







GAUSS数据库
大规模并行处理关系型数据库,支持行、列存储(分布式存储和并发查询)
下面是分布式架构中的一些关键角色
 GaussDB(openGauss)分布式关键特性
GaussDB(openGauss)分布式关键特性
关键技术一:分布式执行框架
业务应用下发SQL给Coordinator,SQL可以包含对数据的增(insert)、删(delete/drop)、改(update)、查(select)。Coordinator利用数据库的优化器生成执行计划,每个DN会按照执行计划的要求去处理数据。因为数据是通过一致性Hash技术均匀分布在每个节点,因此DN在处理数据的过程中,可能需要从其他DN获取数据,GaussDB 提供了三种stream流(广播流、聚合流和重分布流)来降低数据在DN节点间的流动。DN将结果集返回给Coordinate进行汇总。Coordinator将汇总后的结果返回给业务应用。
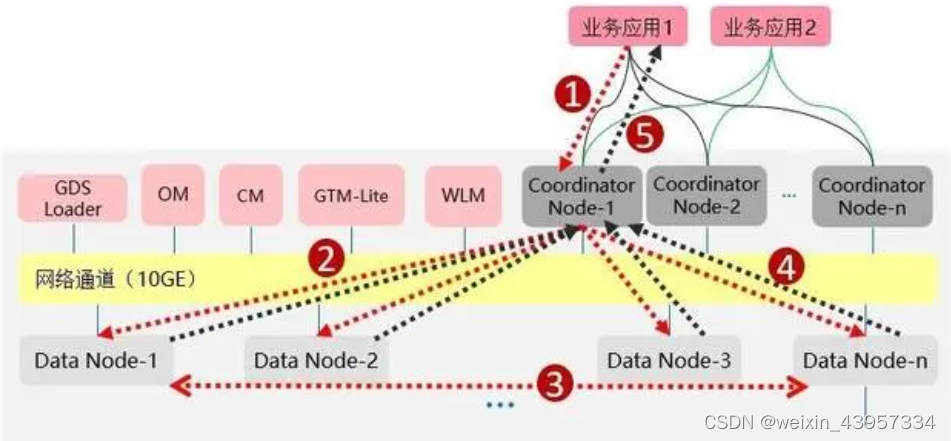 分布式执行计划
分布式执行计划
CN 根据表的分布列信息和关联列信息进行判定,SQL 语句是否可以直接在各个 DN 上执行而且不需要数据交流,如果是,CN 采用 LIGHT_QUERY 或 FQS_QUERY 流程,保持了事不关己的态度,你发给我什么我就下发什么,直接将整个 query 命令下发给 DN 执行,执行完成后直接输出;如果需要在各个 DN 之间进行数据交互,则会选择使用 stream 算子;如果发现无法使用 stream 算子时,就回到了原始的 PGXC 流程。
LIGHT_QUERY
场景:语句可以直接在一个 DN 执行(单 shard 语句,点查场景)。
FQS_QUERY
场景:当语句可以完全下推到多个 DN 上执行,且 DN 之间不需要数据交互时。
- 原理:CN 不通过优化器,直接生成 RemoteQuery 计划,走执行器逻辑下发到 DN,各 DN 根据下推语句生成执行计划并进行执行,执行结果在 CN 上进行汇总。
LIGHT_QUERY 和 FQS_QUERY 的最大异同点在于,虽然 CN 都是经过判定后直接把收到的 query 下发给 DN 进行处理,但是 LIGHT_QUERY 只涉及到单 DN 进行操作,而 FQS_QUERY 涉及到多个 DN 分别进行操作,它们都不会涉及到 DN 间的数据交互。

STREAM GATHER
场景:需要各 DN 之间进行数据交互。
原理:CN 根据原语句通过优化器生成带 stream 算子的执行计划,下发给 DN 进行执行,DN 执行过程中存在数据交互(stream 节点),stream 算子在 DN 之间建立连接进行数据交互,CN 汇总执行结果并承担大部分计算。
STREAM REDISTRIBUTE
场景:需要各 DN 之间进行数据交互。
原理:CN 根据原语句通过优化器生成带 stream 算子的执行计划,下发给 DN 进行执行,各 DN 执行过程中存在数据交互(stream 节点),stream 算子在 DN 之间建立连接进行数据交互,CN 汇总执行结果并承担大部分计算。
STREAM BROADCAST
场景:需要各 DN 之间进行数据交互。
原理:CN 根据原语句通过优化器生成带 stream 算子的执行计划,下发给 DN 进行执行,各 DN 执行过程中存在数据交互(stream 节点),stream 算子在 DN 之间建立连接进行数据交互,CN 汇总执行结果并承担大部分计算。
总结
综上所述,GaussDB(for openGauss)作为自主研发的新一代金融级分布式关系型数据库,采用可横向扩展的分布式架构,通过 SQL 优化器生成分布式算子以及分布式执行计划,提供了三种 stream 流(广播流、聚合流和重分布流)来降低数据在 DN 节点间的流动;执行引擎是一个分布式并行执行框架,支持节点间并行和节点内并行能力,充分利用当前多核特点,通过并发执行,提高系统吞吐量,具备大数据下高性能查询能力。
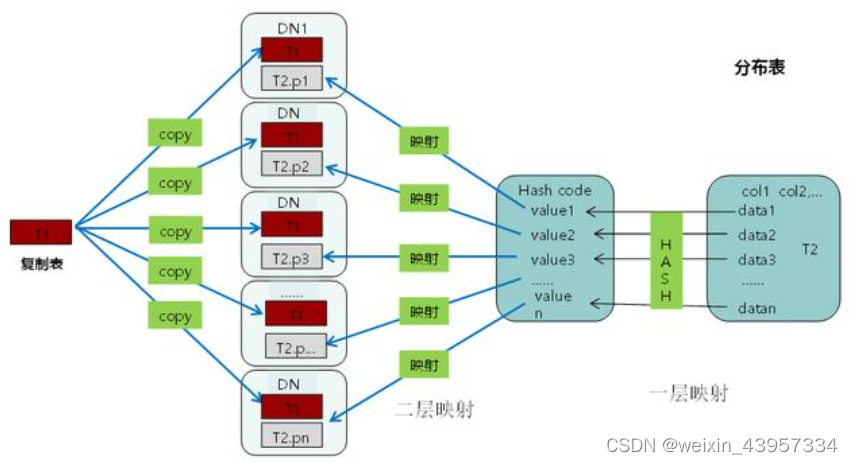
GaussDB数据分布策略设计(复制表和分布表)
GaussDB(for openGauss)分布式模式最大可以支持1000+节点,PB级存储,分布式事务强一致等特性可以很好地满足政府、交通、金融、能源等行业的互联网+的诉求。
分布存储和并发查询是MPP架构数据库的主要优势所在。将一个大数据量表中的数据,按合适分布策略分散存储在多个DN实例内,可极大提升数据库性能。
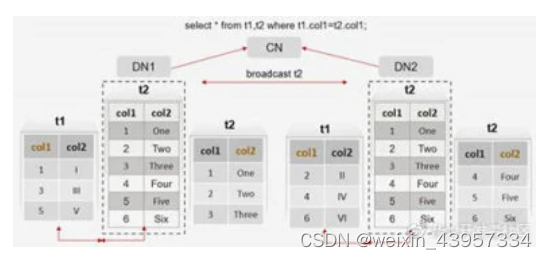
 分布表及复制表关联过程
分布表及复制表关联过程
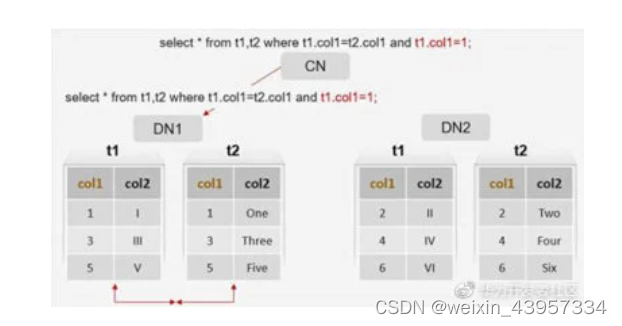
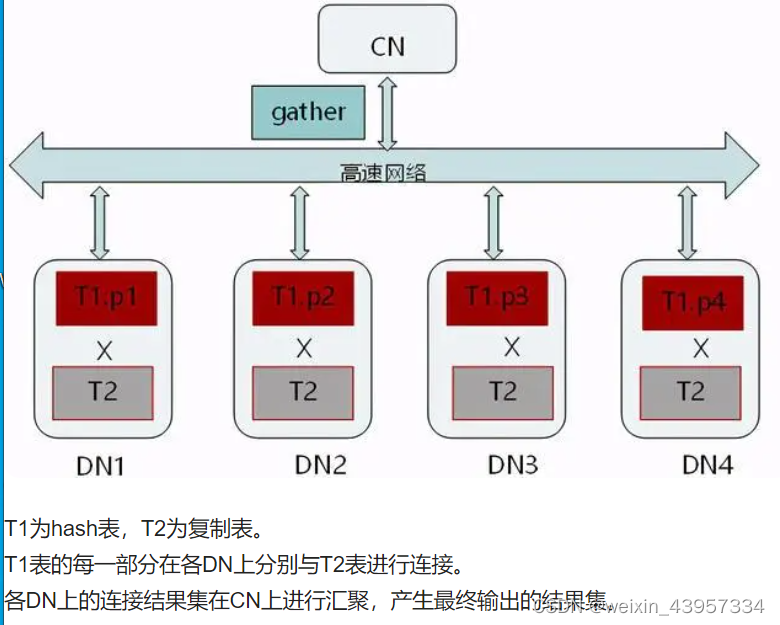
(1)分布表和复制表的关联查询
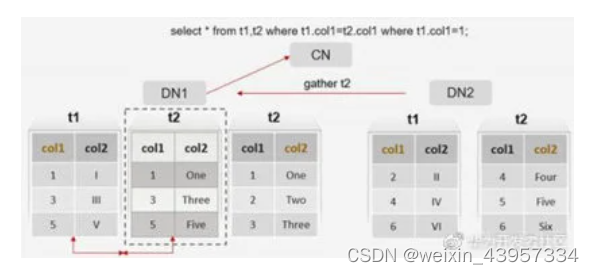
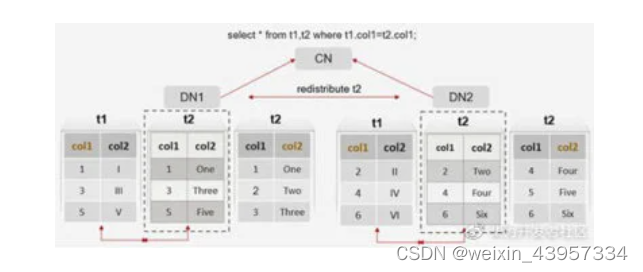
 (2)分布表与分布表关联查询
(2)分布表与分布表关联查询
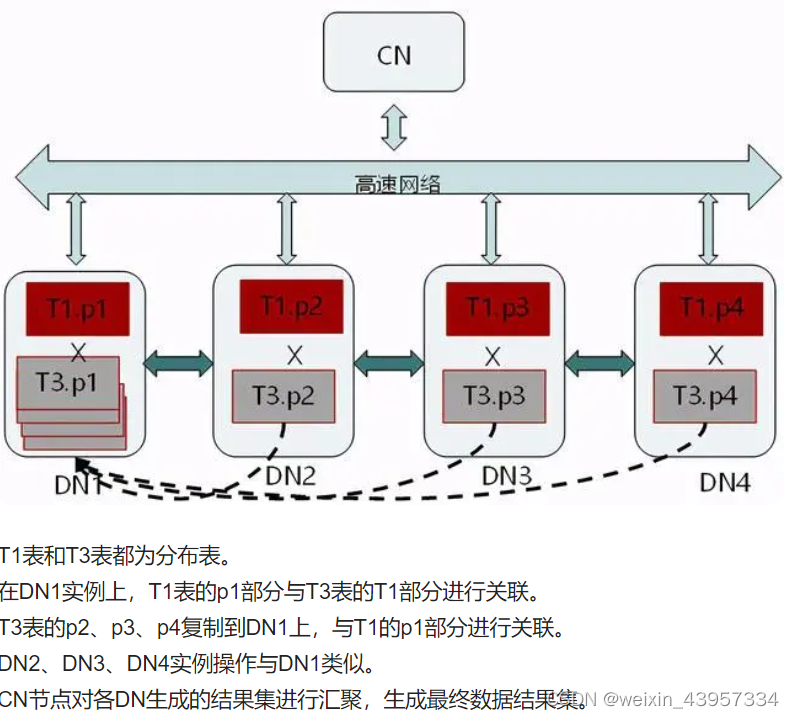 注:细心的朋友可能看到,不同的DN之间可能会进行数据同步,在这种情况下,执行效率会就变差,如何避免这种情况,下面会讲到。
注:细心的朋友可能看到,不同的DN之间可能会进行数据同步,在这种情况下,执行效率会就变差,如何避免这种情况,下面会讲到。
分布键的选择
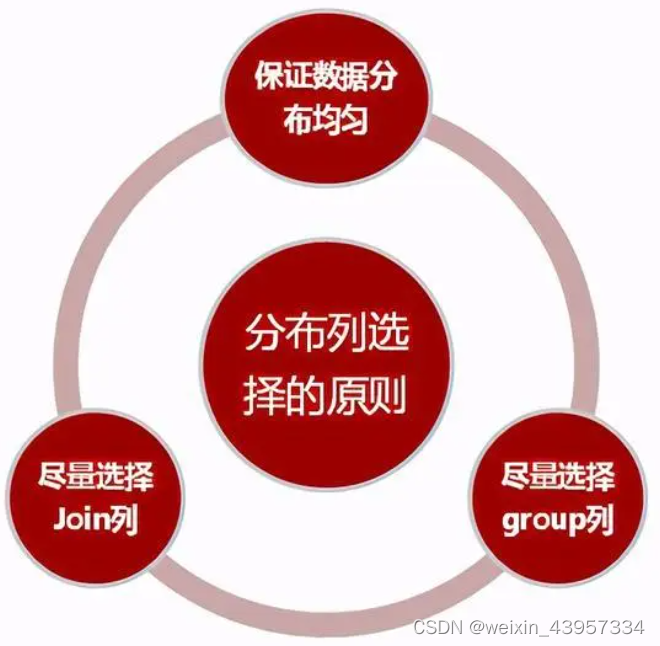
尽量选择distinct值比较多的列,保证数据均匀分布。分布均匀是为了避免木桶效应,各个主机对等执行。
尽量选择Join列或group 列做分布列。尽量选择Join列或group 列是为了避免数据节点之间数据流动, 提高性能。
避免数据广播
在分布表关联分布时,分布列不同时,存在Streaming(type: BROADCAST)广播,不同DN节点之间数据存在交互,会增加网络开销,而分布列相同或关联复制表数据时,不存在DN节点间数据交互。
GaussSQL调优策略
SQL执行计划
















 3305
3305











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









