







[AcWing]802. 区间和(C++实现)区间和模板题
1. 题目

2. 读题(需要重点注意的东西)
初步思路:
- x的范围在-10^9 到 10^9之间,而n,m 在1 到 10^5之间,有着值域大而数值稀疏的特性。是典型的离散化特征。
- 离散化是指将离散的数据,映射到下标为0,1,2,3,4,5…的数组中,然后通过一个函数,输入区间的左端点 l 和右端点 r ,得到映射后的下标 Kl 和 Kr,然后通过前缀和输出区间和 s[Kr] - s[Kl-1];

------------------------------------------------------代码实现思路-----------------------------------------------------------
- 读取数据{x,c}存放在add,将x存放在alls数组中;读取l,r存放在query,将l、r存放在alls数组中;
- 对alls数组进行排序和去重;
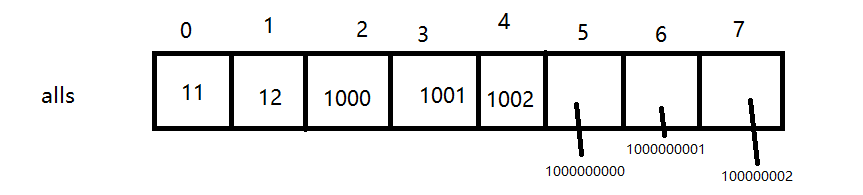
- 将离散数组中的数据依次加到a[ ]中;
- 由a[ ]得到前缀和数组s[ ];
- 对每一个询问对[l , r],用find函数找到Kl和Kr,输出s[Kr] - s[Kl - 1]。
3. 解法
注:
- a[N]:用于存放离散数据的值,即将原离散数组映射到数组a中
- s[N]:是 a[N] 的前缀和;
- vector< int > all:用于问题中原离散数组出现过的所有位置;
- vector< PII > add:用于存放一个数对{x, c},表示在离散数据原数组中的位置 x 处加上c;
- vector< PII > query:用于存放一个数对{l, r},表示一个询问对(题目要求返回 l 到 r 之间的区间和);
- find(int x)函数作用:输入一个映射前的位置x,得到映射后的位置;
- vector::iterator unique(vector &a)函数作用:对给定的vector去重。(iterator ,迭代器,详见 5. 所用到的数据结构与算法思想)
---------------------------------------------------解法---------------------------------------------------
#include <iostream>
#include <vector>
#include <algorithm>
using namespace std;
typedef pair<int, int> PII;
const int N = 300010;
int n, m;
int a[N], s[N];
vector<int> alls;
vector<PII> add, query;
int find(int x)
{
int l = 0, r = alls.size() - 1;
while (l < r)
{
int mid = l + r >> 1;
if (alls[mid] >= x) r = mid;
else l = mid + 1;
}
return r + 1;
}
C++中自带unique函数,如果没有,按以下方法构造该函数
vector<int>::iterator unique(vector<int> &a)
{
int j = 0;
for (int i = 0; i < a.size(); i ++ )
if (!i || a[i] != a[i - 1])
a[j ++ ] = a[i];
// a[0] ~ a[j - 1] 所有a中不重复的数
return a.begin() + j;
}
int main()
{
cin >> n >> m;
for (int i = 0; i < n; i ++ )
{
int x, c;
cin >> x >> c;
add.push_back({x, c});
alls.push_back(x);
}
for (int i = 0; i < m; i ++ )
{
int l, r;
cin >> l >> r;
query.push_back({l, r});
alls.push_back(l);
alls.push_back(r);
}
// 去重
sort(alls.begin(), alls.end());
alls.erase(unique(alls), alls.end());
// 处理插入
for (auto item : add)
{
int x = find(item.first);
a[x] += item.second;
}
// 预处理前缀和
for (int i = 1; i <= alls.size(); i ++ ) s[i] = s[i - 1] + a[i];
// 处理询问
for (auto item : query)
{
int l = find(item.first), r = find(item.second);
cout << s[r] - s[l - 1] << endl;
}
return 0;
}
此外,一些可能的疑问
- 为什么要对all数组排序?
由于unique函数实际上是删除序列中所有相邻的重复元素(只保留一个)。但是此处的删除,并不是真的删除,而是指重复元素的位置被不重复的元素给占领了。由于它”删除”的是相邻的重复元素,所以在使用unique函数之前,一般都会将目标序列进行排序。 - 为什么要对all数组去重?
因为all数组存放的是原离散数据出现的位置,一个数据对应的位置只有一个。 - alls.erase(unique(alls), alls.end());
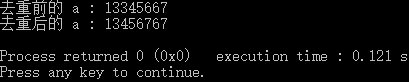
图片来源于C++STL中的unique函数解析
可以看到,容器中不重复的元素都移到了前面,至于后面的元素,实际上并没有改变。因此unique函数通常和erase函数一起使用,来达到删除重复元素的目的。erase函数的删除是真正的删除,即从容器中去除重复的元素,容器的长度也发生了变换;而单纯的使用unique函数的话,容器的长度并没有发生变化,只是元素的位置发生了变化。
注意:unique函数返回的是指向去重后数组的尾端点的迭代器。
4. 可能有帮助的前置习题
5. 所用到的数据结构与算法思想
6. 总结
本题使用了离散化、前缀和、二分的思想。在数据结构方面使用了vector、pair等数据结构,是一道比较综合的离散化模板题。
















 794
794











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











