







摘要
深度卷积网络在静止图像中的目标识别方面取得了巨大成功。然而,对于视频中的动作识别,深度卷积网络的改进并不那么明显。我们认为有两个原因可以解释这一结果。首先,与图像域中的那些非常深的模型(例如 VGGNet [13]、GoogLeNet [15])相比,当前的网络架构(例如双流 ConvNets [12])相对较浅,因此它们的建模能力受到其深度的限制.其次,可能更重要的是,动作识别的训练数据集与 ImageNet 数据集相比非常小,因此很容易在训练数据集上过拟合。
为了解决这些问题,本论文通过将最近的非常深的架构适应视频领域,提出了非常深的双流 ConvNets 用于动作识别。然而,这种扩展并不容易,因为动作识别的规模很小。我们为非常深的双流 ConvNets 的训练设计了几个好的实践,即 (i) 空间和时间网络的预训练,(ii) 较小的学习率,(iii) 更多的数据增强技术,(iv) 高丢弃率。同时,我们将 Caffe 工具箱扩展到具有高计算效率和低内存消耗的多 GPU 实现中。我们在 UCF101 的数据集上验证了非常深的双流 ConvNets 的性能,它达到了 91.4% 的识别准确率。
1.引言
人类行为识别已经成为计算机视觉中的一个重要问题,并在该领域引起了很多研究兴趣[12,16,19]。由于类内变化大、视频分辨率低、视频数据维数高等原因,动作识别问题具有挑战性。
过去几年见证了关于短视频的动作识别的巨大进步。这些研究工作大致可以分为两类。第一种算法侧重于手工制作的局部特征和视觉词袋(BoVWs)表示。最成功的例子是提取改进的轨迹特征[16]并采用Fisher向量表示[11]。第二种算法利用深度卷积网络 (ConvNets) 从原始数据(例如 RGB 图像或光流场)中学习视频表示,并以端到端的方式训练识别系统。最具竞争力的深度模型是双流 卷积网络[12]。
然而,与图像分类 [7] 不同,深度卷积网络并没有比这些传统方法产生显着的改进。我们认为有两个可能的原因可以解释这种现象。首先,动作的概念比对象更复杂,它与其他高级视觉概念相关,例如交互对象、场景上下文、人体姿势。直观地说,更复杂的问题将需要更高复杂度的模型。然而,与图像分类中的那些成功模型相比,当前的双流 卷积网络相对较浅(5 个卷积层和 3 个全连接层)[13, 15]。其次,与 ImageNet 数据集 [1] 相比,动作识别的数据集非常小。例如,UCF101 数据集 [14] 仅包含 13320 个视频片段。然而,这些深度卷积网络总是需要大量的训练样本来调整网络权重。
为了解决这些问题,本报告提出了用于动作识别的Very Deep Two-stream ConvNets。Very Deep Two-stream ConvNets具有很高的建模能力,并且能够处理大量复杂的动作类。然而,由于上述第二个问题,由于过拟合问题,在如此小的数据集中训练非常深的模型非常具有挑战性。我们提出了几个好的实践来使Very Deep Two-stream ConvNets 的训练稳定并减少过拟合的影响。通过在动作数据集上仔细训练我们提出的Very Deep Two-stream ConvNets,我们能够在 UCF101 的数据集上实现最先进的性能。同时,我们将 Caffe 工具箱 [4] 扩展到具有高效率和低内存消耗的多 GPU 实现中。
本报告的其余部分安排如下。在第 2 节中,我们详细介绍了我们提出的Very Deep Two-stream ConvNets,包括网络架构、训练细节、测试策略。我们在第 3 节报告我们在 UCF101 数据集上的实验结果。最后,我们在第 4 节总结我们的报告。
2. 非常深的双流卷积网络
在本节中,我们将详细描述我们提出的方法。我们首先介绍Very Deep Two-stream ConvNets的架构。之后,我们展示了训练细节,这对于减少过度拟合的影响非常重要。最后,我们描述了我们的动作识别测试策略。
2.1网络架构
网络架构在深度卷积网络的设计中非常重要。在过去的几年中,许多著名的网络结构被提出用于图像分类,例如 AlexNet [7]、ClarifaiNet [22]、GoogLeNet [15]、VGGNet [13] 等。在从 AlexNet 到 VGGNet 的演变过程中出现了一些趋势:更小的卷积核大小、更小的卷积步幅和更深的网络架构。事实证明,这些趋势在提高对象识别性能方面是有效的。然而,它们对动作识别的影响尚未在视频领域得到充分研究。在这里,我们选择了两个最新成功的网络结构来设计非常深的双流 ConvNet,即 GoogLeNet 和 VGGNet。
GoogLeNet。它本质上是一个代号为Inception的深度卷积网络架构,其基本思想是赫布原理和多尺度处理的直觉。 Inception 网络中的一个重要组件是 Inception 模块。 Inception 模块由多个大小不同的卷积滤波器组成。为了加快计算效率,选择1×1卷积操作进行降维。 GoogLeNet 是一个 22 层的网络,由相互堆叠的 Inception 模块组成,偶尔会有步幅为 2 的最大池化层,以将网格的分辨率减半。更多细节可以在其原始论文[15]中找到。
VGGNet。它是一种新的卷积架构,具有更小的卷积大小(3×3)、更小的卷积步幅(1×1)、更小的池化窗口(2×2)、更深的结构(最多19层)。 VGGNet 通过在浅层架构的基础上构建和预训练更深层次的架构,系统地研究了网络深度对识别性能的影响。最后,针对 ImageNet 挑战提出了两种成功的网络结构:VGG-16(13 个卷积层和 3 个全连接层)和 VGG-19(16 个卷积层和 3 个全连接层)。更多细节可以在其原始论文[13]中找到。
Very Deep Two-stream ConvNets。遵循这些成功的对象识别架构,我们将它们应用于视频中动作识别的双流 卷积网络 的设计,我们称之为Very Deep Two-stream ConvNets。我们对 GoogLeNet 和 VGG-16 进行了实证研究,以设计Very Deep Two-stream ConvNets。空间网络建立在单帧图像(224×224×3)上,因此其架构与图像域中的对象识别相同。时间网络的输入是 10 帧堆叠的光流场(224×224×20),因此第一层的卷积滤波器与图像分类模型的卷积滤波器不同。
2.2. 网络训练
在这里,我们描述了如何在 UCF101 数据集上训练Very Deep Two-stream ConvNets。 UCF101 数据集包含 13320 个视频剪辑,并提供 3 个分割用于评估。对于每个拆分,大约有 10,000 个用于训练的剪辑和 3300 个用于测试的剪辑。由于训练数据集非常小,动作的概念相对复杂,训练Very Deep Two-stream ConvNets非常具有挑战性。从我们的经验探索中,我们发现了几种训练Very Deep Two-stream ConvNets 的良好实践,如下所示。
双流卷积网络的预训练
事实证明,当没有足够的训练样本可用时,预训练是一种初始化深度卷积网络的有效方法。对于空间网络,如 [12] 中所示,我们选择 ImageNet 模型作为网络训练的初始化。对于时间网络,它的输入模态是光流场,它捕获运动信息,不同于静态 RGB 图像。有趣的是,我们观察到通过使用 ImageNet 模型预训练时间网络,它仍然可以很好地工作。为了使这种预训练合理,我们对光流场和 ImageNet 模型进行了一些修改。首先,我们为每个视频提取光流场,并通过线性变换将光流场离散为 [0, 255] 的区间。其次,由于时间网络的输入通道数与空间网络的输入通道数不同(20 vs. 3),我们将第一层的ImageNet模型过滤器在各通道上取平均值,然后将平均值复制20次作为时间网络的初始化。
更小的学习率
由于我们使用 ImageNet 模型预训练了 twostream ConvNet,与 [12] 中的原始训练相比,我们使用了更小的学习率。
具体来说,我们将学习率设置如下:对于时间网络,学习率从 0.005 开始,每 10,000 次迭代降低到 1/10,在 30,000 次迭代时停止。
对于空间网络,学习率从 0.001 开始,每 4,000 次迭代下降到其 1/10,在 10,000 次迭代时停止。
总的来说,学习率降低了 3 倍。同时,我们注意到它需要更少的迭代来训练Very Deep Two-stream ConvNets。我们分析这可能是由于我们使用 ImageNet 模型对网络进行了预训练。
更多的图像增强技术
已经证明,随机裁剪和水平翻转等数据增强技术可以非常有效地避免过拟合问题。在这里,我们尝试了两种新的数据增强技术来训练Very Deep Two-stream ConvNets,如下所示:
我们设计了一个角裁剪策略,这意味着我们只裁剪图像的 4 个角和 1 个中心。我们发现,如果我们使用随机裁剪方法,更有可能选择靠近图像中心的区域,训练损失迅速下降,导致过拟合问题。但是,如果我们明确地将裁剪限制在 4 个角或 1 个中心,网络输入的变化将会增加,这有助于减少过度拟合的影响。
我们使用多尺度裁剪方法来训练Very Deep Two-stream ConvNets。事实证明,多尺度表示对于提高 ImageNet 数据集 [13] 上对象识别的性能是有效的。在这里,我们将这一良好实践应用到动作识别任务中。但是我们提出了一种与图像物体识别相比的有效实现方法[13]。我们将输入图像尺寸固定为 256 × 340,并从 {256,224,192,168} 中随机采样裁剪宽度和高度。之后,我们将裁剪区域的大小调整为 224 × 224。值得注意的是,这种裁剪策略不仅引入了多尺度增强,还引入了长宽比增强。
更高的丢弃率
与最初的双流ConvNets[12]类似,我们也为非常深的双流ConvNets中的全连接层设置了高辍学率。特别是,我们为时间网的全连接层设置了0.9和0.8的丢弃率。对于空间网,我们为全连接层设置了0.9和0.9的丢弃率。
多GPU训练
在视频动作识别任务中应用深度学习模型的一个巨大障碍是训练时间过长。另外,多帧的输入也增加了存储层激活的内存消耗。我们通过在多个GPU上采用数据并行训练来解决这些问题。训练系统是用Caffe[4]和OpenMPI实现的。按照[3]中使用的类似技术,我们通过在运行全连接层之前收集所有工作进程的激活值(参数值)来避免同步全连接(fc)层的参数。(就是除了全连接层的参数,其余层的参数全部同步)。在此过程中,我们使用了四个GPU来参与训练,训练速度相比于VGGNet-16的训练速度来说,快了3.7倍,相比于GoogLeNet的训练速度来说,快了4.0倍。每一个GPU的内存消耗减少了4倍。这个系统是公开可用的。
2.3 网络测试
为了与原始的双流ConvNets[12]进行公平的比较,我们采用他们的测试方案进行动作识别。在测试时,我们分别抽取25帧图像或光流场来测试空间网和时间网。从每个选定的帧中,我们为非常深的双流ConvNets获得10个输入,即4个角,1个中心,以及它们的水平翻转。最终的预测分数是通过对取样的帧和它们的裁剪区域进行平均而得到的。对于空间网和时间网的融合,我们使用其预测分数的加权线性组合,其中时间网的权重设置为2,空间网为1。
3.实验
数据集和实现细节
为了验证提出的非常深的两流 ConvNets 的有效性,我们在 UCF101 [14] 数据集上进行了实验。UCF101 数据集包含 101 个动作类,每个类至少有 100 个视频剪辑。整个数据集包含 13、320 个视频片段,每个动作类别分为 25 组。我们遵循 THUMOS13 挑战 [5] 的评估方案,并采用三个训练/测试拆分进行评估。我们报告了这三个拆分类别中的平均识别准确率。对于光流场的提取,我们沿用 TDD [19] 的工作,选择 TVL1 光流算法 [21]。具体来说,我们使用 OpenCV 实现,因为它在准确性和效率之间取得了平衡。
结果
我们在表 1 中报告了动作识别性能。我们比较了三种不同的网络架构,即 ClarifaiNet、GoogLeNet 和 VGGNet16。从这些结果中,我们看到更深的架构获得了更好的性能,而 VGGNet-16 获得了最好的性能。对于空间网络,VGGNet-16 优于浅层网络约 5%,对于时间网络,VGGNet-16 优于约 4%。非常深的双流卷积网络比原始的双流卷积网络高 3.4%。
值得注意的是,在我们之前在 THUMOS15 动作识别挑战赛 [2] 中的经验 [20] 中,我们尝试了非常深的双流 ConvNet,但结构更深的时间网络并没有产生良好的性能,如表 2 所示。在这个 THUMOS15 提交中,我们以与原始双流 ConvNet [12] 相同的方式训练非常深的双流 ConvNet,但没有使用前面提到的那些训练方法中。从非常深的双流 ConvNets 在两个数据集上的不同性能来看,我们推测我们提出的良好实践对于减少过度拟合的影响非常有效,因为 (a) 使用 ImageNet 模型预训练时间网络; (b) 使用更多的数据增强技术。
 表 1. UCF101 数据集上不同架构的性能比较。 (使用我们提出的良好做法)
表 1. UCF101 数据集上不同架构的性能比较。 (使用我们提出的良好做法)

表 2. THUMOS15 [2] 验证数据集上不同架构的性能比较。 (来自 [20],未使用我们提出的良好实践)
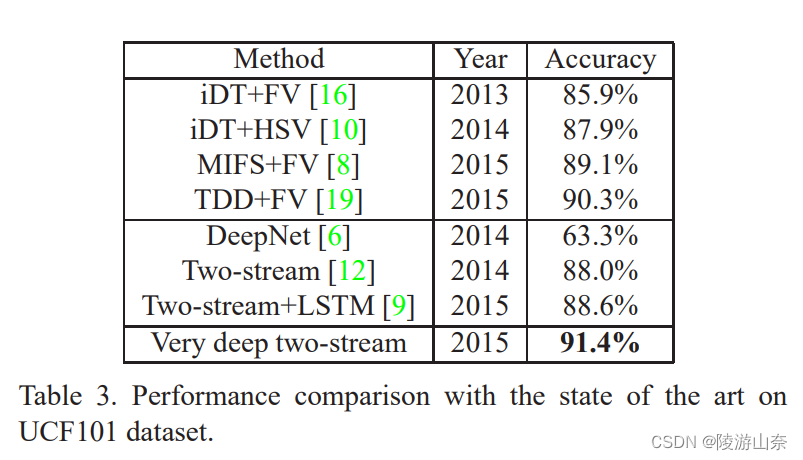
表 3. 在 UCF101 数据集上与现有技术的性能比较。
比较
最后,我们将我们的识别精度与最近的几种方法进行比较,结果如表 3 所示。我们首先与改进轨迹 (iDT) [16] 等手工特征的 Fisher 向量表示或轨迹池化深度卷积描述符 (TDD) [19] 等深度学习特征进行比较。(翻译的不好,但是大体意思Ok)我们的结果优于所有这些 Fisher 向量表示。其次,我们将非常深的双流 ConvNets 与其他深度网络(如 DeepNets [6])和带有循环神经网络的双流 ConvNets [9] 进行比较。我们看到我们提出的非常深的模型优于以前的模型,并且比最好的结果好 2.8%。
4.结论
在这项工作中,我们评估了非常深的两流 ConvNets 以进行动作识别。由于动作识别数据集非常小,我们提出了几个用于训练非常深的双流 ConvNet 的良好实践。通过我们精心设计的训练策略,所提出的非常深的两流 ConvNets 在 UCF101 数据集上实现了 91.4% 的识别准确率。同时,我们将著名的 Caffe 工具箱扩展为高效、低内存消耗的多 GPU 实现。















 3044
3044











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









