







前言
本文大约4000字,阅读大约时间10分钟。
可以一口气读完入门在爬虫er手中如何使用AST去解混淆。
正文
抽象语法树(Abstract Syntax Tree)通常被称为AST语法树,指的是源代码语法所对应的树状结构。也就是一种将源代码通过构建语法树,将源代码的语句映射到树上的每一个节点。
在爬虫er手中,通常将JavaScript源代码解析为语法树,操作节点的增删改查来实现解混淆的目的。
需要用到的技术:
- node.js
- node.js的第三方库包Babel下的部分工具(@babel/parser,@babel/traverse,@babel/types,@babel/generator)
安装
1、下载node.js msi安装包一路确认就好了,最后在命令行下输入 node -v 验证是否安装成功
2、使用npm安装Babel库
// 安装命令
// 只需要babel中以下的工具,不建议使用npm install @babel/core安装,会造成编辑器中只能补全不全。
npm install @babel/parser
npm install @babel/traverse
npm install @babel/types
npm install @babel/generator
// 查看版本
npm ls [package_name]
必须的知识
1、node.js中文件读写
node中提供文件系统模块(fs)进行文件读写,提供异步(readFile)和同步(readFileSync)的方法读取文件,相应的也提供writeFile、writeFileSync写入文件。
基本使用如下:
// 读取input.js文件base64编码后写入output.js
// node.js 在16.00之后也有atob,btoa了
const fs = require('fs')
fs.readFile('input.txt', "utf8", (err, input_js_code) => {
console.log(input_js_code);
let output_code = btoa(encodeURIComponent(input_js_code));
console.log(output_code);
fs.writeFileSync('output.txt', output_code, {encoding: "utf-8"})
});
// 输出:
// 又是一个爬虫er
// JUU1JThGJTg4JUU2JTk4JUFGJUU0JUI4JTgwJUU0JUI4JUFBJUU3JTg4JUFDJUU4JTk5JUFCZXI=
2、babel中的一些工具的基本使用
需要用到babel中的工具有:@babel/parser、@babel/traverse、@babel/generator、@babel/types。其中@babel/parser负责接受源码进行词法分析、语法分析最终生成AST;@babel/traverse负责对AST进行深度优先的遍历;@babel/generator则和@babel/parser相反,负责将AST转化为AST源码;@babel/types用于判断节点类型、生成新节点。
- parser.parse将JavaScript源代码解析为AST;generator(ast).code将AST转化为JavaScript源代码。
- traverse遍历AST节点,当遍历到节点名与visitor对象方法名一致时调用该visitor方法。
- types构造新节点、判断节点类型
- path,remove()删除节点path.insertBefore(node)
基本使用如下:
const fs = require('fs')
const parser = require("@babel/parser");
const traverse = require("@babel/traverse").default;
const b_type = require("@babel/types");
const generator = require("@babel/generator").default;
fs.readFile('resources/input.js', "utf8", (err, input_js_code) => {
// 将JavaScript源代码转化为AST
let ast = parser.parse(input_js_code);
//对AST各个节点进行遍历,当遍历到visitor内声明的节点时,进入并执行。
traverse(ast, visitor)
// 将AST转化为JavaScript代码,jsescOption选项去除16进制和Unicode
let output_code = generator(ast, {minified: true, jsescOption: {minimal: true}}).code
fs.writeFileSync('resources/output.js', output_code, {encoding: "utf-8"})
});
function funToStr(path) {
// @babel/types常用api
// let new_node = b_type.stringValue()
// let new_node = b_type.numberValue()
// let new_node = b_type.valueToNode()
// 替换节点
// path.replaceWith(string_node)
// path.replaceWithMultiple(string_node)
// 删除节点
// path.remove()
// 在这之前、之后插入节点
// path.insertBefore()
// path.insertAfter()
// 获取兄弟节点
// path.getAllPrevSiblings()
// ...
}
const visitor = {
// 调用函数节点
CallExpression: {enter: [funToStr]},
// ...
}
3、利用astexplorer和AST节点速查手册快速编写反混淆代码。
astexplorer网址:https://astexplorer.net/
AST节点速查手册网址:https://github.com/yacan8/blog/blob/master/posts/JavaScript%E6%8A%BD%E8%B1%A1%E8%AF%AD%E6%B3%95%E6%A0%91AST.md
使用AST进行解混淆的一般步骤为
- 观察JavaScript源代码,分析那些部分需要替换、删除
- 将源代码放入到astexplorer,观察需要处理的JavaScript片段特征。在astexplorer中点击左侧源代码,右侧AST即会跳转到对于节点。
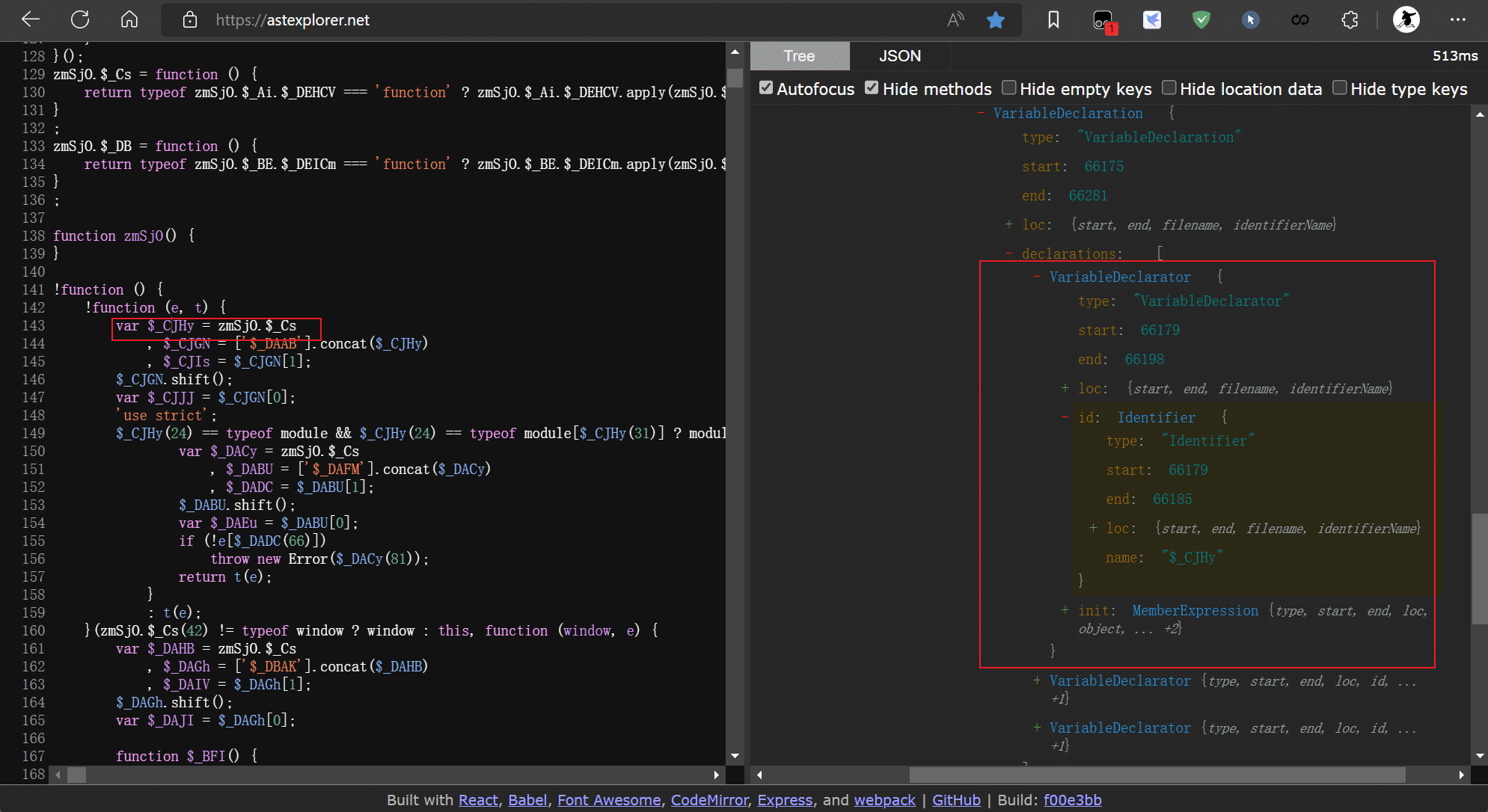
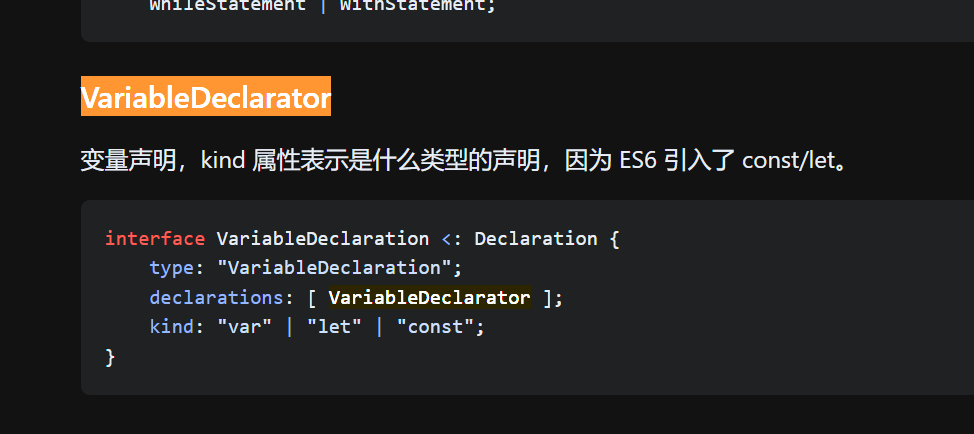
- 结合AST节点速查手册在visitor中快速编写规则处理需要修改的节点。
4、一些能提升开发效率的工具
- babel中文文档:https://www.babeljs.cn/docs
- ast explorer助手(油猴插件):https://github.com/CC11001100/ast-explorer-helper
基本操作
了解完基础知识我们就可以进行一些简单的基本操作了
1、简单还原常量与标识符的混淆
在本小段中只讨论了常见的对字符常量名进行Unicode编码、数值常量进制转化混淆的还原。其他对字符常量btoa、ob混淆,对数值常量替换为表达式运算结果的情况不做讨论。
以下代码也可以作为我们利用AST解混淆的基本模板,本文所有代码都是基于此模板。
const fs = require('fs')
const parser = require("@babel/parser");
const traverse = require("@babel/traverse").default;
const b_type = require("@babel/types");
const generator = require("@babel/generator").default;
// 模板
fs.readFile('resources/Unicode.js', "utf8", (err, input_js_code) => {
// 将JavaScript源代码转化为AST
let ast = parser.parse(input_js_code);
// 对AST各个节点进行遍历,当遍历到visitor内声明的节点时,进入并执行。
traverse(ast, visitor)
// 将AST转化为JavaScript代码,jsescOption选项还原16进制和Unicode
let output_code = generator(ast, {minified: true, jsescOption: {minimal: true}}).code
fs.writeFileSync('resources/deUnicode.js', output_code, {encoding: "utf-8"})
});
const visitor = {}
还原前后对照

2、简单还原ob混淆
对JavaScript源码使用基本的ob混淆后在文件开头会见到一个大数组,之后可能会有一个自执行函数对开头的大数组进行位移操作,在这后面还会提供一个解密函数返回被混淆的字符串。
还原这种类型的混淆我们首先需要将这个大数组、自执行的位移函数和解密函数提取出来,部分开发同学还会将解密函数在函数内赋值给一个新的局部变量在一定程度上干扰ob混淆被还原。

-
提出数组、自执行的位移函数和解密函数
为了提高代码的可读性,一般情况下我们将数组、自执行的位移函数和解密函数提出到一个单独的文件,使用exports导出解密函数提供给解混淆使用。// 一般情况下只有一个解密函数 exports.decryptStr = _0x36a8; exports.decryptStrFnName = '_0x36a8';
-
编写规则处理代码
以下以jsjiami的v5基础版本做实例,在这一小段只简单还原了OB混淆段。
const fs = require('fs')
const parser = require("@babel/parser");
const traverse = require("@babel/traverse").default;
const b_type = require("@babel/types");
const generator = require("@babel/generator").default;
const {decryptStr, decryptStrFnName} = require("./tools_v5")
// 模板
fs.readFile('resources/jsjiami_v5.js', "utf8", (err, input_js_code) => {
// 将JavaScript源代码转化为AST
let ast = parser.parse(input_js_code);
// 对AST各个节点进行遍历,当遍历到visitor内声明的节点时,进入并执行。
traverse(ast, visitor)
// 将AST转化为JavaScript代码,jsescOption选项还原16进制和Unicode
let output_code = generator(ast, {minified: true, jsescOption: {minimal: true}}).code
fs.writeFileSync('resources/dejsjiami_v5.js', output_code, {encoding: "utf-8"})
});
function funToStr(path) {
let {callee, arguments} = path.node
if (callee.name === decryptStrFnName) {
let replace_value = decryptStr(arguments[0].value, arguments[1].value)
let replace_node = b_type.stringLiteral(replace_value)
path.replaceWith(replace_node)
}
}
const visitor = {
CallExpression: {
enter: [funToStr]
}
}
还原前后对照:

3、简单还原平坦化
除去对变量的混淆,常见的还有代码执行流程的混淆,通常使用while-switch,for-switch来将正常的执行流程打乱,然后通过swtich case块分发代码块并控制执行顺序,部分混淆还会塞入假代码块。对于这一类的混淆,在while-switch中我们首先需要确定分发器,之后通过分发器的执行顺序抽取出对应case内的代码块存入数组使用replaceWithMultiple替换整个节点;在for-switch中和while-switch不同的是分发器的生成,while-switch会在代码进入while前就生成分发器确定代码执行顺序且while一般为死循环在执行完分发器分发的最后一个case后跳出;for-switch则是在case内确定下一个case的执行,当分发器的值和for循环中的跳出吻合时结束。
while-switch平坦化还原:
const fs = require('fs')
const parser = require("@babel/parser");
const traverse = require("@babel/traverse").default;
const b_type = require("@babel/types");
const generator = require("@babel/generator").default;
fs.readFile('resources/switch_case.js', "utf8", (err, input_js_code) => {
// 将JavaScript源代码转化为AST
let ast = parser.parse(input_js_code);
//对AST各个节点进行遍历,当遍历到visitor内声明的节点时,进入并执行。
traverse(ast, visitor);
// 将AST转化为JavaScript代码,jsescOption选项去除16进制和Unicode
let output_code = generator(ast, {minified: false, jsescOption: {minimal: true}}).code;
fs.writeFileSync('resources/de_switch_case.js', output_code, {encoding: "utf-8"})
});
function de_planarization(path) {
let {body, test} = path.node
// 判断while内是否为!![]
if (test.type !== "UnaryExpression" || test.operator !== "!"
|| test.argument.type !== "UnaryExpression" || test.argument.operator !== "!"
|| test.argument.argument.type !== "ArrayExpression" || test.argument.argument.elements.length !== 0
) return;
// 判断while内代码块是否为switch case
if (body.body.length === 0
|| body.body[0].type !== 'SwitchStatement'
|| body.body[1].type !== 'BreakStatement'
) return;
// 取switch内分发器名字
let discriminant = body.body[0].discriminant
let dispatcher_name = discriminant.object.name
// 取while循环上面的兄弟节点,用于获取case执行步骤
let PrevSiblings = path.getAllPrevSiblings();
// case执行步骤
let replace_node = []
//迭代兄弟节点
PrevSiblings.forEach(Sibling => {
// 判断是否为分发器的赋值语句
if (Sibling.node.type === "VariableDeclaration" && Sibling.node.declarations[0].id.name === dispatcher_name) {
let {callee, arguments} = Sibling.node.declarations[0].init
// 分发器字符串切割符号
let split_str = arguments[0].value
// 分发器字符串的值
let dispatcher_value = callee.object.value
// 分发器处理函数,一般看源码就可以确认了,split_str、dispatcher_func可以不获取
let dispatcher_func = callee.property.value
// case代码块执行步骤
let real_steps = dispatcher_value[dispatcher_func](split_str)
// let real_steps = dispatcher_value.split('|')
let switch_node = body.body[0]
real_steps.forEach(step => {
// 获取case内代码块
let consequent = switch_node.cases[step].consequent
// 移出continue代码
if (b_type.isContinueStatement(consequent[consequent.length - 1])) {
consequent.pop();
}
replace_node = replace_node.concat(consequent);
})
}
//删除前面的兄弟节点
Sibling.remove();
})
//替换整个while节点
path.replaceWithMultiple(replace_node);
}
const visitor = {
WhileStatement: {
enter: [de_planarization]
}
}
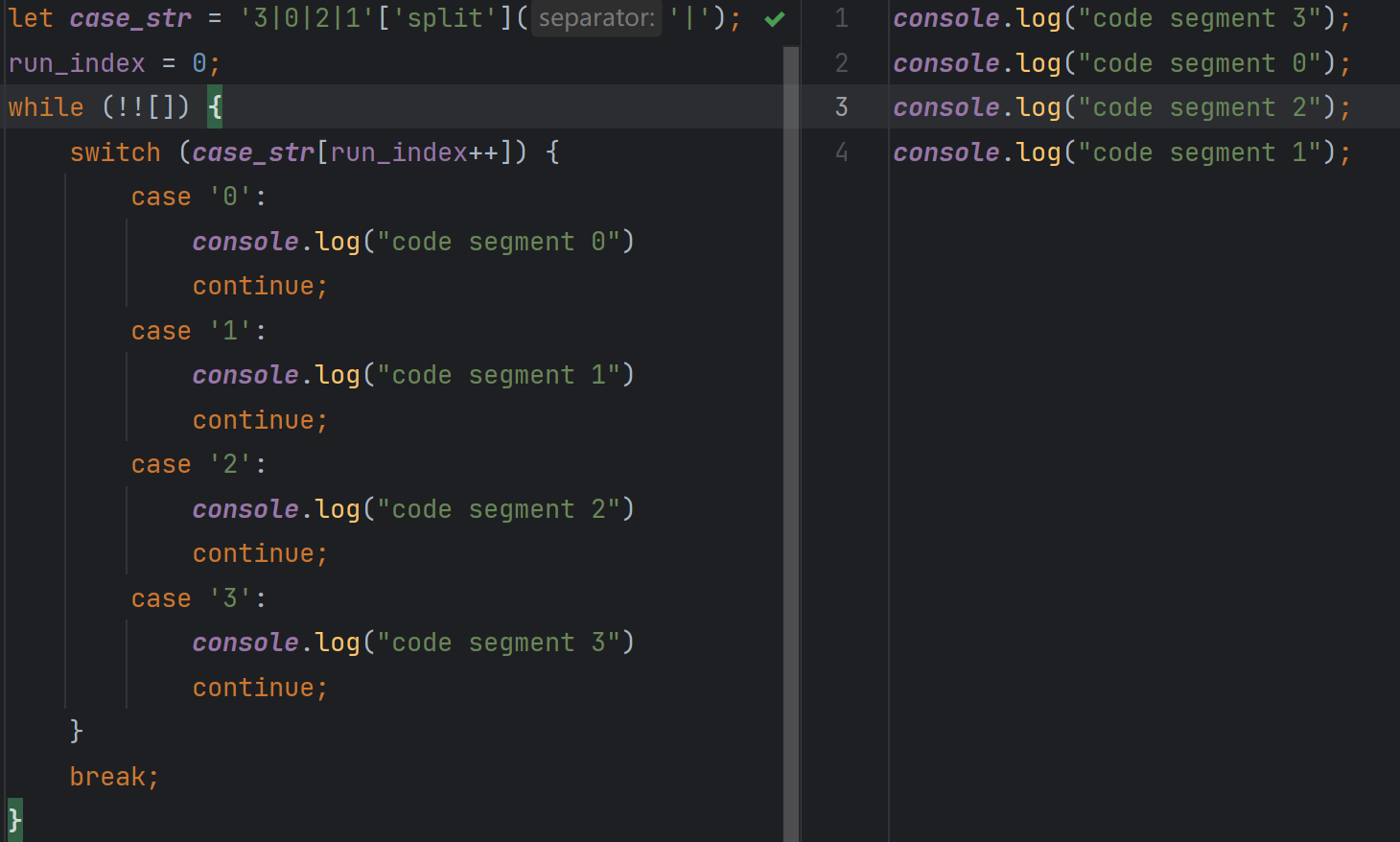
还原前后对比:
for-switch平坦化还原:
const fs = require('fs')
const parser = require("@babel/parser");
const traverse = require("@babel/traverse").default;
const b_type = require("@babel/types");
const generator = require("@babel/generator").default;
fs.readFile('resources/for_switch_case.js', "utf8", (err, input_js_code) => {
// 将JavaScript源代码转化为AST
let ast = parser.parse(input_js_code);
//对AST各个节点进行遍历,当遍历到visitor内声明的节点时,进入并执行。
traverse(ast, visitor)
// 将AST转化为JavaScript代码,jsescOption选项去除16进制和Unicode
let output_code = generator(ast, {minified: false, jsescOption: {minimal: true}}).code
fs.writeFileSync('resources/de_for_switch_case.js', output_code, {encoding: "utf-8"})
});
function de_planarization(path) {
let {init, test, update, body} = path.node
// 判断for循环跳出特征
if (test.operator !== "!==") return;
// 起始代码块索引
let start_index = init.declarations[0].init.value
// 结束索引
let end_index = test.right.value
// 索引在源代码中的名字
let dispatcher_name = test.left.name;
// 替换节点
let replace_node = []
body.body.forEach(node => {
if (node.type === "SwitchStatement") {
// switch case分发器特征是否满足条件
if (node.discriminant.name !== dispatcher_name) return;
// 按源代码顺序迭代case
for (let i = start_index; i !== end_index;) {
let SwitchCase = node.cases[i]
let need_save = []
SwitchCase.consequent.forEach(Statement => {
// 获取下一个执行的代码块index
if (Statement.type !== 'ExpressionStatement'
|| Statement.expression.type !== "AssignmentExpression"
|| Statement.expression.left.name !== dispatcher_name
) {
// 将其与代码保存
need_save.push(SwitchCase.consequent.indexOf(Statement))
return
}
// 下一个执行的代码块
i = Statement.expression.right.value
})
need_save.forEach(index => {
let case_code = SwitchCase.consequent[index]
// 删除continue
if (b_type.isContinueStatement(case_code)) return;
replace_node = replace_node.concat(case_code);
})
}
path.replaceWithMultiple(replace_node)
}
})
}
const visitor = {
ForStatement: {
enter: [de_planarization]
}
}
还原前后代码对比:
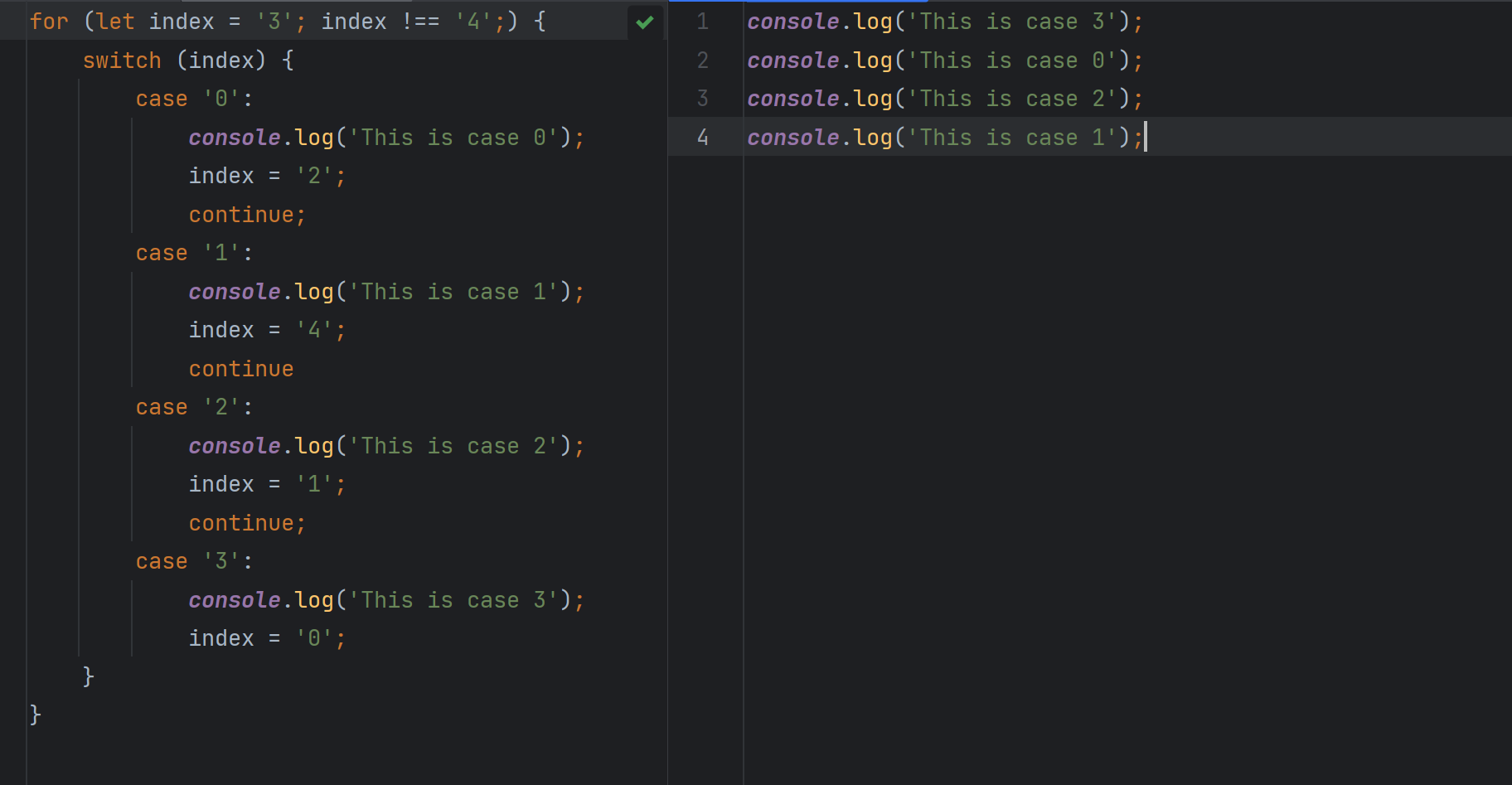
使用基本操作进行基本还原
实战我们以某验三代滑块最新fullpage.9.1.0.jshttps://static.geetest.com/static/js/fullpage.9.1.0.js为例进行实战还原。
观察JavaScript源码明显可见有常量unicode编码混淆,收缩代码观察JavaScript源代码主体,最后一个代码块为自执行函数,前五个代码块定义了一个zmSjO函数对象,之后往塞了里面四个方法 A i 、 _Ai、 Ai、_BE、、 C s 、 _Cs、 Cs、_DB,我们暂时不知道这个有啥用。展开最后一个自执行函数观察,发现一段大量重复的代码,截取一段如下:
var $_CBJHn = zmSjO.$_Cs
, $_CBJGy = ['$_CCAAe'].concat($_CBJHn)
, $_CBJIX = $_CBJGy[1];
$_CBJGy.shift();
var $_CBJJK = $_CBJGy[0];
zmSjO. C s 是在前五个代码块中塞入的方法,这段代码中 _Cs是在前五个代码块中塞入的方法,这段代码中 Cs是在前五个代码块中塞入的方法,这段代码中_CBJHn、 C B J I X 、 _CBJIX、 CBJIX、_CBJGy都等于zmSjO.$_Cs,在之后的代码中使用函数返回字符串来代替可见字符串也就是常说的ob混淆。虽然与基本操作中使用的示例有一定区别但是基本思路一致。
继续观察源代码,除此之外还存在基本操作中提到的for-switch类型平坦化,截取一段代码如下:
var $_DEFDa = zmSjO.$_DB()[2][4];
for (; $_DEFDa !== zmSjO.$_DB()[0][3];) {
switch ($_DEFDa) {
case zmSjO.$_DB()[2][4]:
this[$_DAHB(20)] = this[$_DAHB(905)]();
$_DEFDa = zmSjO.$_DB()[2][3];
break;
}
}
代码中定义的分发器 D E F D a 是从 z m S j O . _DEFDa是从zmSjO. DEFDa是从zmSjO._DB函数返回的大数组中取的值,case也是从zmSjO.$_DB函数返回的大数组中取的值作的索引,这种和我们基本操作中使用的示例有一定区别,case索引不在是顺序的1-9,但是还原思路一致。
还原代码如下:
const fs = require('fs')
const parser = require("@babel/parser");
const traverse = require("@babel/traverse").default;
const b_type = require("@babel/types");
const generator = require("@babel/generator").default;
const {decryptStr, decryptStrFnName, case_arrays} = require("./tools_fullpage9.1.0")
fs.readFile('resources/fullpage.9.1.0.js', "utf8", (err, input_js_code) => {
// 将JavaScript源代码转化为AST
let ast = parser.parse(input_js_code);
//对AST各个节点进行遍历,当遍历到visitor内声明的节点时,进入并执行。
traverse(ast, visitor)
// 将AST转化为JavaScript代码,jsescOption选项去除16进制和Unicode
let output_code = generator(ast, {minified: true, jsescOption: {minimal: true}}).code
fs.writeFileSync('resources/de_fullpage.9.1.0.js', output_code, {encoding: "utf-8"})
});
let fake_array = []
function affirm_ob_variable(path) {
let {kind, declarations} = path.node
fake_array = []
if (kind !== "var"
|| declarations[0].init === null
|| declarations[0].init.type !== "MemberExpression"
|| declarations[0].init.object.name !== "zmSjO"
|| declarations[0].init.property.name !== decryptStrFnName
) return
fake_array.push(declarations[0].id.name)
fake_array.push(declarations[1].id.name)
fake_array.push(declarations[2].id.name)
path.getFunctionParent().traverse(visitor_2)
path.getNextSibling().remove()
path.getNextSibling().remove()
path.remove()
}
function funToStr(path) {
let {callee, arguments} = path.node
if (fake_array.indexOf(callee.name) > -1) {
let replace_str = b_type.valueToNode(decryptStr(arguments[0].value))
path.replaceWith(replace_str)
}
}
function de_planarization(path) {
let {init, test, update, body} = path.node
// 判断for循环跳出特征
if (test.operator !== "!=="
|| test.right.type !== "MemberExpression"
|| test.right.object.type !== "MemberExpression"
|| test.right.object.object.type !== "CallExpression"
|| test.right.object.object.callee.object.name !== "zmSjO"
|| test.right.object.object.callee.property.name !== "$_DB"
) return;
// 用于替换for-switch节点的节点列表
let replace_node = []
// case分发器值和相应case代码段、下一步组成的字典
let case_map = {}
// 起始代码块索引
let before_code = path.getPrevSibling()
// 分发器特征判断
if (before_code.type !== "VariableDeclaration") return;
let {declarations, kind} = before_code.node
// 起始索引
let start_index = case_arrays[declarations[0].init.object.property.value] [declarations[0].init.property.value]
// 分发器名
let dispatcher_name = declarations[0].id.name
// 删除分发器初始化赋值代码
before_code.remove()
// 第一步执行的代码段
// 遍历 for内代码块
body.body.forEach(node => {
if (node.type === "SwitchStatement") {
// switch case分发器特征是否满足条件
if (node.discriminant.name !== dispatcher_name) return;
// 遍历case节点
node.cases.forEach(SwitchCase => {
// case对应的分发器值
let case_index = case_arrays[SwitchCase.test.object.property.value][SwitchCase.test.property.value]
let next_index;
// 如果该case最后一句为break则不需要记录下一步分发器的值
if (!b_type.isBreakStatement(SwitchCase.consequent[SwitchCase.consequent.length - 1])) {
SwitchCase.consequent.forEach(Statement => {
if (Statement.type === "ExpressionStatement") {
let {expression} = Statement
if (expression.type !== "AssignmentExpression"
|| expression.left.name !== dispatcher_name
) return
// 读取下一步分发器的值
next_index = case_arrays[expression.right.object.property.value][expression.right.property.value]
}
}
)
} else {
// 移出 最后一句break语句
SwitchCase.consequent.pop()
// 移出 倒数第二句break中无效的分发器赋值
if (b_type.isExpressionStatement(SwitchCase.consequent[SwitchCase.consequent.length - 1])) {
let consequent = SwitchCase.consequent[SwitchCase.consequent.length - 1]
if (consequent.expression.type === "AssignmentExpression"
|| consequent.expression.left.name === dispatcher_name
) {
SwitchCase.consequent.pop()
}
}
}
// 存入字典
case_map[case_index] = {
"consequent": SwitchCase.consequent,
'next_index': next_index
}
})
}
})
// 当start_index 为undefined时,结束循环
while (start_index) {
// 存在假代码,删除不执行的case
if (!case_map[start_index]) break
let consequent = case_map[start_index]["consequent"]
// 下一步执行顺序
start_index = case_map[start_index]["next_index"]
// 将节点数组合并 存入replace_node
replace_node = replace_node.concat(consequent)
}
// 批量替换
path.replaceWithMultiple(replace_node)
}
const visitor = {
VariableDeclaration: {enter: [affirm_ob_variable]},
ForStatement: {enter: [de_planarization]},
}
const visitor_2 = {
CallExpression: {
enter: [funToStr]
}
}
结尾
本文为入门科普向文章,还有很多有用的API和混淆没有提到,总归是常见的混淆都讲了一遍,足够我们对绝大多数JavaScript源代码混淆在一定程度上还原。AST还原JavaScript代码混淆并不困,但要还原出精简的JavaScript源代码还是需要大量的练习。
在web端逆向、还原过程中使用AST反混淆可以极大地提升我们的效率,但是更需要的是我们对JavaScript的熟悉、对JavaScript逆向还原的经验。
所有代码已经上传Github:https://github.com/luojunjunjun/article/tree/master/10min%20AST















 3513
3513











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









