | 请求向URL位置的资源后附加新的消息 |
| PUT | 请求向URL位置存储一个资源,覆盖原URL位置的资源 |
| PATCH | 请求局部更新URL位置的资源,即改变该处资源的部分内容 |
| DELETE | 请求删除URL位置存储的资源 |
URL 的一般语法格式为:
protocol://host[:port]/path/[?query]#fragment
http://www.itcast.cn/index.html?name=andy&age=18#link
| 组成 | 说明 |
|---|---|
| protocol | 通信协议,常用:http、https 等 |
| host | 主机(域名) |
| port | 端口号,可选,省略时候使用方案的默认端口,如:http的默认端口为80 |
| path | 路径,由零或多个 ‘/’ 符号隔开的字符串,一般用来表示主机上的一个目录或文件地址 |
| query | 参数,以键值对的形式通过 & 来连接 |
| fragment | 片段,# 后面内容常见于链接 锚点 |
安装
pip install requests
requests 方法
| 方法 | 说明 |
|---|---|
| delete(url, args) | 发送 DELETE 请求到指定 url |
| get(url, params, args) | 发送 GET 请求到指定 url |
| head(url, args) | 发送 HEAD 请求到指定 url |
| patch(url, data, args) | 发送 PATCH 请求到指定 url |
| post(url, data, json, args) | 发送 POST 请求到指定 url |
| put(url, data, args) | 发送 PUT 请求到指定 url |
| request(method, url, args) | 构造一个请求,最基本的方法,是下面方法的支撑 |
post() 方法可以发送 POST 请求到指定 url,一般格式如下:
requests.post(url, data={key: value}, json={key: value}, args)
- url 请求 url。
- data 参数为要发送到指定 url 的字典、元组列表、字节或文件对象。
- json 参数为要发送到指定 url 的 JSON 对象。
- args 为其他参数,比如 cookies、headers、verify等。
data 和 params 的区别是: data提交的数据并不放在url链接里, 而是放在url链接对应位置的地方作为数据来存储。params与get进行联用,是字典或者字节序列,作为参数增加到URL中。不仅访问URL,还可以向服务器携带参数。data与requests.post()进行联用。
示例
word = input("please input a word")
url = "https://fanyi.baidu.com/sug"
data = {
"kw": word,
}
headers = {
'User-Agent': "Mozilla / 5.0(Windows NT 10.0;Win64;x64) AppleWebKit / 537.36(KHTML, likeGecko) Chrome / 96.0.4664 .93 Safari / 537.36",
}
resp = requests.get(url=url, data=data, headers=headers)
print(resp.json())
响应
| 属性或方法 | 说明 |
|---|---|
| apparent_encoding | 编码方式 |
| close() | 关闭与服务器的连接 |
| content | 返回响应的内容,以字节为单位。把数据转成二进制,用于获取图片、音频类的数据。 |
| cookies | 返回一个 CookieJar 对象,包含了从服务器发回的 cookie |
| elapsed | 返回一个 timedelta 对象,包含了从发送请求到响应到达之间经过的时间量,可以用于测试响应速度。比如 r.elapsed.microseconds 表示响应到达需要多少微秒。 |
| encoding | 解码 r.text 的编码方式 |
| headers | 返回响应头,字典格式 |
| history | 返回包含请求历史的响应对象列表(url) |
| is_permanent_redirect | 如果响应是永久重定向的 url,则返回 True,否则返回 False |
| is_redirect | 如果响应被重定向,则返回 True,否则返回 False |
| iter_content() | 迭代响应 |
| iter_lines() | 迭代响应的行 |
| json() | 返回结果的 JSON 对象 (结果需要以 JSON 格式编写的,否则会引发错误) |
| links | 返回响应的解析头链接 |
| next | 返回重定向链中下一个请求的 PreparedRequest 对象 |
| ok | 检查 “status_code” 的值,如果小于400,则返回 True,如果不小于 400,则返回 False |
| raise_for_status() | 如果发生错误,方法返回一个 HTTPError 对象 |
| reason | 响应状态的描述,比如 “Not Found” 或 “OK” |
| request | 返回请求此响应的请求对象 |
| status_code | 返回 http 的状态码,比如 404 和 200(200 是 OK,404 是 Not Found) |
| text | 返回响应的内容,unicode 类型数据。把数据转为字符串,用于获取文本、网页原代码类的数据。 |
| url | 返回响应的 URL |
Token
Token作用
为了验证用户登录情况以及减轻服务器的压力,减少频繁的查询数据库,使服务器更加健壮。
什么是Token
Token是服务端生成的一串字符串,以作客户端进行请求的一个令牌,当第一次登录后,服务器生成一个Token便将此Token返回给客户端,以后客户端只需带上这个Token前来请求数据即可,无需再次带上用户名和密码。
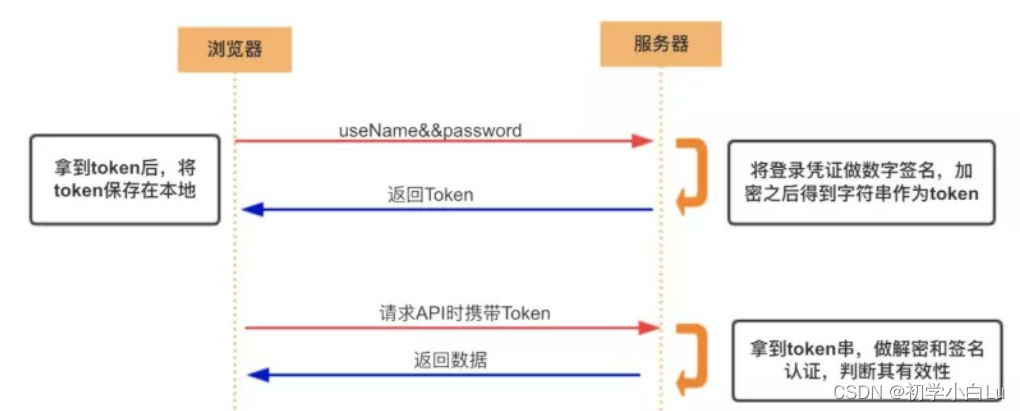
获取token数据
从响应头中获取token
# 登录
url = 'http://xxx.nhf.cn/api/businessAccountInfo/v1.4/userLogin'
data = {"phoneNum": "13856290000", "password": "123456"}
response = requests.post(url, json=data)
print(response.headers['token'])
# 从登录接口的响应头中获取token值,存储在变量token中,方便后续接口请求的时候使用
token = response.headers['token']
# 查询订单列表
url = 'http://xxx.nhf.cn/api/fresh/v1.4/ordersList'
data = {"pageNo": 1, "pageSize": 10}
headers = {'token': token}
response = requests.post(url, json=data, headers=headers)
print(response.json())















 2681
2681











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









