







JDK提供的线程池实现
这里为什么要强调JDK提供呢? 新手要明白一个点 线程池它是一种线程复用的设计思想,他并不是java的一个专用组件。
你可以用其他语言来实现线程池,也可以不用java jdk提供的线程池构建。(比如你功力比较深 你直接原生代码手写一个线程池也是可以的)
这里我们就主要介绍JDK为我们提供的线程构建接口:
ThreadPoolExecutor
我们找一个最全的参数的构造方法
这里面的参数含义很重要 大家一定要理解
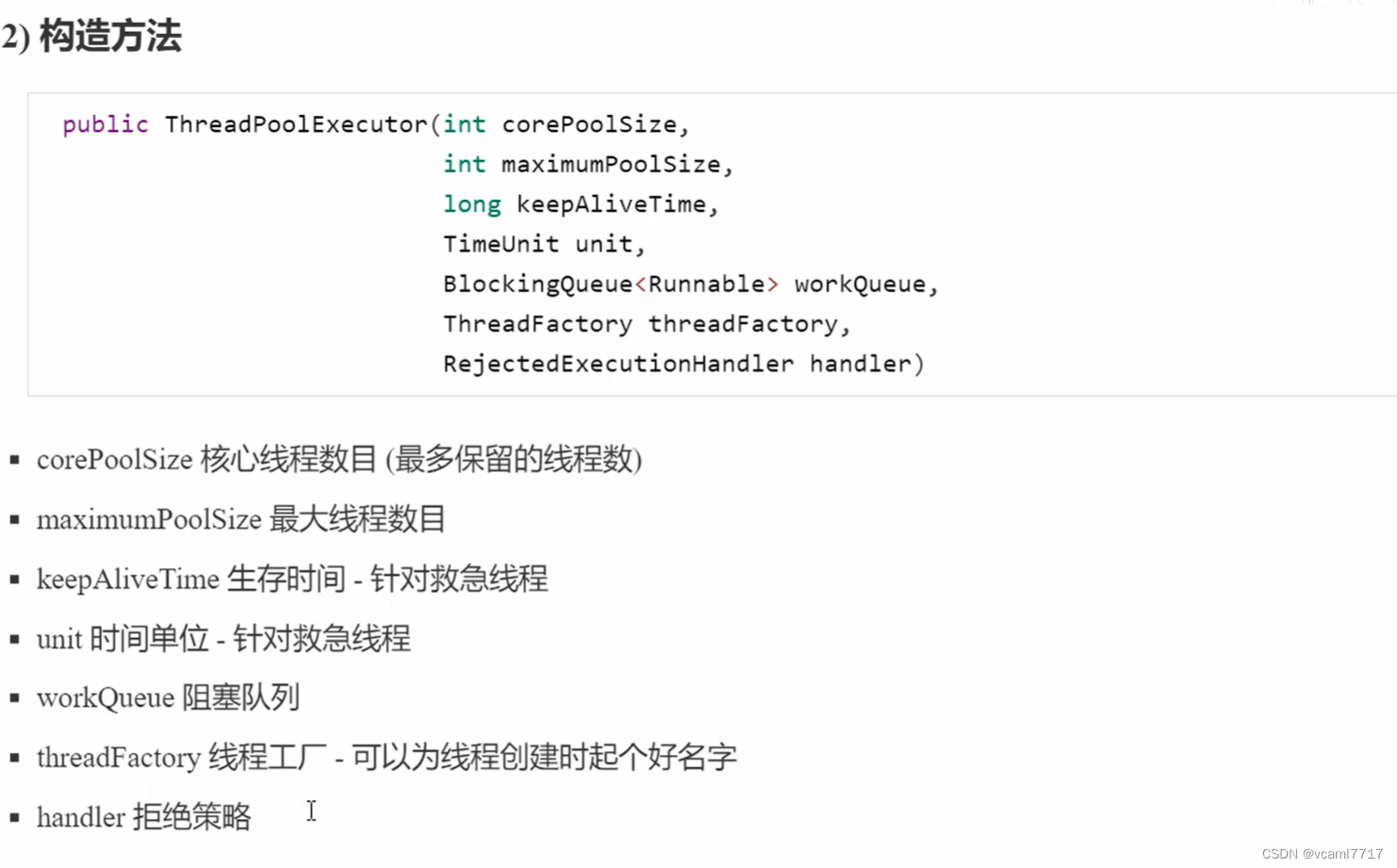
jdk送你的现成的线程池
这时候新手会自然的想到
这么多参数老子一个一个配岂不是累死?
有没有现成儿的 以及配好的 直接可以拿来用的??
答案是有的!
JDK生怕你麻烦
所以它提供了几种现成的线程池实现 这些实现方法在内部是静态的 意味中你直接可以类名.*** 来创建:
/**
* 一些常见的jdk提供的线程池
* */
ExecutorService es1 = Executors.newFixedThreadPool(3);
ExecutorService es2 = Executors.newCachedThreadPool();
ExecutorService es3 = Executors.newScheduledThreadPool(3);
Executors.newFixedThreadPool(3):这个方法创建了一个固定大小的线程池,其中包含3个线程。这意味着线程池中始终保持着3个线程的数量,无论是否有任务需要执行。线程池会重用这些线程来处理提交的任务,避免了频繁地创建和销毁线程对象。
Executors.newCachedThreadPool():这个方法创建了一个缓存线程池,它根据需要自动调整线程数量。如果有可用的空闲线程,则会重用它们来执行新任务。如果没有可用的线程,将创建一个新的线程。这样可以根据任务的数量自动调整线程池的大小,避免了无限制地创建大量线程的问题。
Executors.newScheduledThreadPool(3):这个方法创建了一个定时线程池,它可以安排延迟执行或定期执行的任务。该线程池具有固定大小,包含3个线程。它可以用于需要按计划执行任务的场景,例如定时任务、周期性任务等。线程池会重复使用这些线程来执行计划任务,而不是每次都创建新的线程。
自定义线程池
既然现成的都有了 为什么还要自定义???
这个问题对大佬们来说 很简单 但是对第一次接触多线程的新手来说会困惑。
我们还是坚持 《照顾新手》 原则
自定义线程池大小的需求可能源于特定的应用场景和性能考虑。尽管Java提供了一些现成的线程池实现,但在某些情况下,自定义线程池大小可能更适合满足应用程序的需求。
自定义的线程池我们可以自由的设计 每一个参数 按我们想要的 实现定制化。
大家平时应该打过 LOL CSGO 星际争霸 之类的。
我们打游戏的时候 经常干一件事情 就是改键 把一些系统默认的按键改成我们自己顺手的按键 (有些LOL 的adc 喜欢把走和a改成走a一体化)
线程池也是同样的道理 它给你现成的 但是也允许你自定义。
/**
* 自定义线程池
* */
ExecutorService es4 =new ThreadPoolExecutor(
5,//核心线程数
6,//最大线程数
30,//存活时间
TimeUnit.SECONDS,
new ArrayBlockingQueue<>(3));
}
这里就创建了一个自定义线程池了,它本质上各种功能和上面那个三个没啥区别
这里核心线程数 最大线程数 存活时间和单位 是基础的。
然是是阻塞队列的选择:
无界队列(无限容量队列):无界队列在没有明确的容量限制的情况下存储任务。它可以容纳任意数量的任务,并且不会拒绝任何任务的提交。在使用无界队列时,如果线程池的线程数已达到核心线程数,并且所有线程都在执行任务,则新提交的任务会被放入无界队列中等待执行。常见的无界队列实现是LinkedBlockingQueue,它使用链表来实现队列,没有固定的容量限制。
有界队列(有限容量队列):有界队列有一个固定的容量限制,只能存储有限数量的任务。当线程池的线程数已达到核心线程数,并且所有线程都在执行任务时,如果有新的任务提交,如果队列未满,则新任务会被放入队列中等待执行;如果队列已满,则根据线程池的拒绝策略来处理任务。常见的有界队列实现是ArrayBlockingQueue,它使用数组来实现队列,具有固定的容量。
然后还有拒绝策略:
拒绝策略(rejectedExecutionHandler):当线程池无法接受新的任务时,采取的处理策略。常见的策略包括抛出异常(AbortPolicy)、丢弃任务并抛出异常(DiscardPolicy)、丢弃队列中最早的任务并尝试重新提交(DiscardOldestPolicy)等。
常用方法
ok 我们现在 线程池的创建算是完成了。
我们得到了一个 ExecutorService es 线程池对象。
它有哪些常用方法呢?
execute() 最简单 最直接 直接交给线程池运行
submit(Runnable task):提交一个 Runnable 任务给线程池执行,并返回一个 Future 对象,用于获取任务的执行结果或取消任务的执行。
submit(Callable task):提交一个 Callable 任务给线程池执行,并返回一个 Future 对象,用于获取任务的执行结果或取消任务的执行。Callable 任务可以返回一个结果对象,与 Runnable 不同。
shutdown():优雅地关闭线程池,停止接受新的任务,并尝试完成所有已提交的任务。已提交但未执行的任务可以继续执行,已提交且正在执行的任务可以选择等待完成或被中断。
shutdownNow():强制关闭线程池,尝试停止所有正在执行的任务,并返回等待执行的任务列表。该方法会发送中断信号给所有线程。
awaitTermination(long timeout, TimeUnit unit):阻塞当前线程,等待线程池的所有任务完成,或者超过指定的超时时间。返回 true 表示线程池已经完全终止,返回 false 表示等待超时。
isShutdown():判断线程池是否已经调用了 shutdown() 方法。
isTerminated():判断线程池是否已经完全终止,即所有任务都已完成且线程池已关闭。
invokeAny(Collection<? extends Callable> tasks):提交一组 Callable 任务给线程池执行,并返回其中一个任务的执行结果,无论是否成功执行。如果其中一个任务成功返回结果,其他任务会被取消。
invokeAll(Collection<? extends Callable> tasks):提交一组 Callable 任务给线程池执行,并返回一个包含所有任务执行结果的 List<Future> 对象。调用该方法会阻塞,直到所有任务完成。
使用线程池 多个线程打印当前时间戳
public class CustomThreadPool {
/**
* 这里我们创建自定义线程池,
* jdk提供的现成的现场池也是由这个接口实现。但是下面的参数是固定的。
* 下面自定义的方式 参数我们可以自己定
* */
private ExecutorService executorService;
public CustomThreadPool(){
executorService = new ThreadPoolExecutor(
5,
6,
30,
TimeUnit.SECONDS,
new ArrayBlockingQueue<>(3));
}
public void execute(Runnable task){
executorService.execute(task);
}
}
定义一个task 也就是线程要具体执行什么任务
public class PrintTimeTask implements Runnable{
@Override
public void run() {
System.out.println("当前线程:"+Thread.currentThread().getName()+"-打印时间:"+System.currentTimeMillis());
}
}
Test 往里面丢就行了
PrintTimeTask timeTask = new PrintTimeTask();
CustomThreadPool customThreadPool = new CustomThreadPool();
for (int i = 0; i < 4; i++) {
customThreadPool.execute(timeTask);
}
当前线程:pool-1-thread-2-打印时间:1684984731360
当前线程:pool-1-thread-1-打印时间:1684984731360
当前线程:pool-1-thread-4-打印时间:1684984731360
当前线程:pool-1-thread-3-打印时间:1684984731360
这里有一个非常重要的概念 新手要理解:
线程池里的线程 默认全部是非守护线程!
就是说 就算主程序结束了 只要线程池里面的线程还没结束 主程序会等待他们结束 而不会强制关闭线程池里面的线程















 104
104











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









