






在一个风和日丽的下午,女朋友拿出手机,只听到一声“TiMi~”,她便愉快的打起了王者荣耀。
在经过几波激烈的团战后,我耳边就听到了女朋友的吐槽:“我怎么一打团就掉帧卡顿。网络460,这Android手机真是卡的不行,是不是该换手机了”, 然后她对我使了使眼色,对我进行了暗示。
我这人打小就聪明,这么简单的暗示我怎么可能会不懂呢?所以我便坐了起来说道:“这可能还真不是手机问题,有可能是它们的软件需要做性能优化了”。
女朋友白了我一眼说:“性能优化?那是什么东西”。结果我一下来了兴致,势必要和女朋友唠唠性能优化的那些事儿!
如何做性能优化?
“你快说啊,性能优化是什么,该怎么去做性能优化呢?”女朋友嘟囔着。
“汽车有三大件,电脑和手机有五大件,即:输入、输出、运算器、控制器、存储器。 只是运算器和控制器都被集成在一块芯片上了,叫做CPU。所谓性能优化,其实就是让我们的App能够合理且充分的使用五大件,来让App能更稳定且高效的运行,主要优化点还是在CPU和存储器上”,
“我还是不太理解,为什么优化这两个点后,App就能稳定高效的运行了呢?”女朋友挠着脑袋问道。
“手机软件上的每个界面,每个功能,每个交互行为最终都会转换成为一条条机器指令,而这些机器指令是要依靠CPU去计算渲染执行的,如果CPU利用不合理则会出现卡顿,启动或者运行速度缓慢甚至出现ANR(Application Not Responding)异常。然而执行这些功能又离不开数据存储,如果存储器利用不合理,轻则存储空间浪费,重则出现OOM异常而导致应用崩溃”
“听起来好高级,快快,那我该怎么针对这两个硬件去做优化呢?”女朋友突然兴奋了起来。
我才不会告诉她最好的办法就是买更好的CPU和存储器呢,不然几个月工资又没了。所以只好说道:“我们无法直接优化这两个硬件,但在硬件层和应用层,中间还隔了一个操作系统层,这个操作系统的作用就是给我们的软件分配运行时所需要的硬件资源,所以现在目标就很明确了,想要做好性能优化,就需要我们分别在操作系统层和应用层对如何利用CPU和存储器进行优化”
因为篇幅原因,这一篇文章仅仅只介绍CPU优化了,如果对大家有帮助,文章受欢迎的话(暗示三连),后续我继续更新内存优化或者其他方面的优化。
一、CPU 优化 (速度优化)
“优化CPU可以加快启动速度、增加打开页面速度,减少卡顿,有这么神奇吗?那这底层原理是什么呀?”女朋友又好奇的问道。
“难得你这么好奇,那我就来给你说道说道,我前面不是说了吗,App的UI界面渲染,行为交互,功能运算等等操作最终都会转换成为一条条机器指令,而这些机器指令是要依靠CPU去执行的,所以在面对同一功能时,如何让CPU以最短的时间去完成功能就是我们的首要目标,当我们想要提升某些场景(如启动、打开页面、渲染动画等)的速度时,本质上就是降低 CPU 执行完这些场景指令的时间,这个时间简称为 CPU 时间,而程序所消耗 CPU 时间的计算公式:CPU 时间 = 程序执行所需的时钟周期数 * 时钟周期时间,其中的 程序执行所需的时钟周期数 = 程序指令数 * 每条指令的平均时钟周期”
“哎哎哎,你等等,上面的那几项因子是什么,我不太懂,你给解释解释呗”,女朋友说道。
“好的,这就给你解释解释:“
- 程序执行所需的时钟周期数:CPU的所有操作都是以时钟周期为基础来计算的,每个时钟周期都会执行一个指令或完成一个操作。因为程序有若干代码,所以完成这些代码所需要的时钟周期总数就是程序执行所需的时钟周期数。
- 时钟周期时间:指CPU完成一次执行所需的时间,即:一个时钟周期的时间,它通常以纳秒(ns)或皮秒(ps)为单位来表示,时钟周期时间越短,CPU的运行速度就越快,它的倒数也就是时钟周期频率,1 纳秒的时钟周期时间就是 1 GHZ 的时钟周期频率,厂商发布新手机或者我们购买新手机时,都或多或少会提到 CPU 的时钟频率,比如高通骁龙 888 这款 CPU 的时钟频率是 2.8 GHZ,
这个指标也是衡量 CPU 性能最重要的一个指标。
- 程序指令数:程序代码编译成机器码指令后的指令数量。
- 每条指令的平均时钟周期:指令执行完毕所消耗的平均时间周期,指令不同所需的时钟周期数也不同。对于一些简单的单字节指令,在取指令周期中,指令取出到指令寄存器后会立即译码执行,不再需要其它的时钟周期。对于一些比较复杂的指令,例如转移指令、乘法指令,则需要两个或者两个以上的时钟周期。
”所以底层原理就出来啦,针对以上公式,我们只要对上述的任何一项因子进行优化都可以达到目的,所以我们的优化方法论就是:①.减少程序指令数、②.降低每条指令的平均时钟周期、③.降低时钟周期的时间、④.其他优化方案。“,我又补充到。
女朋友皱着眉疑惑的说道:“你这些我大致听懂了,可是都太理论了,具体该怎么去做呢?”
“哎,真拿你这个好奇宝宝没办法,好吧,那我就逐一为你展开讲解吧:”

1. 减少程序指令数
我们的程序由Java代码在经过编译和汇编后,最终会转变成机器指令,当我们明明可以用更少的机器指令去完成一项任务,却因为一些不好的代码习惯或者知识的缺乏而需要更多机器指令才能完成,这就会使我们的程序变得更加缓慢。所以,通过减少程序的指令数来提升运行速度,是我们最常用和最直接的优化方案,比如下面这些方案都是通过减少指令数来提升速度的:
1.1 利用手机的多核
当我们将要提速的场景的程序指令交给多个 CPU 同时执行时,对于单个 CPU 来说,需要执行的指令数就变少了,那 CPU 时间自然就降低了,也就是并发的思想。但要注意的是,并发只有在多核下才能实现。例如我现在有一个8核的Android手机,那如何才能利用手机的多核呢?答案是:使用多线程,8核的手机,就能同时并发的运行8个线程,当然,如果想要更高效合理的使用多线程,那么就必须学会使用线程池。
如何合理的使用线程 —— 线程池
线程池对于每一个开发者都是非常重要的,他除了能更好的利用多核CPU之外,还能够降低虚拟内存的占用,对于Linux系统而言,线程其实就是一个精简的进程,线程的创建最终是调用clone这个内核函数,而这个clone函数实际上创建的是一个进程 (官网描述:These system calls create a new ("child") process, in a manner similar to fork),它本身是占用了虚拟内存空间的,如果我们不合理的到处使用“野线程”,就会造成虚拟内存空间的浪费。然而使用线程池,不仅可以更好的对线程进行收敛,还能给线程进行分类,既能更好的统一管理应用的线程,又能更好的发挥出CPU的性能。那说了这么多,怎样才算是合理的使用线程呢?具体应该包含以下几个条件:
- 线程不能太多也不能太少: 线程太多会浪费 CPU 资源用于任务调度上,并且会减少了核心线程在单位时间内所能消耗的 CPU 资源。线程太少了则发挥不出 CPU 的性能,浪费了 CPU 资源。
- 减少线程创建及状态切换导致的 CPU 损耗: 线程的频繁创建销毁,或者频繁的状态切换,如休眠状态切换到运行状态,或者运行状态切换到休眠状态,这些都是对 CPU 资源的损耗。
然而满足以上条件最好的方法就是使用线程池,这要求我们在应用开发过程中使用的线程最好全部都是从线程池中创建的,并且还要能正确的使用线程池,关于如何正确的使用线程池,我们可以从以下三个方面入手:
- 如何创建线程池;
- 线程池的类型和特性;
- 如何使用线程池;
线程池的类型及特点
线程池的分类方法比较多,如果我们按照业务中使用的频繁程度来做分类,主要分为以下三类线程池:
- CPU密集型线程池:用来处理 CPU 类型任务,如计算,逻辑操作,UI 渲染等。例如:newFixedThreadPool、newWorkStealingPool
- IO密集型线程池:用来处理 IO 类型任务,如拉取网络数据,往本地磁盘、数据读写数据等。例如:newCachedThreadPool
- 其他线程池:自定义用来满足业务独特化需求的线程池。例如:newScheduledThreadPool(定时任务线程池)、newSingleThreadExecutor(单一线程池)等等。
接下来我们通过查看源码,看到Executor这个对象里就有十多个newXXXThreadPool的静态方法来创建线程池。
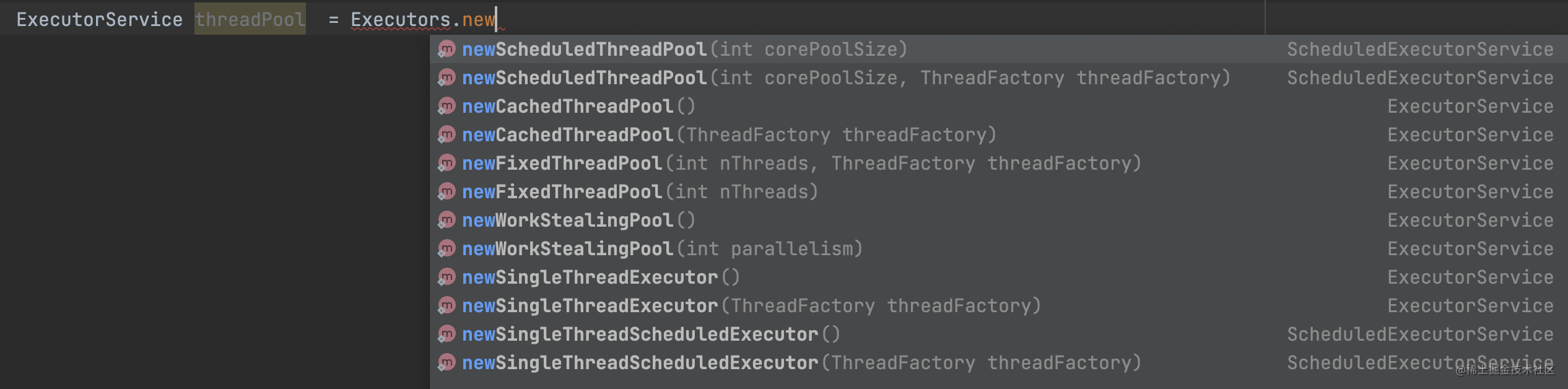
下表介绍了上图中出现的那些线程池:
| 线程池类型 | 适用场景 | 特点 |
|---|---|---|
| newSingleThreadExecutor | 适用于需要保证任务按照顺序执行的场景,如日志处理、数据库连接池等 | 只有一个线程,任务按照顺序执行 |
| newFixedThreadPool | 适用于需要控制线程数量的场景,如服务器处理请求、并发下载等 | 固定数量的线程池,可以控制线程数量 |
| newCachedThreadPool | 适用于执行大量短期异步任务的场景,如网络爬虫、推送系统等 | 根据需要创建线程,适用于执行大量短期异步任务的场景 |
| newSingleThreadScheduledExecutor | 适用于需要按照顺序执行定时任务的场景,如定时备份、定时清理等 | 只有一个线程,可以按照顺序执行定时任务 |
| newScheduledThreadPool | 适用于需要按照顺序执行定时任务,并且需要控制线程数量的场景 | 可以控制线程数量,可以按照顺序执行定时任务 |
| newWorkStealingPool | 适用于需要执行大量独立任务的场景,如图像处理、视频编码等 | 根据需要创建线程,可以执行大量独立任务 |
不同类型的线程池有不同的职责,专门用来处理对应类型的任务,下面一起来看一下如何创建不同类型的线程池。
创建线程池
上面虽然出现了那么多线程池,但它们实际都是通过ThreadPoolExecutor这个对象创建的,这些线程池其实是ThreadPoolExecutor不同入参的实例,所以接下来我们对ThreadPoolExecutor做进一步的分析,我们可以先看一下它的构造函数:
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue<Runnable> workQueue,
ThreadFactory threadFactory,
RejectedExecutionHandler handler)
如果我们将 ThreadPoolExecutor 构造函数中的入参全部熟悉了,我们也就完全掌握了线程池的用法,下面就详细讲解一下该构造函数中每个入参的含义:
| 入参 | 说明 |
|---|---|
| int corePoolSize | 表示核心线程数量:在创建了线程池后,线程池中此时线程数为 0,当有任务来到需要执行时,就会创建一个线程去执行任务,当线程池中的线程数目达到 corePoolSize 后,就会把后面到来的任务放到缓存队列中。除非手动调用了allowCoreThreadTimeOut(boolean) 这个方法,用来申明核心线程需要退出,否则核心线程启动后便一直是存活不退出的状态。 |
| int maximumPoolSize | 表示线程池中最多能创建线程数量:当核心线程全在执行任务时,又有新任务到来,任务会放在缓存队列中,如果缓存队列也满了,才会启动新的线程来执行这些任务,这些线程也成为非核心线程,非核心线程的数量加上核心线程的数量就是线程池最多能创建的线程数量。 |
| long keepAliveTime | 表示非核心线程的存活时间:当线程池中某个非核心线程线程空闲的时间达到 keepAliveTime,该线程就会退出,直到线程池中的线程数不超过 corePoolSize,所以这个参数对核心线程是无效的,因为核心线程不会退出,只对非核心线程有效。 |
| TimeUnit unit | 表示 keepAliveTime 的时间单位,如秒、毫秒等 |
| BlockingQueue workQueue | 表示任务缓存队列:常见的缓存队列有这些:1. LinkedBlockingDeque 是一个双向的并发队列,主要用于 CPU 线程池;2. SynchronousQueue 虽然也是一个队列,但它并不能存储 task,所以每当这个队列添加一个 task 时,由于超出了存储队列的容量线程,线程池这个时候都会创建一个新线程来执行这个 task,用于 IO 线程池中。 |
| ThreadFactory threadFactory | 线程工厂:可自定义创建线程的方式,设置线程名称,可以默认使用Executors.DefaultThreadFactory(“线程名”),在虚拟内存优化时,也提到过可以使用自定义的线程工厂,来创建栈空间只有 512 KB 的线程。 |
| RejectedExecutionHandler handler | 异常处理:所有因异常而无法执行的线程,比如线程池已经满了之后,新的任务就无法执行了,都会放在 RejectedExecutionHandler 中做兜底处理。 |
这里需要特别注意,只有缓存队列容量满了,即缓存队列中缓存的 task 达到上限时,才会开始创建非核心线程。
通过上面对入参的解释,我们基本能看懂 Executors 对象中创建的线程池代码,也能自己去创建一个线程池了,但线程池的分类很多,且参数也比较复杂,我们如果想要更合理的使用线程池,还需要对如何设置线程池的参数做进一步了解。
如何合理使用线程池
这里我们仅针对CPU密集型线程池和 IO密集型线程池去做分析,如何去设置以上参数才能更合理更高效的使用线程池, 其他线程池因为属于自定义用于完成特定业务需求的场景,且不怎么使用,所以这里暂不分析,不过大家看完针对CPU密集型线程池和 IO密集型线程池的优化后,应该也能举一反三,自己结合实际场景去优化自定义线程池。
CPU密集型线程池
首先是 corePoolSize 参数(核心线程数)。CPU密集型线程池是用来执行 CPU 类型任务的,所以它的核心线程数量一般为 CPU 的核数,理想情况下等于核数的线程数量性能是最高的,因为我们既能充分发挥 CPU 的性能,还减少了频繁调度导致的 CPU 损耗。不过,程序在实际运行过程中无法达到理想情况,所以将核心线程数设置为 CPU 核数个可能不是最优的,但绝对是最稳妥且相对较优的方案。
接下来是maximumPoolSize(最大线程数)。通常来说,CPU密集型线程池的最大线程数就是核心线程数,因为 CPU 的最大利用率就是每个核都满载,想要达到满载只需要核数个并发线程就行了。另外,线程的创建和销毁都需要消耗系统资源,而且线程数量过多还会导致线程切换的开销增加,从而影响系统的性能,所以我们这样进行设置,CPU 资源就能被完全发挥。
既然最大线程数就是核心线程数,那 keepAliveTime 这个非核心线程数的存活时间就是零了。
然后是workQueue缓存队列。CPU 线程池中统一使用 LinkedBlockingDeque,这是一个可以设置容量并支持并发的队列。由于 CPU 线程池的线程数量较少,如果较多任务来临的话,就需要放在存储队列中,所以这个存储队列不能太小,否则队列满了之后,新来的任务就会进入到错误兜底的处理逻辑中。所以,我们可以结合应用的规模和业务需求,将存储队列设置的尽可能大,但为了程序的性能和稳定性,不建议设置为无限大。如果程序有些异常的死循环逻辑不断地往队列添加任务,而这个队列就能一直接受任务,但是却会导致程序表现异常,因为 CPU 线程池全部用来执行这个异常任务了。但是当我们将这个队列设置成有限的,比如 64 个,那这个异常的死循环就会将队列打满,让接下来的任务进入到兜底逻辑中,而我们可以在兜底逻辑中设置监控,就能及时发现这个异常了。
最后是ThreadFactory 线程工厂和 RejectedExecutionHandler 兜底处理的 handler 逻辑,可以使用默认的,如果我们有特别的需要,比如通过 ThreadFactory 设置优先级,线程名或者优化线程栈大小,或者在兜底逻辑中增加监控,都可以通过继承对应的类来进行扩展。
我们通过查看 Exectors 工具类,就可以发现通过 newFixedThreadPool 创建的线程池实际上就是 CPU 线程池的,通过命名也可以猜到,这是一个线程数固定的线程池,所以符合 CPU 线程池线程数固定是 CPU 核数个这一特性。我们在使用的时候,还可以通过带 ThreadFactory 入参的这个方法 ,调整 FixedThreadPool 线程池的线程优先级。
public static ExecutorService newFixedThreadPool(int nThreads, ThreadFactory threadFactory) {
return new ThreadPoolExecutor(nThreads, nThreads,
0L, TimeUnit.MILLISECONDS,
new LinkedBlockingQueue<Runnable>(),
threadFactory);
}
IO密集型线程池
IO密集型线程池主要用来执行 IO 任务,IO 任务实际上消耗的 CPU 资源是非常少的,当我们要读写数据的时候,会交给 DMA (直接存储器访问)芯片去做,此时调度器就会把 CPU 资源切换给其他的线程去使用。因为 IO 任务对 CPU 资源消耗少,所以每来一个 IO 任务就直接启动一个线程去执行它就行了,不需要放入缓存队列中,即使此时执行了非常多的 IO 任务,也都是 DMA 芯片在处理,和 CPU 无关。了解了这一特性,我们再来看看 IO 线程池的入参如何设置。
首先是corePoolSize(核线程数)。 这个设置多少没有定性规定,它和我们 App 的类型有关. 如果 IO 任务比较多,比如新闻咨询类的应用或者大型应用,可以设置得多一些,十几个也可以,太少了就会因为 IO 线程频率创建和销毁而产生损耗。如果应用较少,IO 任务不多,直接设置为 0 个也没问题。
maximumPoolSize (最大线程数)。这个可以多设置一些,确保每个 IO 任务都能有线程来执行,毕竟 IO 任务对 CPU 的消耗不高。一般来说,中小型应用设置 60 个左右就足够了,大型应用则可以设置 100 个以上。这里不建议将数量设置得特别大,是为了防止程序出现异常 BUG创建大量的 IO 线程(比如某个场景标志位错误导致逻辑不退出,然后一直创建 IO 线程),虽然 IO 任务执行消耗 CPU 资源不多,但是线程的创建和销毁是需要消耗 CPU 资源的。
然后是workQueue缓存队列。我们把它设置为 SynchronousQueue队列,它是一个容量为0的队列,因为通过上述参数表格介绍,该队列是不能存储task任务的,所以一旦有新的线程任务过来,会立刻创建一个新的线程去执行。这也符合 IO 密集型线程池的理念,首先本身执行不需要使用太多CPU资源,其次 IO 需要高响应。
了解了上面的知识,我们再来看 Exectors 工具类,发现通过 newCacheThreadPool 创建的线程池实际上就是对应 IO 线程池的,但是通过 newCacheThreadPool 创建出来的 IO 线程池并不是最优的。我们可以看到,它的核心线程池数量为 0,并且最大线程数量为无限大。我们完全可以抛弃Exectors 提供的方法,按照自己的规则去创建 IO 线程池。这里需要注意的是,我们在设置 IO 线程池的线程优先级时,需要比 CPU 线程池的线程优先级高一些,因为 IO 线程中的任务是不怎么消耗 CPU 资源的,优先级也更高一些,可以避免得不到调度的情况出现。
public static ExecutorService newCachedThreadPool(ThreadFactory threadFactory) {
return new ThreadPoolExecutor(0, Integer.MAX_VALUE,
60L, TimeUnit.SECONDS,
new SynchronousQueue<Runnable>(),
threadFactory);
}
这一段详细介绍了线程池的知识,包括如何创建线程池,以及线程池的种类和特性,特别是CPU密集型线程池和IO密集型线程池的定义,它们是如何创建的。当我们能了解线程池的原理、了解如何合理设置线程池的数据、了解各类线程池的特性后,使用线程池就容易很多了,将特定的任务放入特定的线程池中执行,各司其职即可,接下来我们继续讲述其他的优化方案。
1.2 养成良好的代码习惯使和使用更优的算法或数据结构
这一点很好理解,同样的功能用更简洁或更优的代码来实现,指令数也会减少,指令数少了程序的速度自然也就快了。具体落地这一类优化时,我们可以用抓 trace 或者在函数前后统计耗时的方式去分析耗时,将这些耗时久的方法用更优的方式实现。至于如何做好这一点,这里也给出几个例子:
A. 使用合适的数据结构和算法:选择适当的数据结构和算法可以减少代码的复杂性和执行时间。例如,使用哈希表(HashMap)而不是线性搜索列表(ArrayList)可以大大提高查找效率。
// 线性搜索列表的示例
ArrayList<String> names = new ArrayList<>();
String searchName = "John";
for (String name : names) {
if (name.equals(searchName)) {
// 执行操作
break;
}
}
// 使用哈希表的示例
HashMap<String, Integer> namesMap = new HashMap<>();
String searchName = "John";
if (namesMap.containsKey(searchName)) {
// 执行操作
}
B. 避免重复计算:如果某个计算量较大的操作结果在多个地方都被使用到,可以考虑将结果缓存起来,避免重复计算。
// 重复计算的示例
int result1 = complexCalculation();
// 执行其他操作
int result2 = complexCalculation();
// 避免重复计算的示例
int result = complexCalculation();
int result1 = result;
// 执行其他操作
int result2 = result;
C. 使用缓存或缓存策略:对于一些需要经过复杂计算和频繁读取的数据,可以考虑使用缓存来避免重复的访问或计算,这与上面的“优化点B”可结合使用。
// 没有缓存的示例
public int calculateExpensiveOperation(int input) {
// 执行复杂计算
return result;
}
// 使用缓存的示例
private Map<Integer, Integer> cache = new HashMap<>();
public int calculateExpensiveOperation(int input) {
if (cache.containsKey(input)) {
return cache.get(input);
} else {
int result = performExpensiveOperation(input);
cache.put(input, result);
return result;
}
}
D. 减少不必要的对象创建:避免在循环或频繁执行的代码块中创建不必要的对象,尽量重用已有对象。
// 不必要的对象创建示例
for (int i = 0; i < array.length; i++) {
String itemString = new String(array[i]);
// 执行操作
}
// 减少对象创建的示例
String itemString = null;
for (int i = 0; i < array.length; i++) {
if (itemString == null) {
itemString = new String(array[i]);
} else {
itemString = itemString.concat(array[i]);
}
// 执行操作
}
E. 多使用资源引用:当需要使用应用程序资源(例如字符串、图标等)时,使用资源引用而不是硬编码的值,这样的代码习惯不仅可以提高代码的可维护性,而且还能减少指令数。
// 硬编码的字符串示例
String title = "Welcome to my app";
// 使用资源引用的示例
String title = getResources().getString(R.string.app_title);
F. 使用StringBuilder拼接字符串:在需要频繁拼接字符串的情况下,使用StringBuilder类而不是字符串拼接操作符(+),可以提高性能并减少指令数。因为在Java中,字符串是不可变的,这意味着每次对字符串进行拼接、修改或连接操作时,都会创建一个新的字符串对象。这种频繁的字符串对象创建和拷贝操作会占用额外的内存和消耗大量的时间。而StringBuilder类是可变的,它提供了一种高效的方式来构建和修改字符串,而无需每次都创建新的字符串对象。
// 字符串拼接操作符的示例
String result = "Hello, " + name + "!";
// 使用StringBuilder的示例
StringBuilder sb = new StringBuilder();
sb.append("Hello, ");
sb.append(name);
sb.append("!");
String result = sb.toString();
上面提到的这些方案都是我最常用的方案,基于减少程序指令数这一基本原理,还能衍生出很多方案来提升速度,这里没法一一列全,大家也可以自己想一想还能扩展出哪些方案出来。
1.3 利用CPU的闲置时刻
在 CPU 闲置的时候,执行预创建 View,预准备数据等预加载逻辑,将接下来可能会用到的View、布局、或者数据提前处理好,那么在打开这些场景时,指令数量由于预加载执行了一部分而变少了,运行速度自然也就变快了。
那为什么预加载任务要放在 CPU 的闲置时刻呢?如果预加载任务不是放在 CPU 的闲置时刻就会和核心场景抢占资源,导致核心场景速度变慢。比如,我们经常会在启动时预加载一些逻辑以此来提升后面场景的速度,但这样会导致启动变慢。如果把这些任务放在 CPU 闲置后再执行,就能做到既不影响启动的速度,又能提升后面场景的速度了。
那问题又来了,该怎么判断CPU的闲置时刻呢?我们可以启动一个定时任务,每 5 秒检测一次 CPU 是否已经闲置,如果已经闲置了,则回调通知各个业务进行预加载任务的执行(5 秒不是固定值,需要根据所开发应用的类型来调整)。这里推荐使用times函数来判断CPU是否闲置。
times()函数
进程用此函数获得自己和已终止子进程的时钟时间,用户CPU时间和系统CPU时间。返回值clock_t标示经过的墙上时钟时间。
<sys/times.h>头文件中.
原型: clock_t times(struct tms *buf); 正确返回墙上时钟经过时间, 出错返回-1 ;
其中参数类型struct tms为:
struct tms
{
clock_t tms_utime; //用户CPU时间
clock_t tms_stime; //系统CPU时间
clock_t tms_cutime; //以终止子进程的用户CPU时间
clock_t tms_cstime; //已终止子进程的系统CPU时间
};
因为 times 函数是一个系统函数,我们需要在 Native 层才能调用。所以我们直接写一个 Native 方法,然后在 Java 层通过 Jni 执行这个 Native 方法,就能高效获取到进行所消耗的 CPU 时间了。
#include <sys/times.h>
float getCpuTimes(JNIEnv *env) {
struct tms currentTms;
times(¤tTms);
return currentTms.tms_utime + currentTms.tms_stime;
}
现在我们已经通过 times 函数拿到了应用消耗的CPU时间,那该怎么计算CPU的使用率才能判断出CPU是否空闲呢?我们用这个公式可以进行判断 CPU 速率 = 单位时间内进程内消耗的 CPU 时间 / 单位时间。我们以 5 秒为例,则CPU速率如下:
//这里app的cpu时间都转换成了秒
float cpuSpeed = (beforeAppTime - curAppTime) / 5f;
当应用处于闲置状态时,CpuSpeed 一定在 0.1 以下
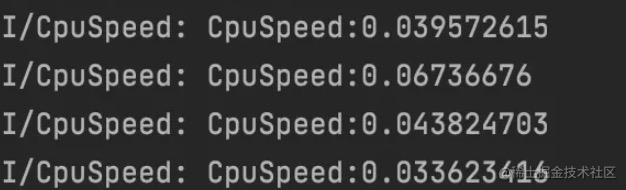
现在我们已经能够判断CPU是否处于闲置状态了,后续就可以在CPU闲置时做预处理工作来提升应用的运行速度了。
1.4 减少 CPU 的等待
如果某个线程或进程拥有 CPU 的时间片,但是 CPU 却在当前指令段停下来,长时间无法接着执行后面的代码指令的情况,都可以看做是 CPU 的等待。此时,CPU 之所无法继续执行后面的代码,可能是因为代码陷入了空循环导致 CPU 空转,或者 CPU 被切走去执行其他线程了。 总的来说,有两种情况经常导致 CPU 等待,一是等待锁,二是等待 IO。
等待锁优化
使用 Java 进行应用开发遇到多线程并发任务时,我们通常都用 synchronize 来对方法或者数据加锁。当这个锁被某一个线程持有时,另一个线程就需要等待锁释放后,才能对方法和数据进行访问。
请求 synchronize 锁的流程如下:首先判断这个锁是否被其他线程持有,如果持有则通过多次的循环来判断锁是否释放,这个过程就会导致 CPU 的空转,如果多次空转后还是无法获得锁,请求锁的线程便会陷入休眠并加入等待队列,待锁释放后被唤醒。从这个流程可以看到,请求锁时,不管是空转还是休眠都会导致当前线程无法获得 CPU 资源。如果这个线程是核心线程,比如主线程和渲染线程,就会导致应用的体验速度变慢。
因为锁相关的内容非常庞大,所以这里主要介绍下锁优化方法:
- 无锁比有锁好:除了不加锁,还有线程本地存储,偏向锁等方案,都属于无锁优化。
- 合理细化锁的粒度:比如将 Synchronize 锁住整个方法细化成只锁住方法内可能会产生线程安全的代码块。
- 避免在主线程或者渲染线程使用锁: 前面说到锁可能会阻塞线程,所以如果非要使用到锁,也应尽量避免在主线程或渲染线程上使用。
减少 IO 等待
当一个线程执行 IO 任务时,比如往内存读写数据,此时实际是 DMA(直接存储器访问) 芯片在执行操作,并不关 CPU 什么事。当前就会出现两种情况:
一是有其他线程执行 CPU 任务,任务调度器会将 CPU 切换给其他线程去使用。
二是没有其他 CPU 相关任务,CPU 就会一直等待,直到 DMA 芯片完成读写内存数据的操作,再接着执行后面的代码逻辑。
但不论是哪种情况,对于当前这个线程来说,执行完所有指令的时间变长了,也就是指令执行所消耗的平均时钟周期变长了。如果这个线程是主线程或者渲染线程,同样会导致应用运行速度变慢。
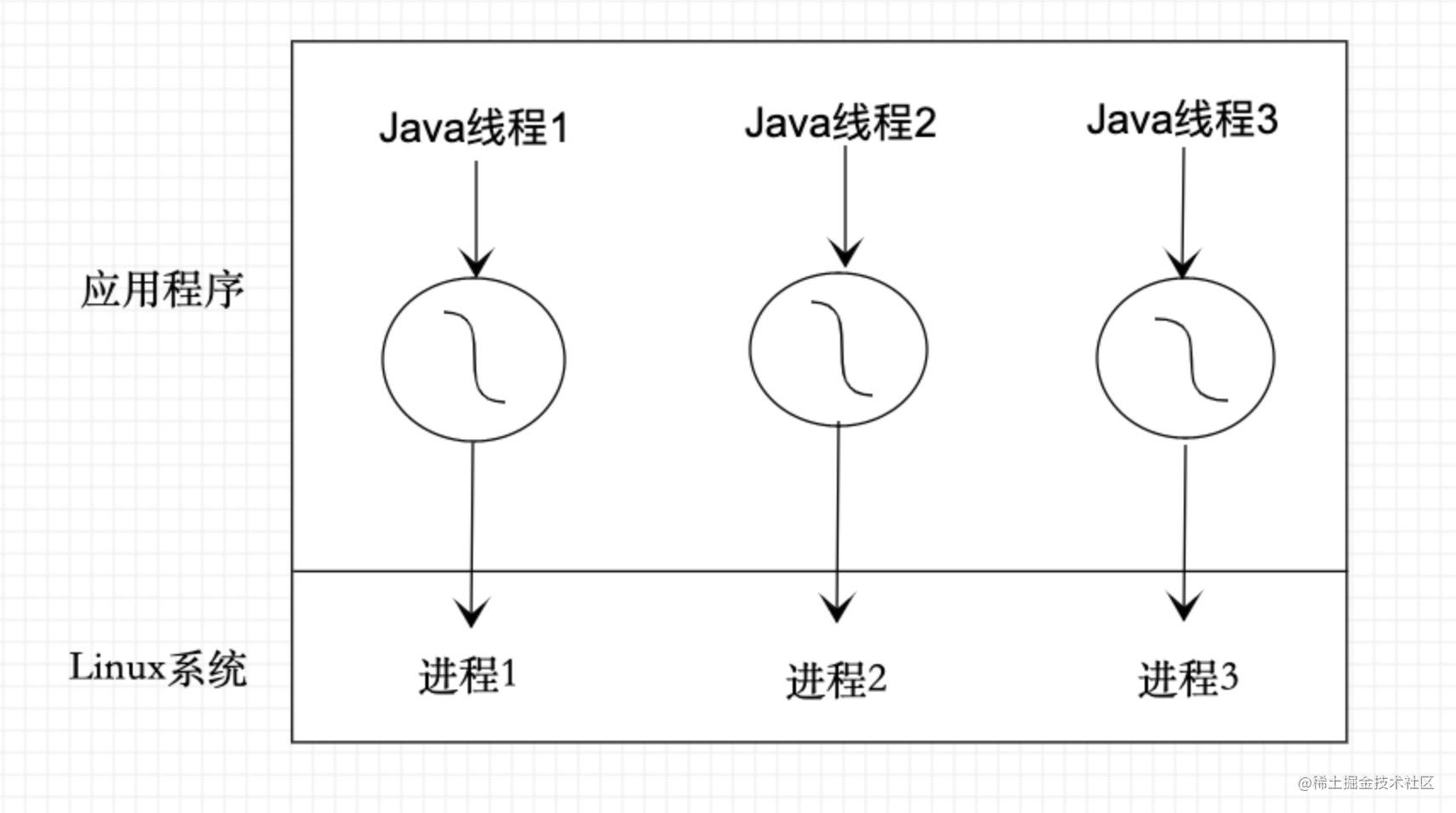
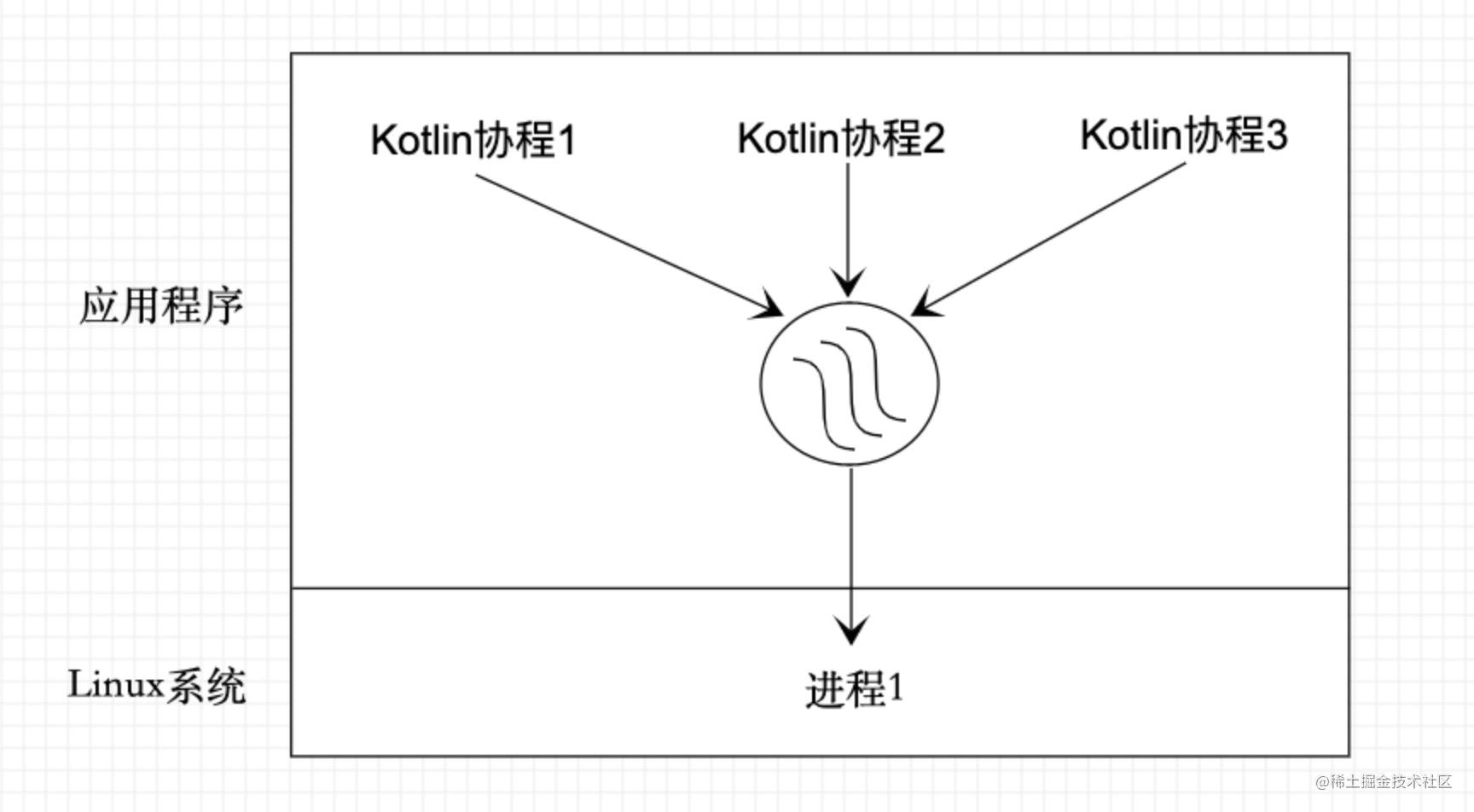
但你可能会有疑问,在通常情况下,我们需要请求网络或者等待IO任务的结果才能进行后面的逻辑,那这时候我们可以开一个子线程去执行IO或者请求网络呀,一样相当于是并发操作。但你有没有想过,万一你这个线程就已经是子线程了呢,或者已经有非常多的线程在处理任务了,或者此时线程池已经满了怎么办?抛开这些问题不谈,就连线程切换也是比较消耗资源的。那么有什么好的方法可以在遇到 IO 或者网络请求时不让这个线程休眠,而让它去做其他事呢?答案就是使用协程。
协程是什么?
Kotlin 官方文档上说,协程本质上是一个轻量级线程。 在上面描述的情况中,Java线程确实做不到,但是协程可以。因为一个 Java 线程实际上就是一个精简的进程 (这里我们在上文讲述线程池的时候有解释过),进程的状态在很多时候是受操作系统管控的,比如调度器调度的时候,会切换进程状态;等待 IO 时,进程会陷入休眠等等。但 协程不受内存调度器的限制,当你创建协程时,这些协程实际都在同一个进程上运行,Kotlin 内部实现了调度机制,就像CPU的进程调度机制一样,去调度执行这个协程任务。这时协程所在的这个线程就不会因为 IO 任务而被休眠阻塞(官网称为「非阻塞式挂起」)。
我们在Kotlin上通常是这样使用协程的:
// 使用 coroutineScope 函数创建一个新的协程作用域,并在该作用域中启动两个子协程。
// 在 coroutineScope 函数执行完成后,会等待所有子协程执行完成后再继续执行。
// suspend 关键字是用来标记挂起函数,挂起函数可以在异步操作中暂停协程的执行,等待异步操作完成后再恢复协程的执行。
suspend fun doSomething() {
coroutineScope {
launch {
// 异步操作
}
launch {
// 异步操作
}
}
// 所有子协程执行完成后继续执行
}
好了,什么是协程?现在应该更清楚了,协程就是 launch{} 大括号创建的代码块,创建的一个个 launch{} 就是一个个协程。
协程的好处
- 降低 IO 等待,有更高效的运行效率。
- 消除回调地狱,用同步的方式写异步的代码。
我们就针对上述两点好处讲解一下。协程降低 IO 等待不仅仅只是上文提到的可以进行非阻塞式挂起从而让线程一直处于运行状态,避免线程切换造成的资源消耗。更关键它在某些场景下能提高 IO 或者网络请求速度。例如:有这么一个场景,我们需要在这多个请求结束后,将信息进行整理合并,然后再更新UI。这在Java上实现是很困难的,通常我们会通过使用先后请求来代替同时请求(没错,我以前就是这么干的),在实际开发中如果这样写,本来能够并行处理的请求被强制通过串行的方式去实现,可能会导致等待时间长了一倍,也就是性能差了一倍。就像下面这样,并且如果业务一多,可能会形成回调地狱:
api.getName(params) { name ->
api.getAvatar(params) { avatar ->
show(merge(name, avatar))
}
}
上述使用Kotlin代码看起来似乎也还好,可是如果使用Java就不一样了:
api.getName(new Callback<String>() {
@Override
public void success(String name) {
api.getAvatar(new Callback<String> {
@Override
public void success(String url) {
User uersInfo = merge(name, url);
runOnUiThread(new Runnable() {
// 主线程中设置UI
@Override
public void run() {
show(userInfo);
}
}
}
@Override
public void failure(Exception e) {
···
}
});
}
@Override
public void failure(Exception e) {
...
}
});
而如果使用协程,可以直接把两个并行请求写成上下两行,最后再把结果进行合并即可:
coroutineScope.launch(Dispatchers.Main) {
val name = async { api.getName(params) } // 通过网络请求获取用户名字
val avatar = async { api.getAvatar(params) } // 通过网络请求获取用户头像
val merged = mergeInfo(name, avatar) // 合并结果
show(merged) // 更新 UI
}
通过这一个例子我们可以看到,使用协程不仅仅轻松的把串行请求改为了并行请求,而且还消除了回调地狱,用同步的方式写异步的代码。提高运行效率的同时还让复杂的并发代码,变得简单且清晰了。
1.5 通过其他设备来减少当前设备程序的指令数
这一点也衍生很多优化方案,比如 Google 商店会把某些设备中程序的机器码上传,这样其他用户下载这个程序时,便不需要自己的设备再进行编译操作,因为提升了安装或者启动速度。再比如在打开一些 WebView 网页时,服务端会通过预渲染处理,将 IO 数据都处理完成,直接展示给用户一个静态页面,这样就能极大提高页面打开速度。
2. 降低时钟周期时间
想要降低手机的时钟周期,一般只能通过升级 CPU 做到,每次新出一款 CPU,相比上一代,不仅在时钟周期时间上有优化,每个周期内可执行的指令也都会有优化。比如高通骁龙 888 这款 CPU 的大核时钟周期频率为 2.84GHz,而最新的 Gen 2 这款 CPU 则达到了 3.50GHz。
虽然我们没法降低设备的时钟周期,但是应该避免设备提高时钟周期时间,也就是降频现象,当手机发热发烫时,CPU 往往都会通过降频来减少设备的发热现象,具体的方式就是通过合理的线程使用或者代码逻辑优化,来减少程序长时间超负荷的使用 CPU。
3. 降低每条指令的平均时间周期
在降低每条指令的平均时间周期上,我们能做的其实也不多,因为它和 CPU 的性能有很大的关系,但除了 CPU 的性能,以下几个方面也会影响到指令的时间周期。
编程语言:Java 翻译成机器码后有更多的简介调用,所以比 C++ 代码编译成的机器码指令的平均时间周期更长。
编译程序:一个好的编译程序可以通过优化指令来降低程序指令的平均时间周期。
降低 IO 等待:从严格意义来说,IO 等待的时间并不能算到指令执行的耗时中,因为 CPU 在等待 IO 时会休眠或者去执行其他任务。但是等待 IO 会使执行完指令的时间变长,所以这里依然把减少 IO 等待算入是降低每条指令的平均时间周期的优化方案之一。上述有介绍过如何降低IO等待的方法。
4. 其他优化方案
对于上述 ①.减少程序指令数、②.降低每条指令的平均时钟周期、③.降低时钟周期的时间,这三种优化方案来看,它们通过对应用层代码的优化实现了性能优化,是属于应用层方面的优化。而我们在上文说过优化还可以从操作系统层面去进行优化,接下来的其他优化方案中,就揭示了如何从操作系统层面去做性能优化的。
4.1 提升缓存的命中率 —— Dex类文件重排序
这一优化方案是从操作系统层面和硬件层去思考的。我们的程序的运行过程,其实是CPU在不断读取指令并执行指令的过程,CPU在读取指令时,首先会从寄存器读取,如果寄存器里没有再从高速缓存读取,最后才从主存读取,读取到指令后,也会先从主存加载到高速缓存,再从高速缓存加载到寄存器中。高速缓存其实就是若干个cache line大小的块,这个cache line大小和CPU型号有关,主流的是64字节。
高速缓存在读取数据时,假设需要的指令数据只有4个字节,高速缓存也会读满一个 cache line 大小的数据(也就是64个字节),那么剩下的60个字节实际就用不到了,所以我们如果能想办法把这剩下的60个字节的数据给用上,这就能够有效的提升缓存命中率,从而降低高速缓存向主存读取数据的次数了,就能够让CPU更快的执行指令了。
“所以说了这么多,到底怎么把剩下的60个字节给用上呢,那你倒是说呀!”女朋友又着急的说道。
“我知道你很急,但是你先别急,那接下来就给你讲解下吧,想要有效利用剩下的60字节,就需要用到局部性原理了!”
局部性原理
局部性原理是计算机系统设计中的重要原则,它可以帮助提高系统的性能和效率。例如,CPU缓存的设计就是基于局部性原理,它将最近访问的数据和指令存储在高速缓存中,以便快速访问。具体来说,局部性原理主要分为两个方面,分别是时间局部性和空间局部性。
时间局部性是指在一个时间段内,如果一个数据或指令被访问过一次,那么在不久的将来它很可能会再次被访问。这是因为程序的执行通常具有循环、分支等结构,会反复使用同一段代码或数据。
空间局部性是指在一个时间段内,如果一个数据或指令被访问过一次,那么与它相邻的数据或指令也很可能会被访问。目前,高速缓存读取数据就是按照空间局部性来读的,也就是读取当前需要被使用的数据,以及在内存上紧挨着的数据,总共凑齐 cache line 大小的数据后再加载进高速缓存中。
知道了局部性原理后,那我们该怎么利用呢?因为在我们的App启动执行时,对于第一次用到的对象,高速缓存中是没有的,所以这时候需要去主存读取数据,然而读取到的不仅仅只有这一个对象数据,后面还会紧挨着许多数据,直到数据量达到64字节。这时如果后面紧挨着的对象在接下来马上就会用到,那么高速缓存下次就不用再去主存读数据了,这样CPU减少等待时间,就能更快的执行指令,我们的程序也能运行的更加流畅。
当我们的项目被编译成Apk包后,所有的class文件会被进行整合,然后放在dex文件中。然而dex文件中的class文件顺序并不是按照程序执行顺序来存放的,因为我们也不知道class文件的执行顺序,这样就会导致我们读取了4个字节的数据,那么后面剩下的60字节的数据接下来将不会用到。但是如果我们能提前将程序运行一遍,把其中class对象的使用顺序给收集起来,再按这个顺序重新调整dex文件中class文件的顺序,这样在应用启动时,就能把所需要的class文件加载进高速缓存中,应用的启动速度自然就变快了。
上面的流程是美好的,但实现起来还是很复杂的,我们需要对每个对象插桩后才能知道对象的先后运行顺序,而且我们也需要对 dex 文件结构非常熟悉,这样才能正确重排 dex 文件中类文件的顺序。
但是,非常幸运,目前有成熟的开源框架可以直接使用,那就是Facebook的开源工具:redex
那么接下来就讲解下Redex的使用,还有我踩的一些坑,我使用的是MAC电脑,其他系统的没有尝试过。
Redex 的使用方法
- 安装 Redex 所需依赖
// 下载相关环境,安装这些库时,可能会遇到权限问题,有时需要使用管理员权限或者修改文件夹的所有者和权限
xcode-select --install
brew install autoconf automake libtool python3
brew install boost jsoncpp
- 下载安装 Redx
// 克隆Redex项目
git clone https://github.com/facebook/redex.git cd redex
cd redex
// 对 Redex进行编译和安装
autoreconf -ivf && ./configure && make
sudo make install
- 配置 Redex
// 在 redex/config/default.config 中找到配置文件
{
"redex" : {
"passes" : [
// 默认开启的配置若干条,这里我给默认配置全部移除了,因为会有 ClassNotFoundException 错误
....
....
// 在配置文件增加 InterDexPass 开启,以及新增 coldstart_classes,指定 class 调用顺序
"InterDexPass"
],
"coldstart_classes" : "app_list_of_classes.txt" // class调用顺序列表
}
}
- 获得启动class加载顺序列表
// 1. 获取你的应用包名 pid
adb shell ps | grep <应用包名>
// 2. 收集堆内存,release 版本需要 root 权限, debug版本不需要 root
adb root
adb shell am dumpheap <应用Pid> /data/local/tmp/SOMEDUMP.hprof
// 3. 把堆内存文件拉取到本地
adb pull /data/local/tmp/SOMEDUMP.hprof <本地路径>
// 4. 通过redex 提供的 python脚本解析堆内存,生成类加载顺序列表
// 注意,该命令我在执行时,出现空对象错误,仔细读了官方文档后,了解有存在堆内存异常情况,所以需要加一个参数进行忽略
python3 redex/tools/hprof/dump_classes_from_hprof.py --hprof SOMEDUMP.hprof > app_list_of_classes.txt
// 所以,我本人使用的是如下命令,大家可以根据情况自行调整
python redex/tools/hprof/dump_classes_from_hprof.py --allow_missing_ids --hprof SOMEDUMP.hprof > app_list_of_classes.txt
// 5. 执行 redex 逻辑,生成新的apk包
// 官方提供的命令是
python3 redex.py -c default.config --android-sdk-path path/to/android/sdk path/to/your.apk -o path/to/output.apk
// 以上命令我这边出现报错,说缺少Proguard混淆规则,所以我使用了如下命令才解决
python3 redex.py -c ./config/default.config --produard-config path/proguard-project.txt --android-sdk-path path/Android/sdk path/your.apk -o output.apk
// 6. 最后对输出的 output.apk 包重新签名即可
- 最后进行优化效果对比
- 安装未启用 interdex pass 的 apk
// 获取应用 pid, 查看内存的使用情况,这里需要对比 .dex mmap 行
adb shell ps | grep <应用包名>
adb shell dumpsys meminfo <应用 Pid>
- 请注意你的应用程序使用了多少内存 .dex mmap 行
- 执行上述所有步骤并在启用 Interdex Pass 并使用你生成的启动class加载顺序表的情况下重新运行 redex
- 安装启用 interdex 的 apk
- 启动应用程序并重复该步骤以获取 meminfo
- 注意总内存使用量,尤其是 .dex mmap
我的前后对比如下,第一幅图(pid为19125)是未启用优化的,第二幅图(pid为21098)则是优化过的。
从内存使用情况来看,优化效果还是比较明显的,我也计算了优化后比优化前,在启动速度上大约提升了150 ~ 200ms,这在低端机上,CPU和高速缓存不太多不太好的设备上,优化效果就更为明显,差距可以达到400 ~ 500ms,但在高端机上,差距就非常小了。因为高端机上高速缓存是很多的,相对于低端机而言,命中率更高,不会频繁的从主存里读取数据。
当然,Redex的优化项很多,我这里只研究了dex类文件重排,这么看来,它算是相对比较容易落地的优化方案了,这个案例主要还是让我们知道优化的思考方法。我们从了解软件的执行过程和内存模型,再到对这些过程和模型进行分析,从而得出优化方案,而且这些思考不仅仅可以使用在Android开发,底层原理一样,逻辑思维相通,可以使用到PC端,前端等等各种情况,这个才是我们需要重点学习的,优化是成体系的,而不是从网络上搜出一堆潦草的,未经过任何思考的优化方案。
4.2 提升任务调度优先级
在操作系统中有一个任务调度器负责根据任务的优先级、执行时间、资源需求等因素,决定哪个任务可以获得CPU时间片。既然是在操作系统层面的优化,那就离不开任务调度,接下来我们针对这一个方法论来看看如何提升核心线程的优先级。
我们先了解一下 Linux 中的优先级原理,Linux 中的进程分为实时进程和普通进程这两类。实时进程一般通过 RTPRI(RealTimeRriority) 值来描述优先级,取值范围是 0 到 99。普通进程一般使用 Nice 值来描述进程的优先级,取值范围是 -20 到 19。但是为了架构设计上的统一, Linux 系统会将 Nice 对齐成 Prio 值,即 Nice 取 -20 时,该进程的 Prio 值为 0 ,此时它的优先级依然比任何一个实时进程的优先级都要低。通过查看源码得知,线程是一个精简化的进程,因此上述优先级规则也适用于线程。
我们可以通过执行命令 adb shell top -H -n 1 -p <应用PID> , 来查看该应用进程的Nice值和Prio值,在输出界面中,PR列表示线程的Prio优先级值,NI列表示线程的Nice优先级值,具体如下图所示:
从上面数据可以看到,我的App进程PID为4843,所以主线程的Prio值和Nice值分别为10和 -10。 图中还标识了一个RenderThread线程,它是渲染线程。我们需要调整优先级的线程就是主线程和渲染线程。 因为这两个线程对任何应用来说都非常重要。从Android5 开始,主线程只负责布局文件的 measure 和 layout 工作,渲染的工作放到了渲染线程,这两个线程配合工作,才让我们应用的界面能正常显示出来。所以通过提升这两个线程的优先级,便能让这两个线程获得更多的 CPU 时间,页面显示的速度自然也就更快了。
在 Android 中只有部分底层核心进程才是实时进程,如 SurfaceFlinger、Audio 等进程,大部分的进程都是普通进程,我们没法将普通进程调整成实时进程,也没法将实时进程调整成普通进程,只有操作系统有这个权限。但有一个例外,在 Root 手机中,将 /system 目录下的 build.prop 文件中的 sys.use_fifo_ui 字段修改成 1 ,就能将应用的主线程和渲染线程调整成实时进程,不过这需要 Root 设备才能操作,正常设备这个值都是 0,这个方案不具备通用性。因为App应用中的所有线程都属于普通进程的级别,所以针对线程优先级这一点,我们唯一能操作的就是修改线程的 Nice 值了,然而我们有两种方式来调整线程的 Nice 值。
调整线程优先级的方式
- Process.setThreadPriority(int priority) / Process.setThreadPriority(int pid,int priority);
- Thread.setPriority(int priority)。
第一种是Android 系统中提供的 API 接口。入参 pid 就是线程 id,也可以不传,会默认为当前线程,入参 priority 可以传 -20 到 19 之间的任何一个值,但是建议直接使用 Android 提供的 Priority 定义常量,这样我们的代码具有更高的可读性,如果直接传我们自定义的数字进去,不利于代码的理解。
| 系统常量 | nice值 | 使用场景 |
|---|---|---|
| Process.THREAD_PRIORITY_DEFAULT | 0 | 默认优先级 |
| Process.THREAD_PRIORITY_LOWEST | 19 | 最低优先级 |
| Process.THREAD_PRIORITY_BACKGROUND | 10 | 后台线程建议优先级 |
| Process.THREAD_PRIORITY_LESS_FAVORABLE | 1 | 比默认略低 |
| Process.THREAD_PRIORITY_MORE_FAVORABLE | -1 | 比默认略高 |
| Process.THREAD_PRIORITY_FOREGROUND | -2 | 前台线程优先级 |
| Process.THREAD_PRIORITY_DISPLAY | -4 | 显示线程建议优先级 |
| Process.THREAD_PRIORITY_URGENT_DISPLAY | -8 | 显示线程的最高级别 |
| Process.THREAD_PRIORITY_AUDIO | -16 | 音频线程建议优先级 |
| Process.THREAD_PRIORITY_URGENT_AUDIO | -19 | 音频线程最高优先级 |
在不进行调整前,我们主线程和渲染线程的默认 Nice 值为 -10,这其实已经算比较高优先级了,音频线程建议是最高级别优先级,因为如果音频线程优先级太低,就会出现音频播放卡顿的情况。但不同的设备和Android平台的默认配置可能不同,在较低版本的设备上(例如Android 6)主线程默认的 Nice值是0,渲染线程是-4。
第二种是 Java 提供的 API 接口,能设置的优先级较少,不太灵活,并且因为系统的一个时序问题 Bug,在设置子线程的优先级时,可能因为子线程没创建成功而设置成了主线程的,会导致优先级设置异常,所以这里建议使用第一种方式来设置线程的优先级,避免使用第二种方式。
找到需要调整优先级的线程
在前面我们已经说过,我们需要调整优先级的线程就是主线程和渲染线程。因为这两个线程是相互配合的,同时进行调整才能达到最优效果。 那我们怎么去调整呢?
主线程的优先级调整,我们直接在 Application 的 attach 生命周期中用Process.setThreadPriority(-19),将主线程设置为最高优先级即可。
至于 RenderThread 线程的调整,
我们需要先知道渲染线程的id,然后调用 Process.setThreadPriority 进行设置就可以了。那我们怎么去找到渲染线程的线程id呢?下面我们就来一起看下。
应用中线程的信息记录在 /proc/pid/task 的文件中,可以看到 task 文件中记录了当前应用的所有线程。以 2273 这个进程的数据为例,数据如下:

我们接着查看该目录里线程的 stat 节点,就能具体查看到线程的详细信息,如 Name、pid 等等。2273 进程的主线程 id 就是 2273,它的stat第一个参数是 pid,第二个参数是线程名字 (下图中的.winXXXXX.m 就是主线程名字),具体如下:

所以我们只需要遍历 task 这个文件,查找名称为 RenderThread 的线程,就能找到渲染线程的pid了,具体代码实现如下:
public static int getRenderThreadTid() {
File taskParent = new File("/proc/" + Process.myPid() + "/task/");
if (taskParent.isDirectory()) {
File[] taskFiles = taskParent.listFiles();
if (taskFiles != null) {
for (File taskFile : taskFiles) {
//读线程名
BufferedReader br = null;
String cpuRate = "";
try {
br = new BufferedReader(new FileReader(taskFile.getPath() + "/stat"), 100);
cpuRate = br.readLine();
br.close();
} catch (Throwable throwable) {}
if (!cpuRate.isEmpty()) {
String param[] = cpuRate.split(" ");
if (param.length < 2) {
continue;
}
String threadName = param[1];
//找到name为RenderThread的线程,则返回第0个数据就是 tid
if (threadName.equals("(RenderThread)")) {
return Integer.parseInt(param[0]);
}
}
}
}
}
return -1;
}
当我们拿到渲染线程的 pid 后,同样调用 Process.setThreadPriority(pid,-19) 将渲染线程设置成最高优先级即可。
当然,我们要提高的优先级线程并非只有这两个,我们可以根据业务需要,来提高核心线程的优先级,同时降低其他非核心线程的优先级,该操作可以在线程池中通过线程工厂来统一调整。提高核心线程优先级,降低非核心线程优先级,两者配合使用,才能更高效地提升应用的速度。
好了,当然,由于知识有限,优化方案也不是很全面,可能还有其他更好的优化方法,欢迎大家一起交流,至此CPU优化已经全部介绍完了,接下来我要开始 总(zhuang)结(bi)了。
二、小结
这篇文章从硬件到操作系统再到软件层,自底向上系统的介绍了如何去做性能优化,其实不仅仅是CPU优化可以这样去思考解决,还有内存优化、包体积优化、网络优化等等方面都可以采用这套逻辑。回归性能优化的本质是合理且充分使用硬件资源,让程序的表现更好 ,“充分”就是将硬件的资源充分发挥出来。 但要注意,充分不一定是合理的。比如我们一下开启了几百个线程,CPU 被充分发挥了,却这并不合理,因为此时主线程无法获得足够的 CPU 资源,那合理就是所发挥出来的硬件资源能给程序表现带来正向的作用。然而性能优化也并不容易,想要做好性能优化,需要庞大的知识储备。
硬件层面:我们需要对CPU的工作方式有了解,CPU的单核和多核等结构、寄存器、高速缓存、主存的设计等等。
系统层面:对操作系统有一定的了解也是必要的,这里包括但不仅限于进程的管理和调度、内存管理、虚拟内存等等,Andorid系统还有虚拟机、核心服务(ams、wms等)以及核心流程(启动、Activity、包安装)等等。
软件层面:这要求我们熟悉自己开发的App,了解App使用缓存的情况,每个线程是干嘛的,使用都合理吗?是否因为如bitmap等不合理的使用或者不良的编程习惯而占用大量内存等等情况。
其他方面:除上面三个基本的之外,我们可能还需要掌握更多知识,例如:汇编、编译器、逆向、各种编程语言,比如用 C++ 写代码就比用 Java 写代码运行更快,我们可以通过将一些业务替换成 C++ 来提高性能,用 C 或者 C++ 编写模块做JNI调用等。
最后我把这一篇的知识,做一个知识框架总结。
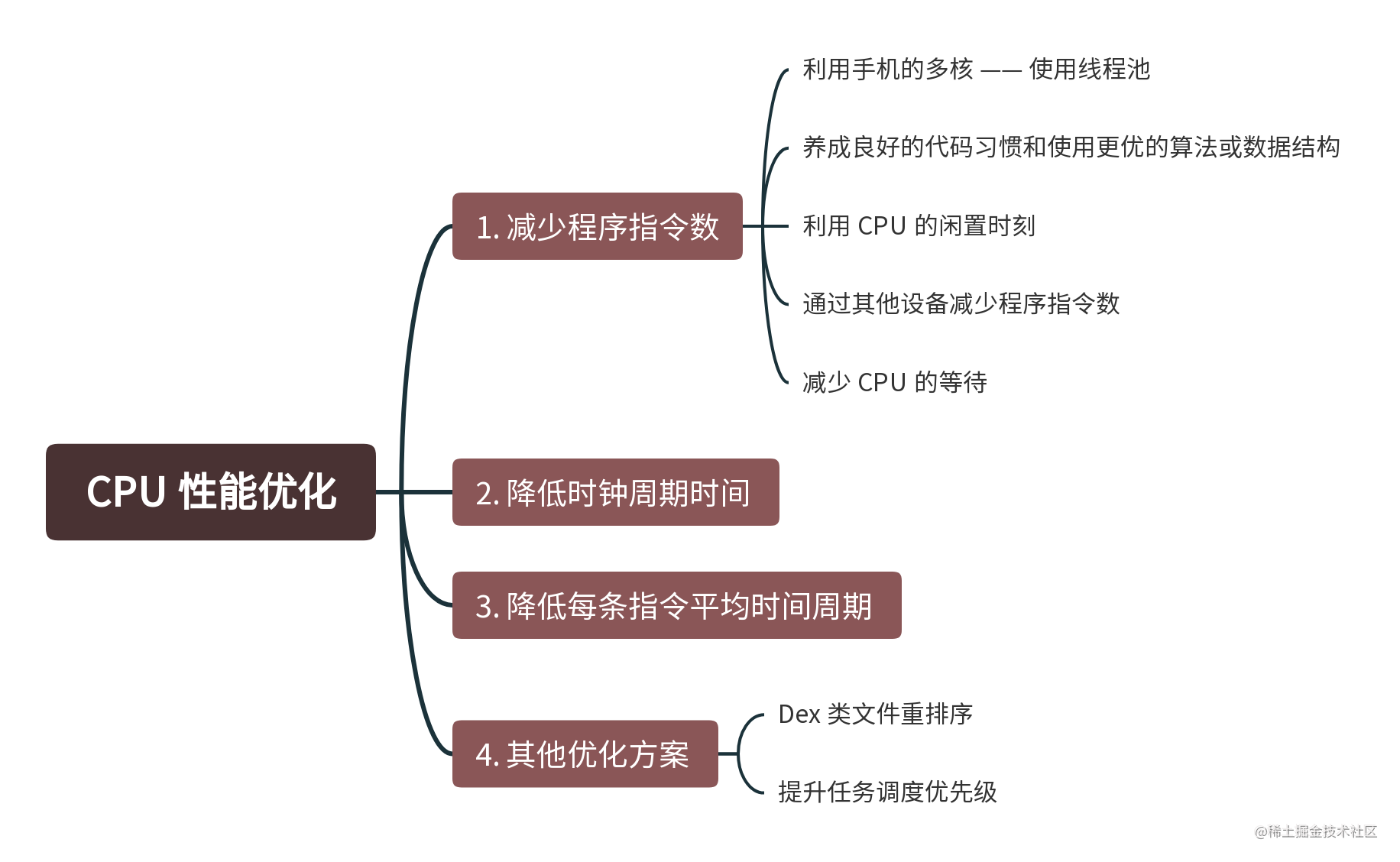














 108
108











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









